


Using Azure Data Lake Storage (ADLS) and Azure Datasets for Machine Learning

Data Lake
Many organisations are now focusing on a single version of truth of their data, typically via some form of a data lake strategy. This brings several benefits, such as a single access point, fewer silos, and an enriched dataset via the amalgamation of data from various sources. Microsoft’s answer to this strategy is Azure Data Lake Storage (ADLS). ADLS brings several benefits to enterprises, such as security, manageability, scalability, reliability and availability.
A typical approach to a data lake strategy that we see being adopted by customers is the hierarchical approach (see fig 1), where the data is first ingested into a landing layer, typically referenced as the “raw data lake”. Data is then processed, filtered, optimised and placed in the “curated data lake”. This is then further refined/processed based on the application/service-specific logic, and placed in what is referred to as the “product data lake”.
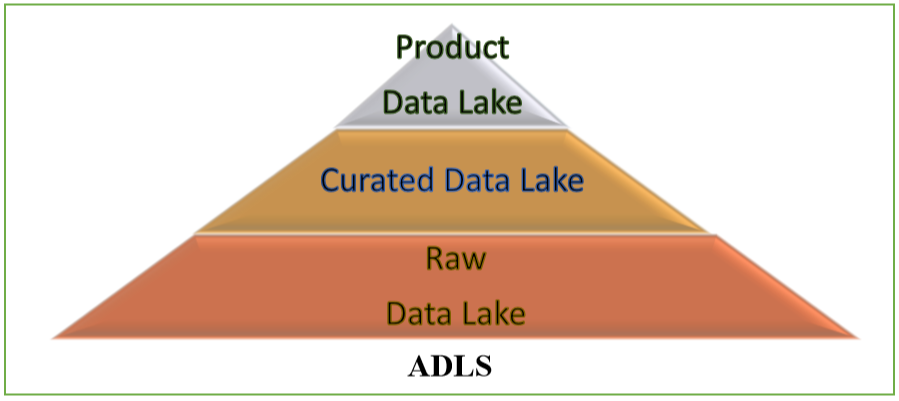
Figure 1- Datalake Abstraction Strategy
Raw Data Lake
A raw data lake provides a single version of truth for all the data in an organisation and can be seen as the landing zone for all the data. Data from various sources, whether structured, semi-structured or unstructured is ingested in its native format. Some optimisation and basic data quality checks, such as total number of rows ingested and other basic operations, may be applied at this stage.
When the data is landed, there are a couple of things to consider before moving it to the “curated data lake”: Who has access to this data? How will it be secured? How is it going to be processed? What partition strategy should be used? How should it be logged and what file format and compression techniques should be considered? This layer is typically owned by IT.
Curated Data Lake
While the raw data lake is targeted at the organisation level, the curated data lake is focused on the division or OU level. Each division may define its own business rules and constraints of how the data should be processed, presented and accessed. Data is typically stored in an optimised format and tuned for performance and is generally cleaned (handling missing values, outliers and others), aggregated and filtered. Curated data tends to have more structure and is grouped according to specific domains, such as Finance, HR, etc.
Product Data Lake
The product data lake typically tends to be application specific, and is normally filtered to the specific interest of the application. The application focus in this article is machine learning, which relies on large volumes of data to use for modelling and for batch or real-time inferencing before being written back to the product data lake.
Such benefits would be futile if we are not able to perform advance analytics in a way that gives predictive capabilities. Here we have defined an Azure ML stack infused with a data lake strategy.
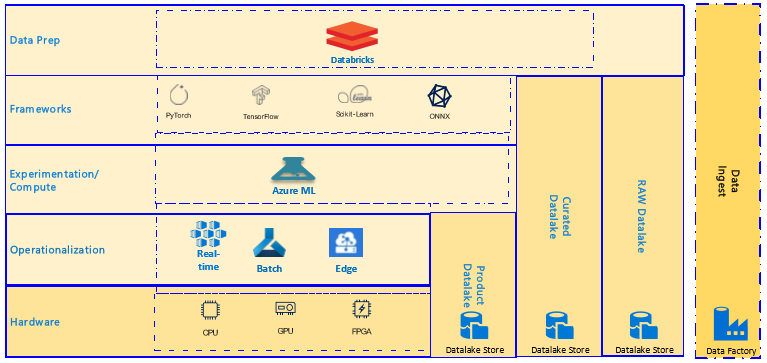
Figure 2- Data Lake infused in ML Stack
The ML stack consists of various layers which are infused with different categories of data lake storage. The first layer, “Data Prep” is where raw data is processed depending on the business logic and domain constraints, typically using Databricks, and is made available to product-specific data lakes.
Layer two consists of various frameworks to be used for the ML problem at hand and would typically use the product data lake to conduct various feature engineering.
Layer three consists of Azure machine learning, for carrying out experiments using various compute targets and tracking of experiments, and would use the product data lake as the source of experimentation data. Any write-back would take place in this layer. The output of the model or inferencing results will also be stored in the product data lake.
The core of this stack lies in the ability of Azure machine learning to be able to access and interface with the data lake store. The rest of the paper will focus on how this can be achieved.
Azure Machine Learning
The Azure Machine Learning Service (AMLS) provides a cloud-based environment for the development, management and deployment of machine learning models. The service allows the user to start training models on a local machine, then scale out to the cloud. The service fully supports open-source technologies such as PyTorch, TensorFlow, and scikit-learn and can be used for any kind of machine learning, from classical to deep learning, supervised and unsupervised learning.
Figure 3 below shows the architectural pattern that focuses on the interaction between the product data lake and Azure Machine Learning. Until recently, the data used for model training needed to either reside in the default (blob or file) storage associated with the Azure Machine Learning Service Workspace, or a complex pipeline needed to be built to move the data to the compute target during training. This has meant that data stored in Azure Data Lake Storage Gen1 (ADLSG1) typically needed to be duplicated to the default (blob of file) storage before training could take place. This is no longer necessary with the new feature dataset.
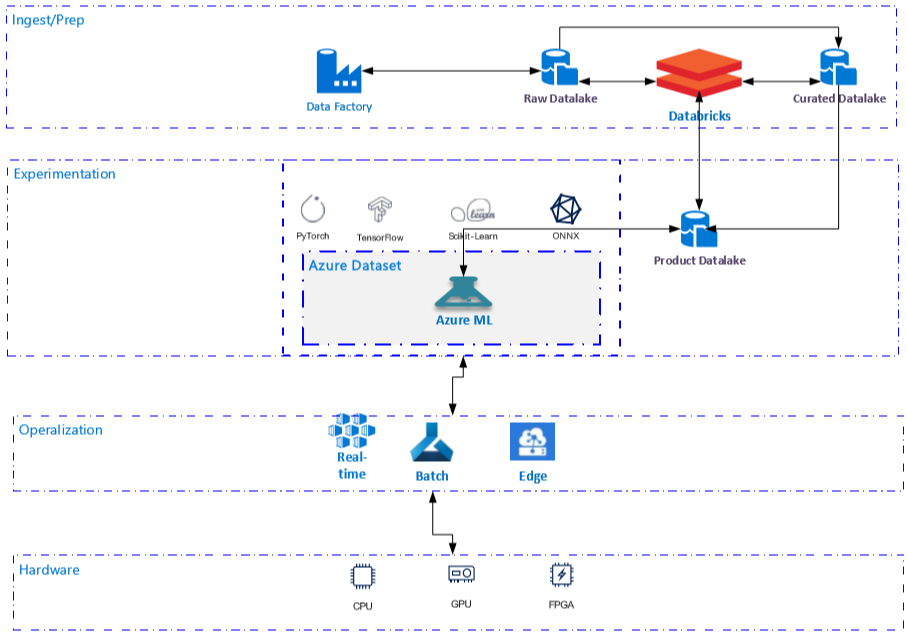
Figure 3 – ADLS Architectural Pattern for MLS
Azure Dataset
The new dataset feature of AMLS has made it possible to work with data files stored in ADLSG1 by creating a reference to the data source location, along with a copy of its metadata. The data remains in its existing location, so no extra storage cost is incurred. The data set is thus identified by name and is made available to all workspace users to work with.
Simple Example (Azure ML SDK Version: 1.0.60)
In the following example we will demonstrate how we can use the Azure datasets with Azure Machine Learning to build a machine learning model using the product data lake. The steps are as follows:
-
- Step 1: Register the product data lake (ADLS Gen1) store as a data store in the AMLS workspace
- Step 2: Register a file (CSV) as a dataset in the AMLS workspace
- Step 3: Train a model
Step 1: Register the Product Data Lake as a data store in the AMLS workspace
We will be using Azure ML Notebook VM to implement to demonstrate this example. This is because it comes pre-built with the Python Jupyter Notebook with MLS SDK installed. However, if you prefer to use your own IDE, you will need to install the MLS python SDK.
from azureml.core.workspace import Workspace
from azureml.core.datastore import Datastore
from azureml.core.dataset import Dataset
#Give a name to the registered datastore
datastore_name = " adlsg1 "
#Get a reference to the AMLS workspace
workspace = Workspace.from_config()
#Register the Data store pointing at the ADLS G1
Datastore.register_azure_data_lake(workspace,
datastore_name,
"[Name of the Product Datalake]",
"[AAD Tenant ID]",
"[Service Principal Application ID]",
"[Service Principal Secret]",
overwrite=False)
The above code snippet assumes that the AMLS configuration file is available in the working directory. The file can be downloaded from the Azure portal by selecting “Download config.json” from the Overview section of the AMLS workspace. Or you can create it yourself:
{
"subscription_id": "my subscription id",
"resource_group": "my resource group",
"workspace_name": "my workspace name"
}
We also need to register an application (Service Principal) with the Azure Active Directory (AAD) tenant with Read access on the data lake storage files we need to use.
Note: You should use a Key Vault to store the service principal ID & Secrets.
At this stage the ADLSG1 should be registered as a datastore in the workspace. This can be tested using the following, which should return an azureml.data.azure_data_lake_datastore.AzureDataLakeDatastore object:
# retrieve an existing datastore in the workspace by name dstore = Datastore.get(workspace, datastore_name) print(dstore)
Step 2: Register a CSV file as a dataset in the AMLS workspace
dstore = Datastore(workspace, datastore_name) filepath='[file path in ADLS Gen1]' dset = Dataset.Tabular.from_delimited_files(path = [(dstore, filepath)])
Now the data file is available as a data frame in memory, for example to return the first 5 rows:
dset.take(5).to_pandas_dataframe()
To register the dataset with the workspace:
dset_name = 'adlsg1_dataset' dset = dset.register(workspace, name = dset_name, description = '[Data Set Description]')
To get a list of the datasets registered with the workspace:
print(Dataset.list(workspace))
Step 3: Train a Model
#Get the dataset that is already registered with the workspace data_set =Dataset. .get_by_name (workspace, 'adlsg1_dataset') #Use the dataset dataset=data_set.to_pandas_dataframe()
The above code will get an existing registered dataset and covert it to a Pandas dataframe. You can then conduct additional pre-processing and feature engineering. You also have the option of reading it as a Spark dataframe.
X = dataset.iloc[:, :-1].values # independent variable
y = dataset.iloc[:, 1].values # dependent variable
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 1/3, random_state = 0)
run = Run.get_context()
print('Train a linear regression model')
regressor = LinearRegression() # This object is the regressor, that does the regression
regressor.fit(X_train, y_train) # Provide training data so the machine can learn to predict using a learned model.
y_pred = regressor.predict(X_test)
print(y_pred)
The above code splits the dataset into training and testing as well as input and output features. A simple linear regression model is trained and validated using the validation dataset.
Summary
In this article, we have articulated various levels of abstractions of data using Azure Data Lake Storage and how they are mapped to different levels of the AI stack for building end-to-end machine learning models. The important thing to note is that the new datasets feature of AMLS provides an easy and reusable way of interacting with ADLS to build ML models, then apply inferences. Please note that although this article uses ADLS Gen1, a similar approach can be used for ADLS Gen2.
Code
For the full source code, please visit the GitHub page.


