
Microsoft Dynamics NAV: Faster than ever.
First, let me start by saying that based on the evidence so far: It is. Significantly.
A number of the changes to the Dynamics NAV 2013 architecture contribute to the performance boosts that many of the test have shown. To outline some of the changes:
- Middle tier is 64 bit
- We are no longer using cursors but MARS
- Ability to auto-update sift fields when looping, rather than repeating the process for each call. SETAUTOCALCFIELDS reduces the amount of statements issued
- Pages containing flowfields now issue ‘SmartSQL’ queries, basically one source table query with outer joins for each flowfield query, again reducing the ‘chattiness’
and calculating sift values in one server roundtrip - Global cache
- REPEATABLEREAD is default isolation level
- Locking changes in posting routines, locking at later point and reducing overall blocking time
… and more.
However(!), a few things have surfaced in the course of time that are not as explicitely documented as the changes above, nor as apparent, and might have unexpected side effects. I have collected some of the side effects that you might or not be aware of and that might leave you panicking if not certain what you’re facing.
- Pages (with FlowFields) will in general run faster on Dynamics NAV 2013 than on NAV 2009 due to SmartSQL queries and reduced chattiness. Flow Fields on a page (all of them) are calculated in one go, which greatly reduces number of statements issued. But SmartSQL queries are not cached. Also, since we changed to MARS, SQL seems to be more sensitive to an index’s column cardinality then before. You might experience that (depending on various factors) some queries that have run fine in the past now take much longer, this is due to a poor execution plan on SQL. With Dynamic cursors, query plan optimizer tended to optimize for the ORDER BY, while with MARS, SQL is free to choose. It does a good job at it too, but in rare occasions might chose poorly. These cases are exceptions and contrary to the popular belief, this is not caused by the SmartSQL queries. These queries will have same poor execution plan and perform poorly even when isolated from the SmartsSQL query.
Consider the following example. This is just an illustration of the problem, constructed on CRONUS extended database:
A lot of Inventory transactions are posted through the Item Journal, generating a lot of Post cost to the G/L Entry. After this, when browsing an item list and opening an Item card, the page opens very slowly.
After locating the offending query in the SQL profiler and running it isolated in Microsoft SQL Server Management Studio with ‘Include Actual Execution Plan’ option enabled, the plan looks similar to the one shown below:
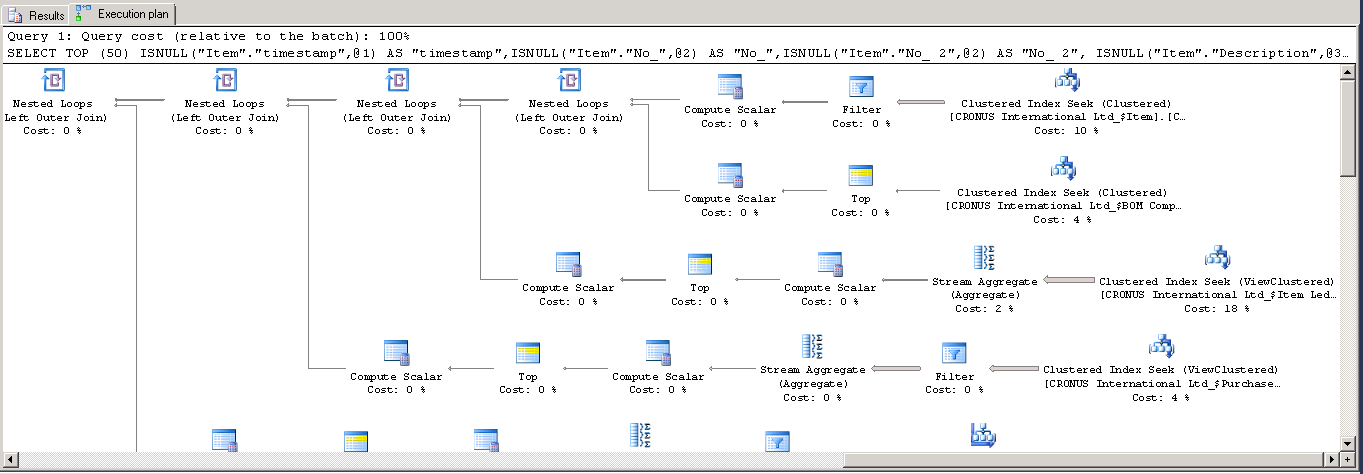
Each sub-query shows reasonably (small) percentage of cost and no apparent reason for bad execution plan. There are no obvious extreme costs, however there is a Clustered Index Scan here:

Looking at the filter that SQL Server applies, namely it filters on “Post Value Entry to G_L”. “Item_No_” = “Item”.”No_”:
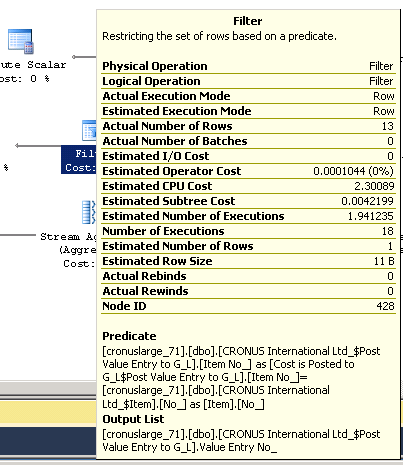
Although SQL Server reports Operator Cost as small, it shows CPU Cost in excess of 2.3 in approx. 1.94 executions. So, it is likely scanning the table twice and unfortunately the table has 4,7 million rows.
Although it is not obvious from the actual SQL Server execution plan that this is a problem, profiling with the SQL Server Profiler reports the query to use more than 5 seconds of CPU, while doing 131.519 reads to fetch 52 rows:

The reason the Duration is on par with CPU Seconds is that all reads are logical from SQL Server Buffers. Re-issuing the query after adding the supporting index shows this in SQL Server Profiler:

So Reads were reduced by a factor of 100 and (warm) duration was reduced by a factor of 40.
As you can see, these poor execution plans are not caused by the SmartSQL. However the fact that the SmartSQL queries don’t cache their results will only amplify the issue. To solve it, we have to tackle the performance of that one isolated query by creating a covering index to improve the execution plan.
And no, it won’t help to merely customize the page or change the visibility of the field. As long as it is contained in page metadata (so unless removed from page altogether), it will be calculated.
So in short, if you do run into an issue of rather dramatic slowness of a page containing flowfields in Dynamics NAV 2013 or higher, isolating and testing the Flow Field queries separately (focusing on ones with clustered index scan, regardless of cost) should lead you to the culprit fairly quickly. A supporting index should resolve the problem.
-
Temp tables: These are now moved to .NET. When you create a Temp record, your private C# TempTableDataProvider object is created. It will store whatever records you insert into a C# Dictionary, with the Primary Key Fields as the key for the Dictionary. The Dictionary is in memory and stores records in the order they
are inserted. When you add a SetCurrentKey, an AVLTree is built on the fly at first FindXX() you perform with that (current) key. In terms of performance, this is an expensive operation. This tree is in memory however, so it will be cached and reused later. If you issue a query without calling SetCurrentKey, an AVLTree for the primary key will be used.
However, maintaining all this can consume quite a lot of memory on your middle tier, so plan for ample memory when scaling. Also, as mentioned above, querying temp tables is cached but sorting them is a fairly expensive operation, just something to keep in mind.
- The next one is not strictly a performance issue, but can have a fairly drastic performance side-effect if you’re affected by it, so deserves to be mentioned:
You might (or might not) be aware that the transaction scope and behavior of a page action has changed in Microsoft Dynamics NAV 2013 and higher. This will be especially significant if you are calling functions in codeunits (or objects other than the source table), passing the REC as a parameter and intend to lock the record in that function.
Consider the following example: You have added an action that invokes a function in a codeunit, that in turn locks/ modifies the record (typically calling custom posting routine)
So OnAction trigger code is, for example, as follows:
PostingFunction(Rec);
Where PostingFunction is a function (in any object other than the source table).
Now, the consequence of the previously mentioned transaction scope change and the fact that you’re locking the record in the function, is that the entire source table (Rec) you passed as a parameter in the example above, is locked. In other words, you’re passing the current record as a parameter, but you are locking the whole table. The behavior would cause more damage than good to change at this point due to all functionality it would affect, so it won’t be changed, but fortunately – if
you’re aware of this issue, the solution is very simple:
SETSELECTINOFILTER(Rec); //adding this line
PostingFunction(Rec);
Adding the line above should reduce the scope of locking and leave you with locking just the one record (or selection of records if on a list). This applies to card pages as well.
- Last, but not least: you might have noticed increased Async_Network_IO waits. These cause quite a lot of concern out there. However, this is a symptom and not a problem per se.
When Dynamics NAV issues a query that returns thousands of rows, SQL Server will start a work thread to return the result. If the application does not consume the rows as fast as they are delivered from SQL Server then the SQL Server work thread will have to wait and that shows up as wait type Network_Async_IO. If the application never consumes the entire result set then the worker thread will be hanging until the transaction is ended (when we close the statement), or if it was a read transaction, for a longer period either until the connection is closed (as idle) or if the statement is overwritten by another statement (statement cache is full).
Example: when we do a FINDSET, a number of records (50, 100…) is retrieved. If it is a larger set it will run until all records are retrieved (or buffer is full), even if only first 10 are actually read by application. Eventually the session goes to sleep and after transaction ends sleeping sessions are removed. So in short, these are merely reflecting NAV data access methods, and are not a problem as such. If you want to reduce these, make sure you’re reading all the rows you’re asking for when using FINDSET, otherwise use FIND(‘-‘) or FIND(‘+’).
With thanks to Jesper Falkebo and Jens Klarskov Jensen
Jasminka Thunes
Microsoft CSS
These postings are provided “AS IS” with no
warranties and confer no rights. You assume all risk for your use.


