
Data Management Import Performance Issue with Cursor Fetch
I recently have a data import slowness issue reported taking days to process without finishing even in batch run in parallel. This issue could occur with any entity import especially for new company go-living or with no data in the target entity. The impact is exponentially worse when more data is imported, so I would like to share finding and possible solutions to the community.
The SQL statement with performance hit is emitted by Classes\DmfEntityWriter\processRecords() from the following call stack with the SQL pattern further in below.
QueryRun.next()
DmfEntityWriter.processRecords()
DmfEntityWriter.write()
DMFEntityWriterTasks.executeWrite()
DMFEntityWriterTasks.run()
BatchRun.runJobStaticCode()
Select …
from [Staging table]
Left outer join [Entity view]
…
WHERE ((T1.PARTITION=XXXXXXXXXX) AND (((T1.DEFINITIONGROUP=XXX) AND (T1.EXECUTIONID=XXX)) AND ((T1.RECID>=XXX) AND (T1.RECID<=XXX))
…
ORDER BY T1.RECID
The challenging part is that this SQL statement executes fast that could be easily missed in AX trace or SQL profiler trace. The part with performance hit is the cursor fetch though that surfaces after a while when staging to target stage import starts, and keep growing at alerting alarm if you query the SQL query statistics DMV. The characteristics is that the SQL text recorded is FETCH API_CURSORXXXXXXXX with alerting growing high logical read but very low execution count. The elapsed time in aggregate are typically the highest like sample in below.
Select top 10 qs.total_elapsed_time /1000.0 as [total_elapsed_time_ms], qs.execution_count, (qs.total_elapsed_time/qs.execution_count)/1000.0 as [avg_elapsed_time_ms], qs.max_elapsed_time / 1000.0 as [max_elapsed_time_ms], qs.min_elapsed_time / 1000.0 as [min_elapsed_time_ms],
qs.total_logical_reads, qs.total_logical_reads/execution_count as [avg_logical_reads], qs.max_logical_reads, qs.min_logical_reads, st.text as Sql_text
FROM sys.dm_exec_query_stats AS qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) AS st
ORDER BY qs.total_elapsed_time DESC

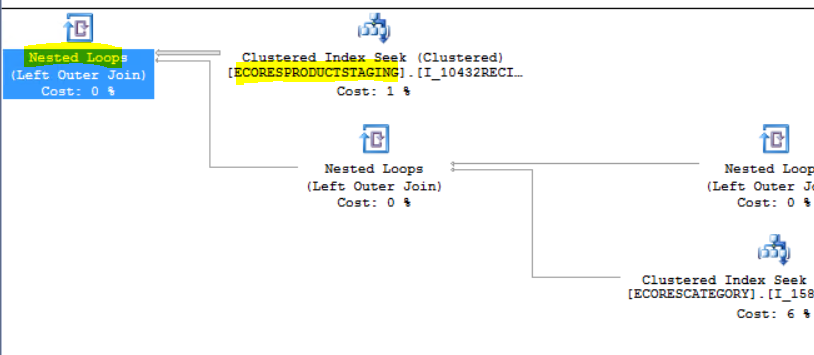
The DmfEntityWriter.processRecords() executes this SQL statement in select-while loop which queries all related records from the staging table to insert into the target entity. Therefore, each time the loop runs, the target table is going to have more record added or updated until the loop finishes. The performance hit is from cursor fetch growing exponentially to the power of target entity record based on # of record with RecId range in staging table assigned to the particular batch task/thread. The number is then multiply by number of tables defined in the entity view.
With no or virtually no statistical data in the target table, SQL optimizer tends to establish execution plan by (1) scanning cluster index (2) with the use of nested loop join. The SQL execution plan I got is to always start using cluster index scanning from EcoResProduct by its RecId index to nested join all the related tables defined in the EcoResProductEntity view and then finally nested loop join again to the EcoResProductStaging table by seeking RecId.
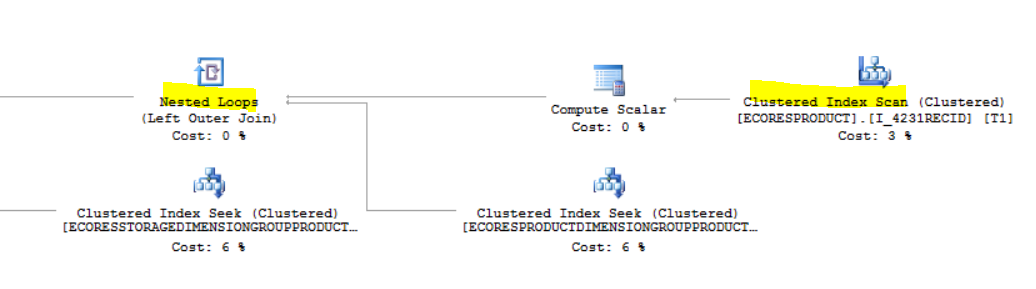
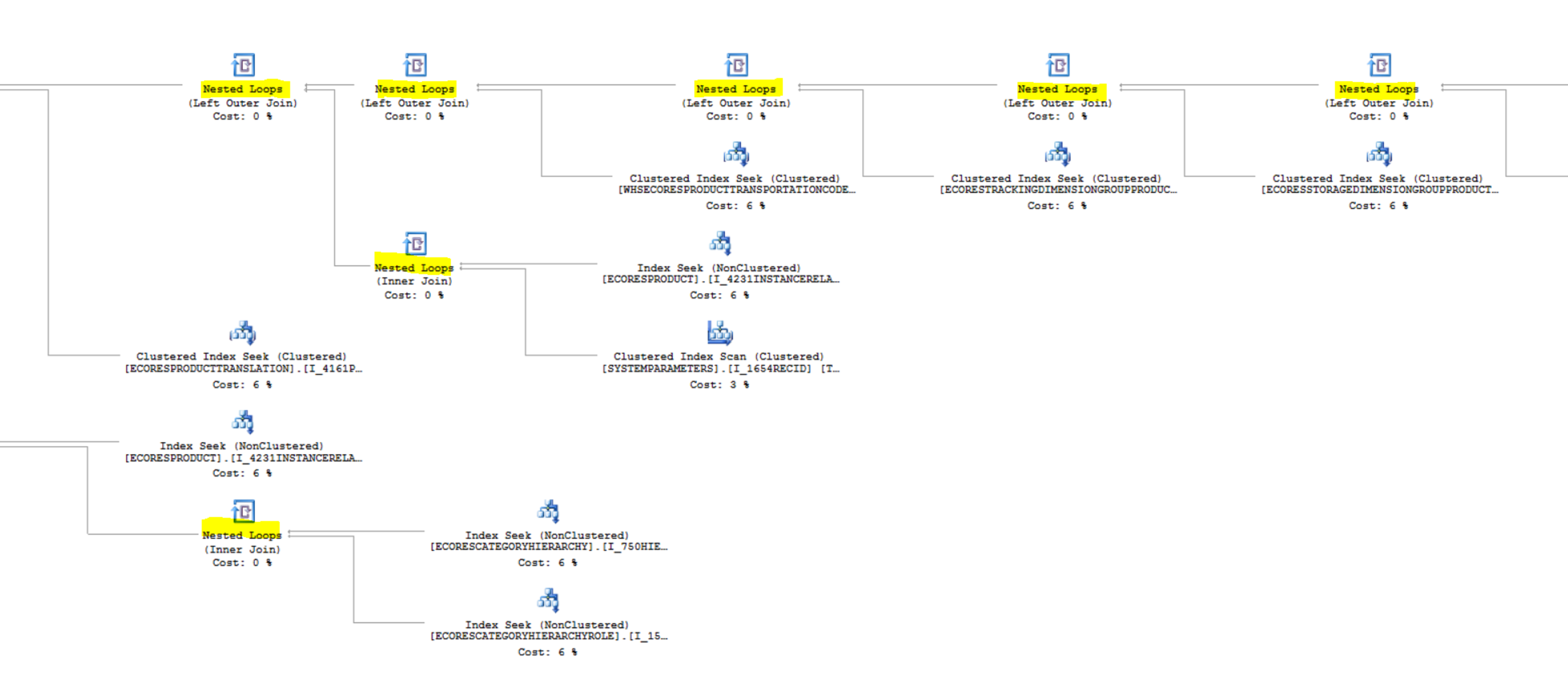
One option to address is to use set-based processing in the entity. However, not all entity supports set-based process. The 2nd option is to write SQL plan guide to use hash join hint instead. You may want to work with your DBA to identify the exact SQL statement to write SQL plan guide. I include the SQL plan guide used for your reference which reduces to about an hour from days of process.
exec sp_create_plan_guide
@name = N’EcoResProductStaging_Import_Hash’,
@stmt = N’SELECT T1.AREIDENTICALCONFIGURATIONSALLOWED,T1.HARMONIZEDSYSTEMCODE,T1.ISAUTOMATICVARIANTGENERATIONENABLED,T1.ISCATCHWEIGHTPRODUCT,T1.ISPRODUCTKIT,T1.ISPRODUCTVARIANTUNITCONVERSIONENABLED,T1.NMFCCODE,T1.PRODUCTCOLORGROUPID,T1.PRODUCTDESCRIPTION,T1.PRODUCTDIMENSIONGROUPNAME,T1.PRODUCTNAME,T1.PRODUCTNUMBER,T1.PRODUCTSEARCHNAME,T1.PRODUCTSIZEGROUPID,T1.PRODUCTSTYLEGROUPID,T1.PRODUCTSUBTYPE,T1.PRODUCTTYPE,T1.RETAILPRODUCTCATEGORYNAME,T1.STCCCODE,T1.STORAGEDIMENSIONGROUPNAME,T1.TRACKINGDIMENSIONGROUPNAME,T1.VARIANTCONFIGURATIONTECHNOLOGY,T1.RECID,T2.PRODUCTTYPE,T2.PRODUCTSUBTYPE,T2.PRODUCTNUMBER,T2.PRODUCTNAME,T2.PRODUCTSEARCHNAME,T2.PRODUCTDESCRIPTION,T2.ISCATCHWEIGHTPRODUCT,T2.PRODUCTDIMENSIONGROUPNAME,T2.PRODUCTDIMENSIONGROUPRECID,T2.STORAGEDIMENSIONGROUPNAME,T2.STORAGEDIMENSIONGROUPRECID,T2.TRACKINGDIMENSIONGROUPNAME,T2.TRACKINGDIMENSIONGROUPRECID,T2.VARIANTCONFIGURATIONTECHNOLOGY,T2.AREIDENTICALCONFIGURATIONSALLOWED,T2.ISAUTOMATICVARIANTGENERATIONENABLED,T2.ISPRODUCTVARIANTUNITCONVERSIONENABLED,T2.RETAILPRODUCTCATEGORYNAME,T2.RETAILCATEGORYRECID,T2.PRODUCTCOLORGROUPID,T2.PRODUCTSIZEGROUPID,T2.PRODUCTSTYLEGROUPID,T2.ISPRODUCTKIT,T2.STCCCODE,T2.HARMONIZEDSYSTEMCODE,T2.NMFCCODE,T2.RECID#2,T2.RECVERSION#2,T2.RECID#3,T2.RECVERSION#3,T2.RECID#4,T2.RECVERSION#4,T2.RECID#5,T2.RECVERSION#5,T2.RECID#6,T2.RECVERSION#6,T2.RECID#7,T2.RECVERSION#7,T2.RECID#8,T2.RECVERSION#8,T2.RECID#9,T2.RECID#10,T2.RECVERSION#10,T2.RECID#11,T2.RECID#12,T2.RECVERSION#12,T2.RECID#13,T2.RECVERSION#13,T2.RECID#14,T2.RECVERSION#14,T2.RECID#15,T2.RECVERSION#15,T2.MODIFIEDBY,T2.RECVERSION,T2.PARTITION,T2.RECID FROM ECORESPRODUCTSTAGING T1 LEFT OUTER JOIN ECORESPRODUCTENTITY T2 ON ((((((((((((((((T2.PARTITION=0123456789) AND ((T2.PARTITION#2=0123456789) OR (T2.PARTITION#2 IS NULL))) AND ((T2.PARTITION#3=0123456789) OR (T2.PARTITION#3 IS NULL))) AND ((T2.PARTITION#4=0123456789) OR (T2.PARTITION#4 IS NULL))) AND ((T2.PARTITION#5=0123456789) OR (T2.PARTITION#5 IS NULL))) AND ((T2.PARTITION#6=0123456789) OR (T2.PARTITION#6 IS NULL))) AND ((T2.PARTITION#7=0123456789) OR (T2.PARTITION#7 IS NULL))) AND ((T2.PARTITION#8=0123456789) OR (T2.PARTITION#8 IS NULL))) AND ((T2.PARTITION#9=0123456789) OR (T2.PARTITION#9 IS NULL))) AND ((T2.PARTITION#10=0123456789) OR (T2.PARTITION#10 IS NULL))) AND ((T2.PARTITION#11=0123456789) OR (T2.PARTITION#11 IS NULL))) AND ((T2.PARTITION#12=0123456789) OR (T2.PARTITION#12 IS NULL))) AND ((T2.PARTITION#13=0123456789) OR (T2.PARTITION#13 IS NULL))) AND ((T2.PARTITION#14=0123456789) OR (T2.PARTITION#14 IS NULL))) AND ((T2.PARTITION#15=0123456789) OR (T2.PARTITION#15 IS NULL))) AND (T1.PRODUCTNUMBER=T2.PRODUCTNUMBER)) WHERE ((T1.PARTITION=0123456789) AND (((T1.DEFINITIONGROUP=@P1) AND (T1.EXECUTIONID=@P2)) AND ((T1.RECID>=@P3) AND (T1.RECID<=@P4)))) ORDER BY T1.RECID’,
@type = N’SQL’,
@module_or_batch = NULL,
@params = N’@P1 nvarchar(61),@P2 nvarchar(91),@P3 bigint,@P4 bigint’,
@hints = N’OPTION(HASH JOIN)’



{kind=link}