
Importing Data in CRM 4.0 Made Easier
Let me guess, either you are looking to learn ‘how to import data’ or you are stuck with some issues while importing data. If one of these is the case, then you are at the right place. Importing data into CRM was never this easier. It would be good if I walk you through some scenarios so that you can utilize this blog effectively.
1) You want to import data file to create records in bulk
a. Your have full control over the what column names you can have in the data file.
b. You do not have control over what column names can be there in data file
2) You want to use import to update records in bulk. For this pls look at http://blogs.msdn.com/crm/archive/2008/01/25/data-manipulation-tool.aspx.
Scenario 1
Wow, if you have control over column names in the data file, your job has just become very easy. You just need to put column names in the data file same as display names of attributes, and rest will be taken care by system. Let’s go through one example, and everything will be clear.
My example CSV file contains Contacts. File content looks like –
First Name, Last Name, Parent Customer
Manbhawan, Prasad, Microsoft CRM
Arun, Kumar, Microsoft GP
Note that column headings match exactly with the attribute display names of Contacts.
One other very important point is there to note that Parent Customer is reference type of field in CRM. In CRM, this contains GUID of either another account or contact. In this file, I am giving values as “Microsoft CRM” and “Microsoft GP”. Here system is going to do the hard job of finding right account or contact for this reference. You just need to have value of either primary attribute of target column or GUID. In this example, I already have accounts with name as “Microsoft CRM” and “Microsoft GP” to which I want these contacts to be attached.
When system sees a reference field, it picks up the value and searches for target entity record which has this value either as GUID or Primary Attribute. In this case, it will search for Accounts with GUID or Account Name as “Microsoft CRM”. It will also search for contacts with GUID or Last Name as “Microsoft CRM”. If it is able to find single record, then it will link or else will fail the row.
Launch MSCRM and On the Tools menu, click Import Data.

Choose the data file and delimiters if they are different from default. In this example, I do not need to change the delimiter as my field delimiter is ‘,’ and I do not have data delimiter as none of my data contains field delimiter inside the data. So I go with the default. Click on next.
Choose the record type as contact.

In the data map field, Automatic will be displayed. Here system has mapped all the columns for you automatically, because your column names were same as attributes display names.
Click on next and you are presented with the screen below. Here you can do two things –
1) By default all the records will get assigned to you. But here you can choose to assign these to some other CRM user.
2) You can also choose not to create duplicate records. Duplicate records are identified based upon the published duplicate rules in the CRM System. For more details about how duplicate detection works, you can refer to http://blogs.msdn.com/crm/archive/2008/01/21/duplicate-detection-while-creating-updating-records-in-titan.aspx.
After performing these steps, click next.

On the last screen, you can choose to change the name of the import, which will be surfaced in the grid. Or you can live with default name given by the system. You can also choose to receive an email when Import gets completed.
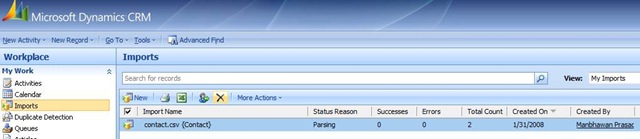
You can see the status of the Import by going to workplace->Imports. Below is the screen shot. This import will go through Parsing, Transforming, Importing and then it will be completed. You can click on this import entity to see more details about successful creation and also failures.
Scenario 2
If you get a data file which has column names not matching with attribute names. In this case, you will have first map these columns to the CRM attributes, and then proceed with the Import.
Let’s take an example file with content as –
FirstName, LastName
Manbhawan, Prasad
Arun, Kumar
Here are the steps to import it
1) Prepare a Data Map. Data map contains information about which column maps to which attribute in CRM.
2) Import the data using that map
We will start with preparing data map. Go to settings->Data Management-> Data Maps
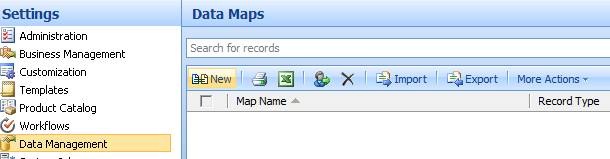
Click on new and screen below appears. Enter a name of the map. Choose the entity name for which map is being prepared. In this case, it should be contact.

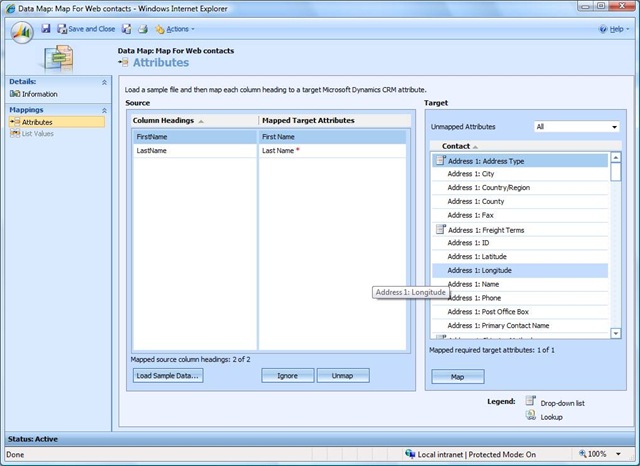
Click on Attributes and screen changes as below. Load the sample data which contains all the column names and unique values if you have picklist columns also. In this example I am loading the data file we started with. Loading sample data file populates the column headings grid and you can map each of these with target attributes of contacts. If you map some column to picklist type attribute, then list values will be enabled and will allow to map different picklist values. In this case we do not have any picklist values.
After mapping all columns, save and exit.
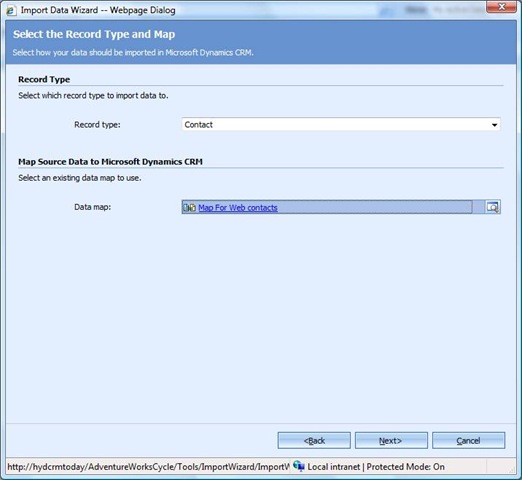
Now start the import as we did in the first scenario, choose the record type and choose the map which we made just now (shown below). Complete the wizard, and you are done.
What can go wrong
1) MSCRM Asynchronous service might not be running on server.
2) Mandatory columns for the entity might be missing in the data file (This will be shown as the error, warning on the “Select Record Type and Map” screen.
3) Reference column might contain values which does not correspond to any target entity records OR corresponds to more than one target entity records. Pls note that reference resolution happens either on GUID or Primary attribute of the target entity.
4) Reference resolution works only with automatic mapping and not when you are providing data map. If you are using your own data map, then your data file should have GUID to have it resolved properly.
5) Data delimiter and field delimiter might not be correct in the data file.
6) If duplicates are getting created, then you might not have the published duplicate rules for this entity.


