
Examples of extending Dynamics 365 Customer Insights with Azure ML
Dynamics 365 Customer Insights offers a platform to integrate customer data from various sources into one unified view. This unified data presents a perfect starting point for building custom machine learning (ML) models to generate key business metrics. In an earlier blog, we saw how to bring custom ML models from Azure Machine Learning (AML) Studio to work with the unified data from Customer Insights. To accelerate the initial model development, we offer AML Studio–based model pipelines for three frequently encountered use cases:
- Churn analysis
- Customer lifetime value (CLTV) prediction
- Product recommendations
We will go over these models in more detail in this blog.
Hotel Scenario
We will use the Contoso Hotel scenario for the models discussed in this article. At the Contoso Hotel, CRM data is gathered and consists of hotel stay activity. In this data, the information about the dates of stay are logged for each registered customer. Along with this, the data also contains information about the booking, room types, details of spend, etc. The data spans about four years from January 2014 to January 2018.
The second set of data is from customer profiles. These profiles contain personal information for each customer since they are registered with the hotel or since their first stay. This information includes name, birth date, postal address, gender, phone number, etc.
The third set of data includes use of other services offered by the hotel. For example, the use of spa, laundry services, WiFi, courier, etc. This information is also logged for each registered customer. Typical use of services is linked with the stay, but it is not required; in some cases, the services can be used by customers without actually staying in the hotel.
Churn Analysis
Churn analysis can be performed in different situations (e.g., retail churn, subscription churn, service churn, etc.). In this example, we’re going to look at service churn, specifically in the context of hotel services as described above. Although it may not cover all of the scenarios explicitly, the model will provide insights into all the steps in building a custom model using Azure ML and Customer Insights. It will also provide a working example of an end–to–end model pipeline that can be used as a starting point for any other type of churn model.
Definition of Churn
The definition of churn can differ significantly based on the scenario. In this case of hotel activity, our definition is if a customer has not visited the hotel in the past year, s/he should be labeled as churned.
As described in our previous blog, the AML Studio experiment can be imported from the gallery. Below is a screenshot of the import blocks that read these tables from the Azure blob storage location.

Featurization
Based on the definition of churn, we first identify the raw features that will have some causal effect or impact on the label. Then, we further process these raw features into numerical features that can be used with ML models. Data integration happens in Customer Insights so as a result, joining these tables can be done by simply using the “Customer ID” created by Customer Insights.
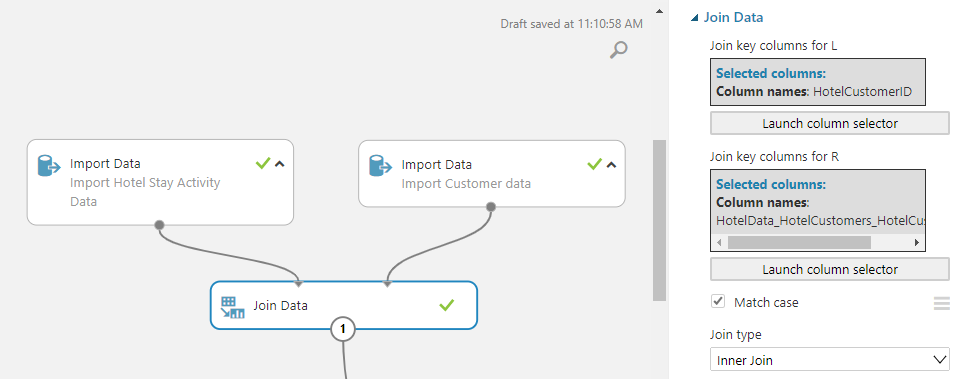
The featurization for building the model for churn analysis can be a little tricky. The problem is typically cast as a static problem like image classification; however, the underlying data is not static like a set of images. The data is a function of time with new hotel activity recorded on daily basis. Hence, featurization should take this into consideration and generate static features from the dynamic data. In this case, we generate multiple features from hotel activity with a sliding window of one year. We also expand the categorical features like room type, booking type, etc. into separate features using the technique of one-hot encoding.
The final list of features is shown below:
| Number | Original_Column | Derived Features |
| 1 | Room Type | RoomTypeLargeCount, RoomTypeSmallCount |
| 2 | Booking Type | BookingTypeOnlineCount, BookingTypePhoneCallCount |
| 3 | Travel Category | TravelCategoryBusinessCount, TravelCategoryLeisureCount |
| 4 | Dollars Spent | TotalDollarSpent |
| 5 | Check-in and Checkout dates | StayDayCount, StayDayCount2016, StayDayCount2015, StayDayCount2014, StayCount, StayCount2016. StayCount2015, StayCount2014 |
| 6 | Service Usage | UsageTenure, ConciergeUsage, CourierUsage, DryCleaningUsage, GymUsage, PhoneUsage, RestaurantUsage, SpaUsage, TelevisionUsage, WifiUsage |
Model selection
Once the feature set is ready, the next step is to choose the optimal algorithm to use. In this case, we have majority of features coming out of categorical features. Typically, in such situations, decision tree–based models perform well. In case of purely numerical features, neural networks could be a better choice. Support vector machine (SVM) also is a good candidate in such situations; however, it needs quite a bit of tuning to extract the best performance. We choose “gradient boosted decision tree” as the first model of choice followed by SVM as the second model. AML Studio lets you perform A/B testing of two models to compare and contrast. To make better use of this, it’s always beneficial to start with two models rather than one.
The following image shows the model training and evaluation pipeline from AML Studio.
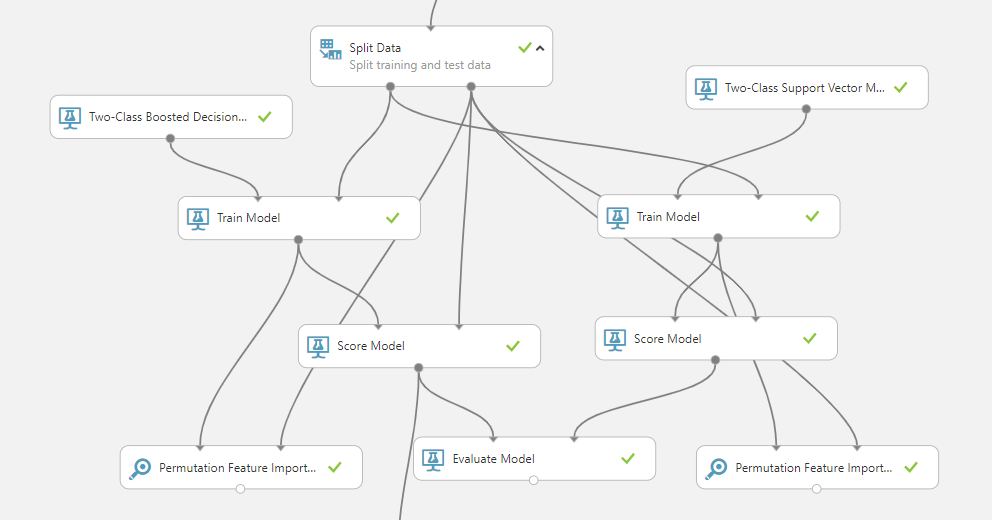
We also apply a technique called “Permutation Feature Importance.” This is a crucial aspect of model optimization. All of the built-in models present a black box model with little to no insight into the impact of any specific feature on the final prediction. The feature importance calculator uses a custom algorithm to compute the influence of individual features on the final outcome for a specific model. The feature importances are normalized between +1 to -1. The negative influences essentially mean that the corresponding features have counter intuitive influence on the outcome and should be removed from the model. Higher positive influence indicates that the feature is contributing heavily towards the prediction. These values should not be confused with correlation coefficients as they are completely different metrics. For more details, see Permutation Feature Importance.
Completing the integration with Customer Insights
Once the training experiment is complete and the resulting metrics are acceptable, we can create a predictive service as described in the previous blog. Make sure the predictions are accompanied with the customer IDs from Customer Insights. After that the predictions can be exported to the same blob storage and ingested back into Customer Insights.
The entire churn experiment is available in the Azure ML gallery.
Customer lifetime value (CLTV) prediction
The customer lifetime value (CLTV) calculation is one of the key metrics that a business can use to assess and segment its customers. For the hotel business, it is critical to know their customers. For instance, understanding the difference between customers that bring more value versus the customers that don’t can provide crucial information to hotel management. This type of segmentation can help hotel management assess which features they need to focus on and improve to satisfy their high paying customers against features that are less important. These decisions can have a direct impact on sales and earnings. In this example, we will define the CLTV as the cumulative amount brought in by the customer in the designated time frame.
Definition of CLTV
In this context we are going to define the CLTV of a customer as of today, as the total dollar amount the customer is expected to spend in the next 365 days or 1 calendar year. We are going to use the past three years’ worth of data for all customers to predict this value.
Featurization
In this case, featurization is going to be quite similar to the churn scenario; however, the label and predicted values are different than defined above.
Model selection and training
Predicting the CLTV is a regression problem as the predicted value is a positive valued continuous variable. Based on the feature properties, we select Boosted Decision Tree Regression as one algorithm and Neural Network Regression as another algorithm to train the model.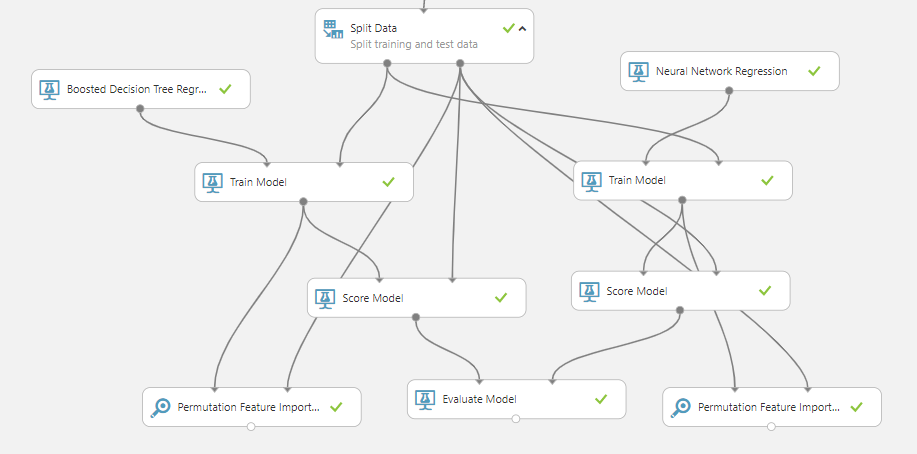
Completing the integration with Customer Insights
As described in the churn model, the output of the CLTV model is tied with Customer IDs and ingested back into Customer Insights for further analysis.
The entire CLTV experiment is available in the Azure ML gallery.
Product recommendation or Next Best Action
Product recommendation in the context of the hotel scenario is interpreted as recommending services offered by the hotel to the customers. The objective is to choose the appropriate services for customers so that their usage is maximized. The problem is similar to the problem of movie recommendations for video streaming service users.
Definition of Product Recommendation or Next Best Action
We define the goal as maximizing the dollar amount of service usages by offering the best matching services to hotel customers according to their interest.
Featurization and Training
Similar to the churn model, we are joining the hotel ServiceCustomerID with CustomerID in order to build recommendations consistently per CustomerID.
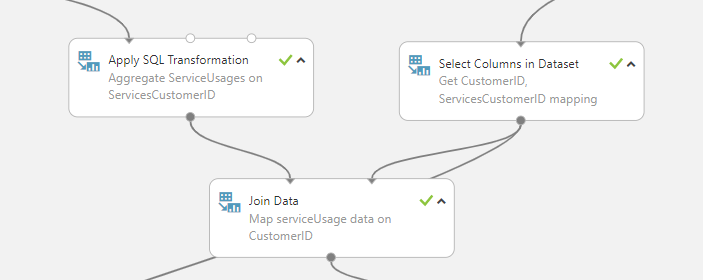
As described in the beginning, the data is sourced from three different entities and features are derived from them. The featurization for the problem of recommendation is different compared to churn or CLTV scenarios. The recommendation model needs input data in the form of three sets of features. One set of features represents the past usage of services by the customers, and the second set represents the details of each service itself and the third set represents the details of the customers.
We use the algorithm called Matchbox Recommender to train the recommendation model.
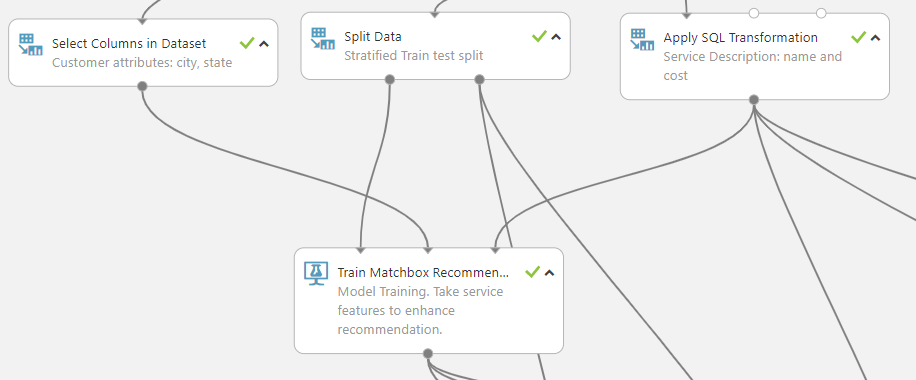
From the figure above, the three input ports for the Train Matchbox Recommender model takes in the training service usage data, customer description (optional), and service description. There are three different ways of scoring the model. One is for model evaluation where an NDCG score is computed to evaluate the rated items rank. In this experiment, we have NDCG score as 0.97. The other two options are scoring the model on the entire recommendable service catalog or scoring only on items that users have not used before depending on the business requirement.
Looking further on the distributions of the recommendations on the entire service catalog, we notice that phone, WiFi, and courier are the top services to be recommended. This is consistent with what we found from the distributions of the service consumption data:
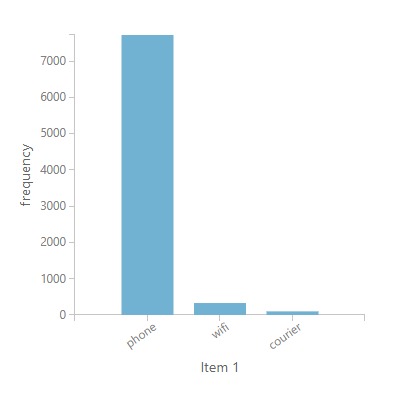
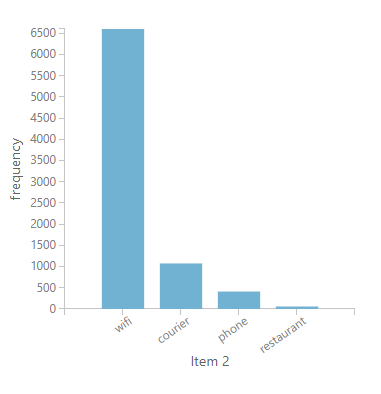
The entire product recommendation experiment can be accessed in Azure ML gallery.
More information
Read our Team blog to stay up-to-date with the latest features and ongoing innovation.
Engage with us on our Community site and provide ideas and feedback on the product.


