


Unified Data Governance using Azure Purview – preventing Data Lake from becoming a Data Swamp

With Azure Purview, Microsoft launched a unified data governance service that automates data discovery, cataloguing, building lineage, and classifying sensitive data, enabling users to get a holistic view of the data landscape. Today, Data Lake is a strategic investment if you’re in a data driven organisation. Here’s our shared experience on why Purview should be a key component in your Data Lake architecture.
Most data professionals have worked with tabular data stored in databases because that was the way applications and reporting systems were designed or built. This meant there were only a finite number of tables/databases to search for relevant information. With the advent of newer technologies such as IoT devices, and a plethora of web and mobile applications, data professionals must not only process and secure structured, semi-structured and unstructured data but also discover the pertinent data from the huge amount of data accumulated by the organisation to solve business problems.
Many organisations are now moving to a more complex architecture that has data stored as flat files in storage such as Data Lake, unstructured data in non-relational and tabular data in relational databases. Managing the life cycle of data from creation to archival has been extremely challenging and requires massive investment from an organisation including training people, optimising existing or creating new processes, and adopting new technologies. Despite all these efforts, it remains the nightmare of many CDOs and CSOs. As Gartner suggests, over 60 percent of challenges to the data management practice arise from data quality and supporting data governance and security.
Linking to the real world
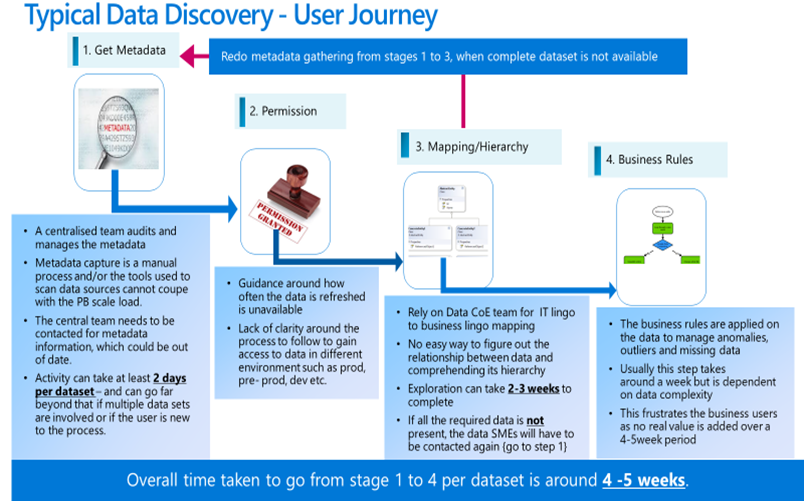
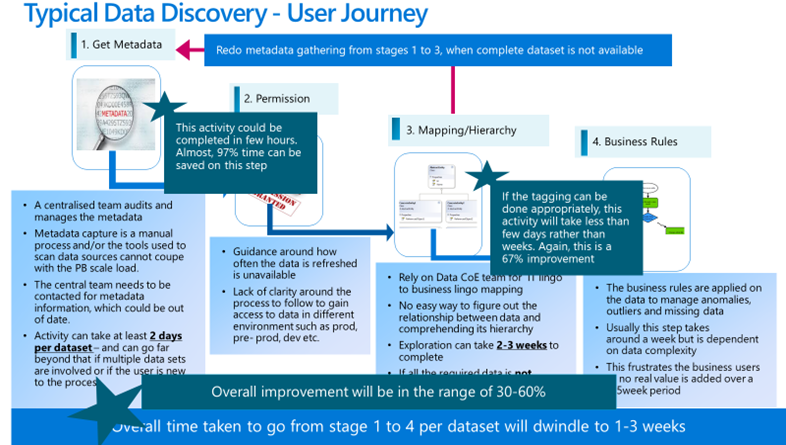
Many of our customers have a petabyte-scale Data Lake, and it doesn’t take long for data governance to become extremely difficult. The purpose of the Data Lake is to accelerate data projects by having the entire organisation’s information in one place. The average time taken to identify and retrieve the relevant data from the Data Lake is somewhere between 5-6 weeks. We might have heard of the old adage “time is money”, and it’s true for our customers. The time taken at the beginning of the project to discover relevant information is unacceptable because the project team is to be paid during this phase, and the business gets frustrated as no progress is made on the project. In the meantime, the competitor would have shipped the latest product when the project team was searching for relevant information to kick start the project.
The user journey for data discovery and mapping can be summarised as shown below:
What is data governance?
We just covered the complexities of a modern data estate, and the key challenge is the lifecycle management of data. Data governance is not just about data quality but also about metadata, policy, and identity management. Broadly speaking, we can divide the people accessing data into four categories:
- Producer – the data stewards/data experts, who understand the business well and help curate the data for consumption by downstream applications.
- Consumer – project owners or business users of downstream applications that use the data produced by the producer.
- Data security officer – interested in securing the data asset of your organisation.
- Chief compliance officer – responsible for data’s compliance to GDPR or any new rules and regulations imposed by the government.
At a high-level, metadata management provides the data about the organisation’s data. For example, it provides the physical location of the data you are trying to find, identifies the different columns in a file and applies appropriate classification for the column within a data asset. Finally, it also provides the data lineage, which indicates the source for the information, the transformation applied on the source information, where it’s getting used etc. The personas interested in metadata management are producers and consumers. The consumers leverage the search functionality to find the relevant data in a huge Data Lake or other data sources.
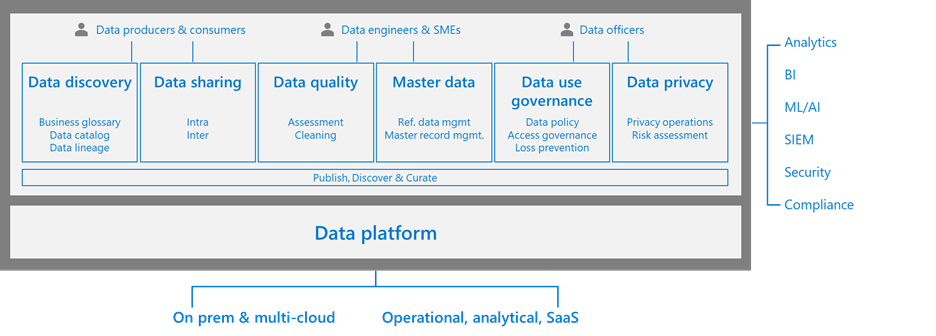
Policy and identity management is of interest to the data security officer persona. For example, they need to ensure finance information is accessed only by the finance department, define how long data should be retained for compliance purposes and so on. Our colleague, Pratim Das, has previously covered how to build and deliver a data strategy in great depth.
What Is Azure Purview?
You can get more from data sources with Microsoft Azure Purview. Azure Purview is a fully managed cloud service that serves as a system for registration and system of discovery for enterprise data sources. It provides capability that enables any users, from analysts to data scientists and developers, to register, discover, understand, and consume enterprise data sources.

The role of a data catalogue in Data Lake architecture
A data catalogue lifecycle will register the various sources, discover the shape of the ingested dataset, understand and trace the data as it flows through intermediate layers, and finally enable analysts and engineers to consume those data by downstream applications.
1. Register
The USP of Data Lake architecture is to break the problem of data in silos and gain valuable insights from TBs and PBs of data, which was not possible five years or even a decade ago. Not only that, a Data Lake expedites getting insights in near to real time. As different heterogenous data is ingested in the lakes – whether the traditional relational database, semi-structured JSON, XML-type data, HDFS-like data (Avro, Parquet etc) – it’s important more than ever to have a central place of metastore.
The ability to connect to diverse data sources is also a vital capability. Azure Purview allows you to register not only cloud native storage and databases such as Azure Data Lake, Azure CosmosDB, Azure Synapse, but also on-premise databases, e.g. SQL Server etc. 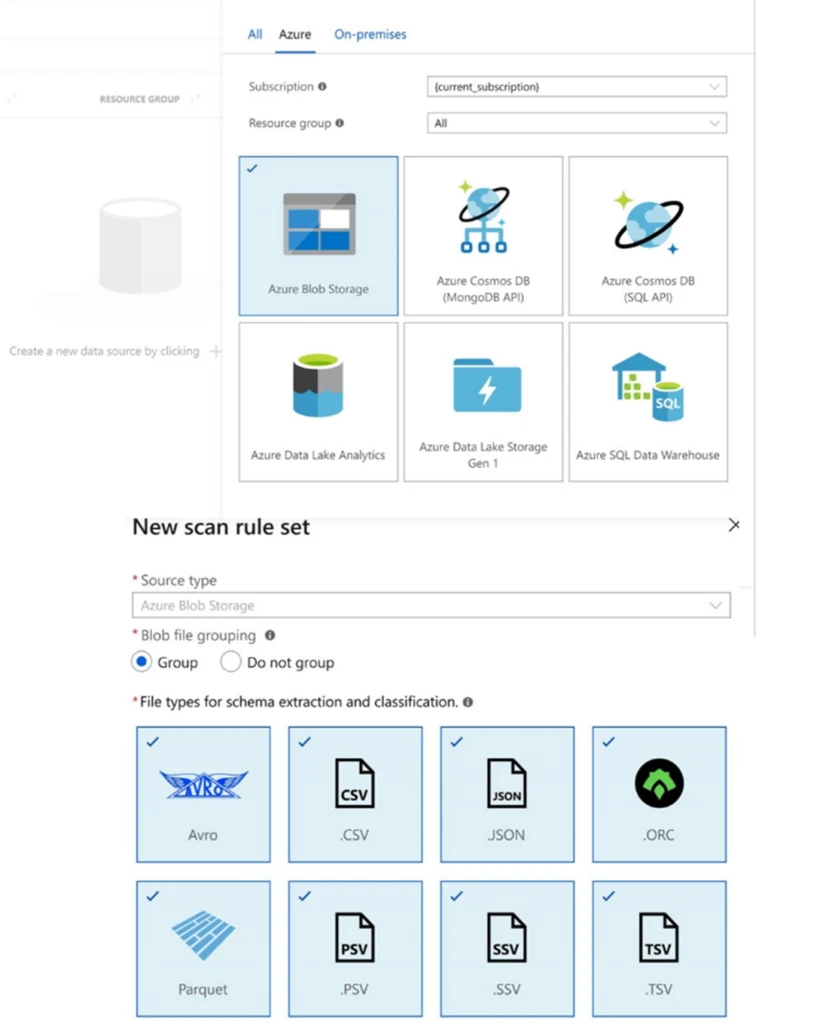
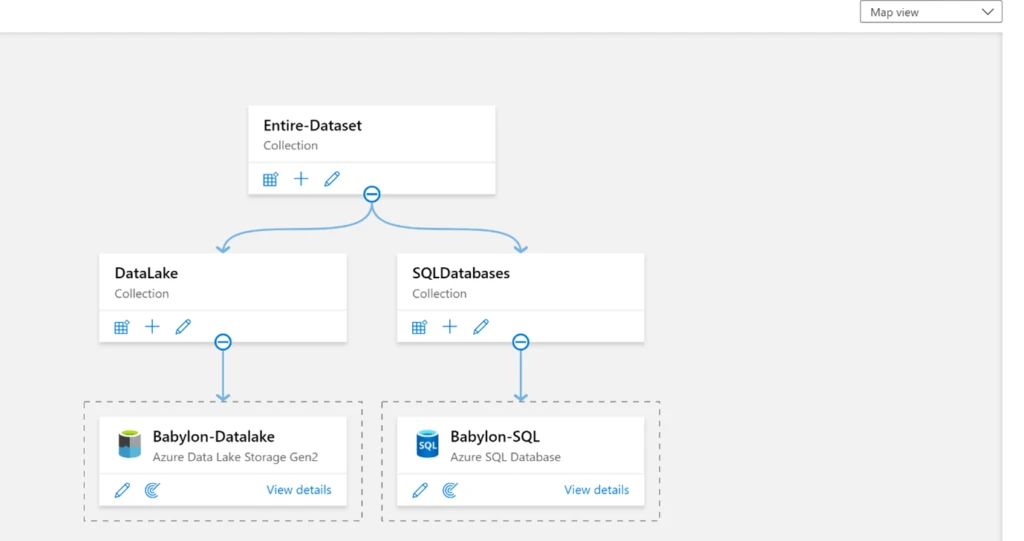
You can also logically group assets based on a project or an entire data asset in the organisation. An example is shown below:
2. Discover
Let us take the next step. You have TBs of data in your Data Lake connected to 100+ data sources. Is that good enough? No. Data lying undetected or unexplored is as bad as, if not worsethan, not ingesting large data in the analytics domain. Hence, the ease of discovering data empowers the end users or business users and this capability will determine the adoption of the Data Lake asset in an organisation.
3. Understand
Lineage – Single source of truth vs single version of truth
In so many meetings, I have found even the most technology-minded decision makers use “single source of truth” and “single version of truth” interchangeably. But there is a clear difference.
Single source of truth means that the data comes from a specific source all the time. You have a CRM system running on SQL Server, then the data coming from that is the single source of truth. However, in some other scenario, say weather information, data is pulled from public datasets and also from the IoT sensor data that lands in your Data Lake. In such cases, there is no single source of truth.
Single version of the truth
Any transactional or temporal data system will change multiple times over its lifecycle, and it can upset an operation or delete an operation. The single version of the truth is to ensure you get the most consistent version, not necessarily the latest version, of the data that is available in the Data Lake.
Your organisation might be trying to solve the problem “How to get the single version of the truth on Data Lake”, and the answer is in the lineage.
Why lineage is important
The ability to trace and track the data as it goes out of the data source and then goes through multiple layers in the Data Lake – usually raw, curated, enriched etc – allows an environment of transparency in the data organisation and encourages self-service analytics in the ecosystem. Every time the data is manipulated or transformed, the shape and the meaning of the data changes.
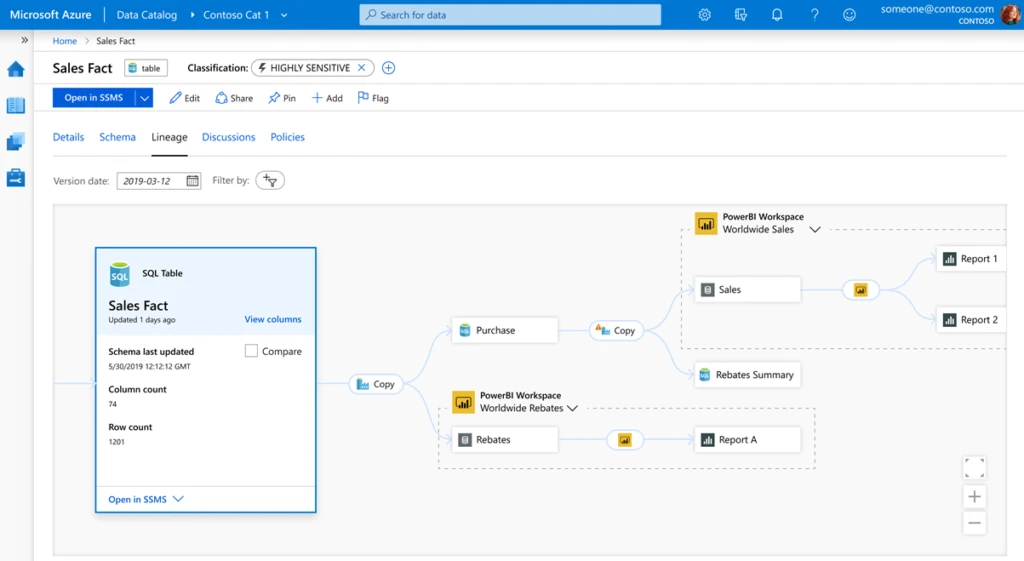
Azure Purview offers the lineage capability all the way from the source to the destination. This feature answers several questions from consumers when considering the data in end-user products.
Examples of these questions are:
- Is the data source a trusted one that has been approved by the data owner?
- Is it an internal or external data source?
- Which KPIs are created in which phase and should I select granular or summary data for downstream applications?
- In case the data needs to be validated, which trail should I follow during RCA or support incident issues?
4. Consume
A glossary acts as a glue between the business decision users and the technical engineers, and is a very common setup.
Take a hypothetical situation. You’re talking to your parents and during your conversation you use the terms “YOLO”, “FOMO” etc. Even though these are English abbreviations, your parents may have never heard of them.
Similarly, in the IT world, if you’re from an IT background and use the terms “materialised views”, “data factory” etc, business users may not understand. Also, business users from the supply chain might use functional jargon such as “APS”, “B2C”, “MRP” etc, and IT engineers may not have the knowledge to interpret it.
In addition, different terms mean different things, depending on context. “APS” in the technology world means Analytics Platform System, whereas “APS” in the retail space refers to Advance Planning and Scheduling.
A glossary solves this problem by enriching the catalogue, adding business terms and definitions and linking those terms with the datasets or Data Lake assets.
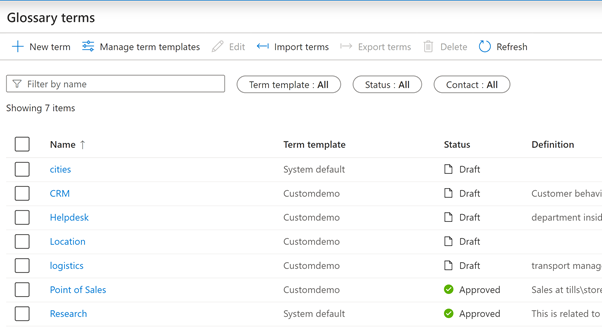
In Data Lake architecture, the idea is to cross pollinate the data from one business area with another to get a holistic picture. The datasets contain raw and KPI driven measures that are relevant to a specific business function. However, cross-skilling SMEs, developers and analysts is not always possible. A glossary can act as one place to manage those business terms and give control to the data owner to publish the data and bring consistency across the various business units in the organisation.
Linking to the real world – continued
Earlier, we spoke about how the data discovery phase takes more than 5-6 weeks. When Azure Purview was presented as a solution, it was looked upon with scepticism. With the reincarnation of Azure Purview, Microsoft has injected a lot of features into a genuinely stable productthat is here to stay. The scan of the entire Data Lake, which was over 1PB, took less than two days to complete. Customers can speed up this operation if the integration runtime is scaled from one to four. These scans can be run on a schedule and as frequently as required.
By default, Microsoft provides a list of classification to which the data is classified during each scan. Similarly, the glossary terms can be associated with assets discovered during the scan. Any existing documentation pertaining to the data on web pages or a SharePoint site can be linked to an asset via the glossary. Many of these activities are automated and can be used as soon as the Azure Purview is provisioned. You can also use the Apache Atlas API to extend any existing feature.
After the scan and tagging operation, one of our customers was able to complete the data-discovery journey for various projects in 1-3 weeks rather than 5-6 weeks per dataset. This is a marked improvement, as the catalogue setup itself is easy and is a PaaS service.
This product is just starting its journey outside private preview and has an exciting vision and roadmap. So please give us your feedback to help us shape the product in future.
Conclusion
Azure Purview helps to answer the who – what – when – how – where – why of the data present in not only Data Lake but also other data sources, and brings the data closer to the user. When your organisation moves away from centralised to self-service analytics, the value of the Data Lake is unlocked, and the digital feedback loop empowers employees to make data-driven decisions that will determine success in the coming decade. One of the key services that will unblock self-service analytics in your organisation is Azure Purview. Get started with Azure purview with our quick-start guide.


