
Data Migration Manager: Advanced Transformation Mappings
Today I will talk about what are advanced transformation mappings and how are they used while migrating data into Microsoft CRM using the Data Migration Manager. As we all know, Microsoft CRM Data Migration Manager comes as an easy to use tool for migrating your data to Microsoft CRM from varied CRM systems. It works on the basis of data maps that are used to define a mapping between the source data schema and Microsoft CRM data schema.
A data map is nothing but an xml file structured out of a few entities used for data mapping during data migration in Microsoft CRM. The data map is the soul of any data migration being carried out using the Data Migration Manager. It primarily defines where in Microsoft CRM, the source data should go and also how it should be transformed to go there. Apart from direct 1 to 1 mapping, it allows us to define a variety of transformations like reference, list value, advanced, owner transformations. Although the Data Migration Manager does not provide a complete UI support for creation/editing of mappings, the ability to consume such a map makes the tool really powerful. For more details on data map, please refer to Data Migration: Fundamentals on Data Map.
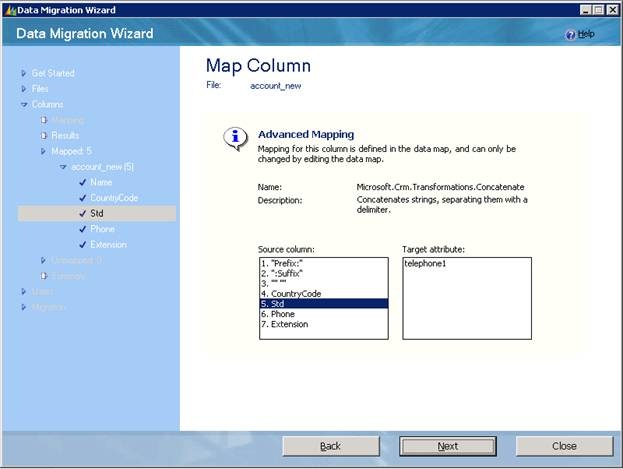
Fig 1: Microsoft Data Migration Manager does not allow create/edit of advanced transformation mappings.
The support for advanced transformation mapping consists of a few advanced transformations that can be used to massage the data before pushing it into Microsoft CRM. These transformations provide support for 1:1, 1:N, N:1, M:N mapping. An advanced transformation is like a function that applies to a set of inputs to generate a set of outputs. The inputs to these functions can come from either the source data or some constant value. However, the outputs are destined to go to Microsoft CRM data fields.
Let us spend some time understanding the xml structure for an advanced transformation mapping. Let’s say I have a source file called MyAccount1.csv whose data I want to migrate to Microsoft CRM’s account entity.

Now I want to take this information and shove it into account entity in Microsoft CRM. We can easily map the AccountName column to the account entity’s accountname attribute using an attribute mapping. But there is no direct mapping between the other fields. As we can see, the source file has the phone number as three separate fields whereas in Microsoft CRM’s account entity the main phone is just one field. This calls for either editing the csv file beforehand or use advanced transformation mapping to do it at runtime. Let us see how we can use the latter approach.

Here’s what we would like to do:
CountyCode + AreaCode + PhoneNumber account.telephone1
In order to achieve this behavior, we may use the Concatenation advanced transformation. Here’s how the pseudo signature of the advanced transformation’s looks like:
string Concatenation(string prefix, string suffix, string delimiter, string[] inputStrings)
Note that the fourth input parameter is an array to accommodate variable number of input values. Let us assume that we don’t have to add any prefix or suffix to the concatenated string and want to supply a constant value for delimiter. The values for the inputStrings array parameter should come from the source file and the output should be assigned to a CRM field called accountname. Here’s how the mapping will look like:
1: <xml version="1.0" encoding="utf-8">
2: <Map Name="My Map" Source="My Source">
3: <Description />
4: <EntityMaps>
5: <EntityMap TargetEntityName="account" SourceEntityName="MyAccount1">
6: <TransformationMaps>
7: <TransformationMap>
8: <TransformationTypeName>Microsoft.Crm.Transformations.Concatenate</TransformationTypeName>
9: <ProcessCode>Process</ProcessCode>
10: <InputParameterMaps>
11: <SingletonInputParameterMaps>
12: <SingletonInputParameterMap>
13: <ParameterSequence>3</ParameterSequence>
14: <DataTypeCode>Value</DataTypeCode>
15: <Data>” “</Data>
16: </SingletonInputParameterMap>
17: </SingletonInputParameterMaps>
18: <ArrayInputParameterMaps>
19: <ArrayInputParameterMap>
20: <ParameterSequence>4</ParameterSequence>
21: <Items>
22: <Item>
23: <ParameterArrayIndex>0</ParameterArrayIndex>
24: <DataTypeCode>Reference</DataTypeCode>
25: <Data>CountryCode</Data>
26: </Item>
27: <Item>
28: <ParameterArrayIndex>1</ParameterArrayIndex>
29: <DataTypeCode>Reference</DataTypeCode>
30: <Data>AreaCode</Data>
31: </Item>
32: <Item>
33: <ParameterArrayIndex>2</ParameterArrayIndex>
34: <DataTypeCode>Reference</DataTypeCode>
35: <Data>PhoneNumber</Data>
36: </Item>
37: </Items>
38: </ArrayInputParameterMap>
39: </ArrayInputParameterMaps>
40: </InputParameterMaps>
41: <OutputParameterMaps>
42: <OutputParameterMap>
43: <ParameterSequence>1</ParameterSequence>
44: <Data>telephone1</Data>
45: </OutputParameterMap>
46: </OutputParameterMaps>
47: </TransformationMap>
48: </TransformationMaps>
49: </EntityMap>
50: </EntityMaps>
51: </Map>
Note: Omitting parameter mapping for parameter 1 (prefix) and 2 (suffix) will result in sending null values to those parameters during evaluation.
As we can see the input parameter mapping is broken down into two types of mappings, namely, SingletonInputParameterMaps and ArrayInputParemeterMaps depending upon whether we are mapping to a singleton input parameter or an array input parameter respectively. A SingletonInputParameterMap consists of three nodes namely the ParameterSequence node, the DataTypeCode node, and the Data node. The ParameterSequence node helps identify the parameter number for which the mapping is, whereas the DataTypeCode defines whether the parameter value is coming as a constant value or is coming from a source file column. As an analogy, you can think of it as pass by value (Value) or pass by reference (Reference). In case of Value, the value in node Data is used as is whereas in case of Reference, the value in node Data is used to identify a column name in the source file.
An ArrayInputParemeterMap is defined just like a SingletonInputParameterMap except the fact that we have multiple values to map to the same parameter. We achieve this by mapping a collection of items to a parameter and the ordering of this collection is controlled by ParameterArrayIndex node. Note that the parameter numbers start from 1 whereas the array index, which is used for mapping an array item, starts from zero.
In case of output parameter mappings, we map the output parameter with a field in Microsoft CRM. Again, the parameter sequence number identifies which output parameter this mapping applies to, in case there is more than one output (returned in the form of an array).
Note that all the Microsoft CRM object names like entity names, field names are case sensitive.
Another very powerful feature is the support for reference transformations on the outputs of advanced transformations. In other words, if we have an output value coming as a result of an advanced transformation that is mapped to a reference field in Microsoft CRM, then we can also define reference mapping on this output value to resolve the reference. Let us take an example to understand this better. Let’s say we need to migrate a file called MyAccount2.csv which looks something like this:

Here the ParentContact column is a reference to a Contact whose first name is Ben and last name is Fleming. Now, if we want the value of the column ParentContact to go into parentcontactid field of account entity in Microsoft CRM, we cannot just define a reference mapping on the column ParentContact. The reason being that Microsoft CRM contact entity does not have a fullname attribute. The contact entity’s full name attribute is a logical, aggregate attribute and reference resolution does not work on logical fields. Since Microsoft CRM’s contact entity does not have a field called fullname, we will not be able to resolve this reference directly. In order to get this to work, we will have to somehow break the ParentContact column into two columns namely, FirstName and LastName. Then we can resolve the lookup using either of the two, say FirstName.
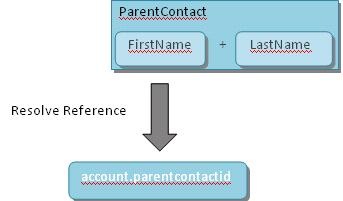
To solve such problems, the advance transformations provide support for reference resolutions based on its outputs. So, here we will apply an advance transformation called Split on the ParentContact column and will use the first output to resolve the reference with Microsoft CRM’s contact entity’s firstname field. Let us see how the advanced transformation mapping will look like.
1: <EntityMap TargetEntityName="account" SourceEntityName="MyAccount2">
2: <TransformationMaps>
3: <TransformationMap>
4: <TransformationTypeName>Microsoft.Crm.Transformations.Split</TransformationTypeName>
5: <ProcessCode>Process</ProcessCode>
6: <InputParameterMaps>
7: <SingletonInputParameterMaps>
8: <SingletonInputParameterMap>
9: <ParameterSequence>1</ParameterSequence>
10: <DataTypeCode>Reference</DataTypeCode>
11: <Data>ParentContact</Data>
12: </SingletonInputParameterMap>
13: <SingletonInputParameterMap>
14: <ParameterSequence>2</ParameterSequence>
15: <DataTypeCode>Value</DataTypeCode>
16: <Data>” “</Data>
17: </SingletonInputParameterMap>
18: </SingletonInputParameterMaps>
19: </InputParameterMaps>
20: <OutputParameterMaps>
21: <OutputParameterMap>
22: <ParameterSequence>1</ParameterSequence>
23: <Data>parentcontactid</Data>
24: <LookupMaps>
25: <LookupMap>
26: <LookupEntityName>contact</LookupEntityName>
27: <LookupAttributeName>firstname</LookupAttributeName>
28: <LookupType>System</LookupType>
29: <ProcessCode>Process</ProcessCode>
30: </LookupMap>
31: </LookupMaps>
32: </OutputParameterMap>
33: </OutputParameterMaps>
34: </TransformationMap>
35: </TransformationMaps>
36: </EntityMap>
Note: Delimiter in parameter 2 is supplied as “ “ which means just the space. The quotes are removed when the value is processed. This is done to avoid any truncation that may happen during serialization/deserialization.
As can be seen from the example above, the first output of the advance transformation is used to resolve the reference and the resolved value is fed into the parentcontactid field of account entity. This might have given you an insight on how powerful advance transformations are and that advanced transformation mappings give us a lot more control and power to manipulate the data before it gets into Microsoft CRM without having to change the source data in source files. There will be a blog on the usage and utility of all the available advanced transformations soon. So stay tuned!
Cheers,


