
Congratulations! You’ve made it to the next installment of our overview of Trill, Microsoft’s open source streaming data engine. As noted in our previous posts about basic queries and joins, Trill is a temporal query processor. Trill works with data that has some intrinsic notion of time. However, Trill doesn’t assign any semantics to that notion of time other than it is some value that is always generally increasing. So, what could qualify as “time” to Trill? It could be just about anything:
- Event time, or a time that is naturally associated with each event, such as the time a sensor reading is taken
- System time, or the time when an event arrives at the server or event queue
- Processing time, or the time when an event arrives at the given processing node running Trill
- Incremental time, or just a value that increments for each event seen
No matter where your “time” concept comes from, Trill will work for it. All Trill needs is for it to be a long-valued field and Trill is ready to go.
Tell me what to do
There are several ways to tell Trill what the time component of the data is. The most explicit way to do it is using StreamEvent objects that attach to every event a lifespan. StreamEvent objects can be created using static factory methods on the StreamEvent class. For instance, this method creates an event with a set interval:

This method creates an event called a “start edge”, which is in effect an interval with no set end time:

Lastly, if the data really corresponds to just point events, there is a method for that as well, though inside Trill a point is simply stored as an interval of minimal length 1 tick:
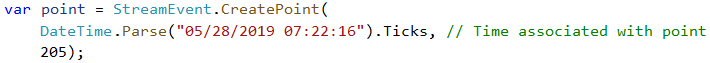
If you have an observable of these StreamEvent objects, getting data into Trill is straightforward using the method ToStreamable:
![]()
![]()
Or just give me a hint
If you don’t want to go through the extra step of creating StreamEvent objects, there are a few ways to bring data directly into Trill while also telling it how to reason about time. How you do it depends on if your data already has a time component, or otherwise if you want Trill to assign time to your data. Let’s look at one example, given just an observable of data values:

Breaking this example down, note first that the result of the method call is the same IStreamable type as with the StreamEvent example. The only difference is that instead of assigning time in the observable, we are assigning it in the ToStreamable call. The method name has changed to ToTemporalStreamable because the input data has a natural time component called “Time”. This method is the logical equivalent of wrapping each element in the observable with a StreamEvent.CreateStart call beforehand, but without allocating the StreamEvent objects.
What if instead of a single time field in TPayload there are two temporal fields, indicating start and end time? There is an overload for that as well, with lambdas for identifying the start and end fields:

What if type TPayload doesn’t have a natural time component? In that case, Trill itself can assign time values to events depending on user needs. The following example assigns to each event the current system time at the point of ingress:

This last example is a clever way to produce progressive results from an arbitrary data stream. Instead of assigning to each event a “time” that corresponds to something like what we would see on a clock, we assign a sequence number that bumps every 100 input rows:

This example uses Trill’s native temporal capabilities to produce partial results from what someone would normally think of as “atemporal” data. Want to calculate the average value of a sequence of integers, but want to get a partial result of said average every 100 values? Assign the first 100 values a time of “0”, the next 100 values a time of “1”, and so on, and Trill will do all the rest for you:

The final line of the example above shows how to get data out of Trill and back into an observable. Perhaps ironically and not surprisingly, we will cover this topic briefly at the end of this post.
Order! Order!
While the section above demonstrates how to assign time to events in Trill, there is one more wrinkle that must be dealt with and must be done at ingress. Trill’s query engine is an in-order data processor. It is incredibly efficient in memory usage with high throughput, but many of the tricks it uses internally rely on data being presorted, such as the following:
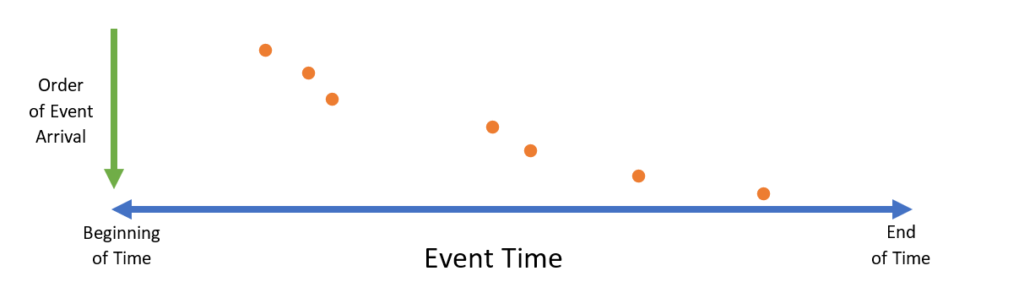
If data resides in a database and is sorted and indexed for historical queries, there is no problem with the sorting assumption. However, in this strange setting called the “real world,” data does not always arrive at the query processor in the desired order, especially in streaming as opposed to offline settings. Hence, the input data may look a little more like this:
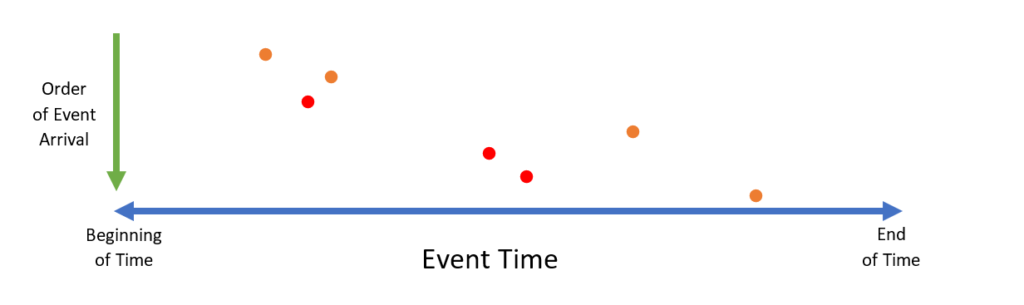
Trill’s paradigm for dealing with data that arrives out of order is to attend to it at ingress. Any data that makes it past ingress must be ordered. One simple option is to throw an exception as soon as out-of-order data is found:
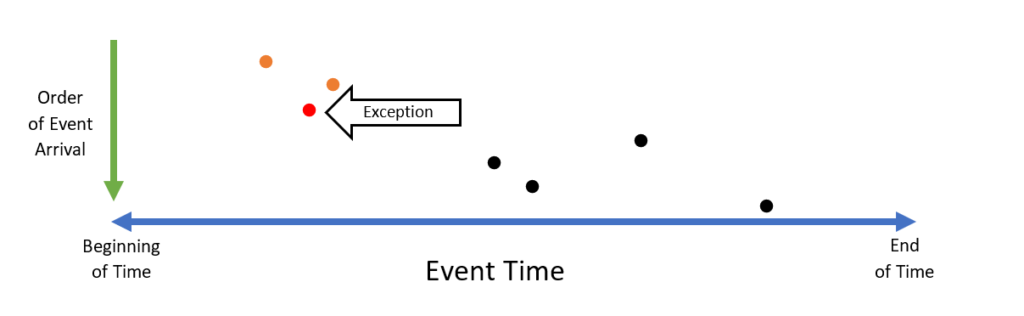
This solution is not exactly relevant for most online streaming scenarios. However, if your temporal data has been stored to disk and has been sorted by time (or at least should have been), it’s a good safety check to have. It’s also a good option if the time associated with each event is assigned at ingress time.
Another option is to ignore any data that arrives out of order:
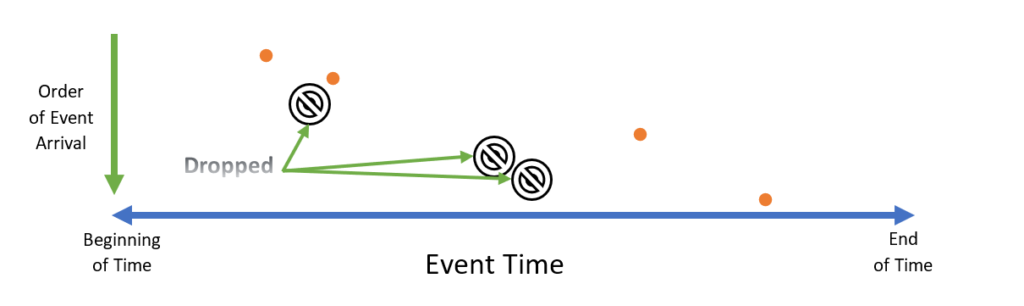
Lastly, one can adjust the timestamp of data that arrives out of order to match the most recent timestamp:
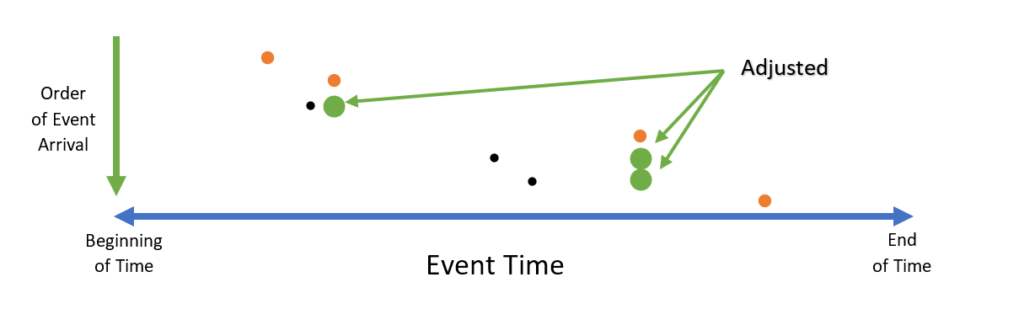
The author sets one of these disorder policies at the point of ingress by adding additional parameters to the ingress methods, like this:

Dropped data and pre-adjusted data are both sent to a separate stream that can be monitored:
![]()
![]()
Patience is a virtue
The three options presented in the previous section work on their own for some scenarios but leave many scenarios unsupported. Far more often than not, the prospect of dropping data or adjusting timestamps is, put lightly, a major no-no. To cover more cases of disordered real-world streaming data, Trill offers two additional features that address common patterns.
Firstly, Trill allows the query author to specify a lag allowance, a fixed period that Trill buffers incoming data and sorts it on timestamp. Think of the lag allowance as a traveling window of time within which data is held back and sorted. Trill uses a sorting algorithm that is very fast in most cases but is especially fast in scenarios where the data is “almost sorted”, which is a great way to characterize incoming stream data. Namely, in nearly all real-world cases, as streaming data arrives the high watermark for time mostly moves forward. There are fluctuations and bits of disorder, yes, but generally speaking, time moves in one direction as opposed to data arriving at random times.
Consider again the example of ingress data from the previous section, but this time with a lag allowance of time L:
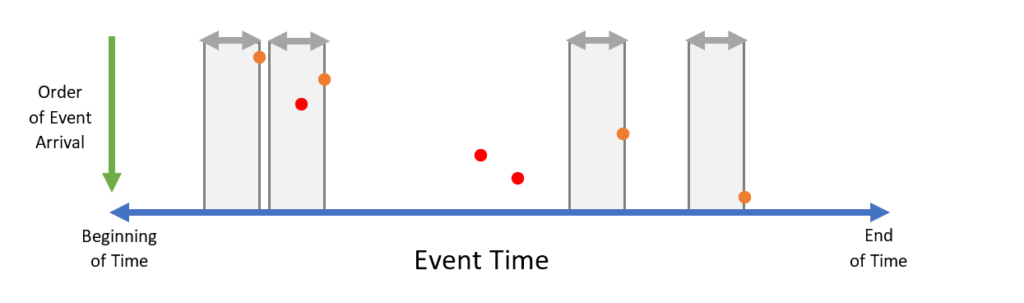
When the first event arrives, it is not immediately processed. Instead, it is held in a buffer, and a window of time L is established. When the second event arrives, it is more than time L ahead of the first point. The first event leaves the buffer and gets processed, while the second event now gets buffered and sets a new window.
Now, the first out-of-order point arrives. It trails in time from the second point, but it is within the sorting window. It is added to the buffer, timestamp unchanged, in sorted order:
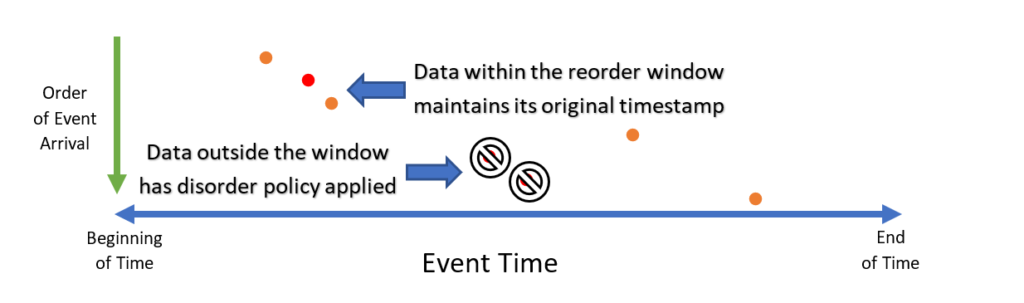
Allowing some lag offers the query author a latency/correctness tradeoff; the longer the author is willing to wait for results, the more likely that disordered input data can be sorted inline without any adjustment. For a larger lag allowance, it is possible to include the remaining two out-of-order points; however, the user will need to wait longer for results.

Going their separate ways
Trill’s second trick up its sleeve for handling disordered input is especially suited for an Internet-of-Things (IoT) environment. A common scenario in IoT settings is for the clocks on each device to not be entirely in sync. Devices may join and leave the network, either purposefully or from network partitioning, at any time. Skew between device times is not only common but expected.
Also common in IoT settings are queries that are run per device as opposed to over the entire network. If the user wants, for instance, to know the maximum temperature reading per hour per device, we absolutely do not want any data from one sensor to be adjusted relative to another. If anything, we want each device in the network to essentially have its own timeline independent of one another:
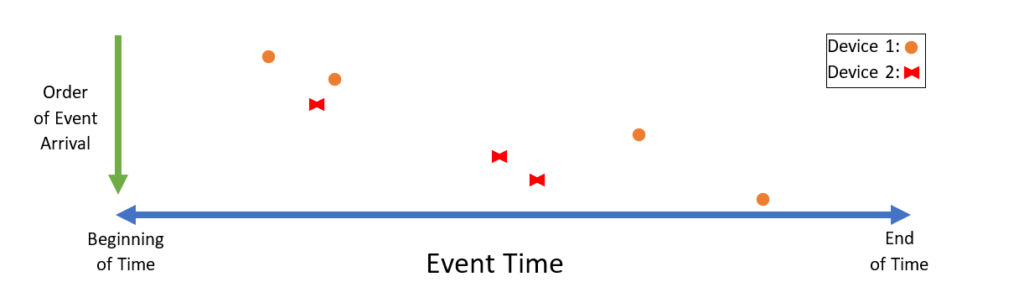
In the example above, the data does not arrive in a single global order. However, notice that the data does arrive in temporal order for each device.
Trill allows this scenario using a feature called partitioned streams. Each partition is allowed its own timeline that has its own high watermark. The disorder policies are only applied per device if needed at all. Then Trill can compute the query over each device without needing a global order.
There are two ways to enable this feature in Trill. The more explicit way to do so is to create PartitionedStreamEvent objects instead of StreamEvent objects:

The second way is to use the ToPartitionedStreamable methods, which are identical to ToTemporalStreamable methods mentioned above but with an additional method describing how to extract the partition information from the input data:

Parting is such sweet sorrow
So now data has been brought into Trill. Then using guidance from our other blog posts has been processed using your amazing query. It’s now time to get data back out of Trill and into an observable. Without having to worry about ordering, egressing data is a much simpler prospect. We already saw an example of egress in an earlier example:
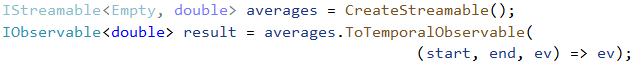
Let’s break this example down:
- The ToTemporalObservable method says that we want to create an observable output, and that we may want to peek at the temporal information when we do.
The lambda expression parameter in bold describes how to construct results for the observable. In this case we are dropping the time information because the example was about giving partial results of an average and the time component is less relevant, but we could have just as easily done something like this:
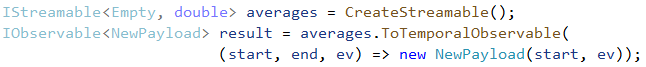
Alternatively, we can get results in the same StreamEvent form that we could use at ingress:
![]()
![]()
These two egress methods cover nearly all of the cases that most people will encounter when using Trill, but if you’d like to learn more about the more complicated egress methods, drop us a line.
Class is almost dismissed
We are always interested in identifying common patterns of time disorder that can be resolved at ingress. For instance, one pattern we have noticed but not yet implemented is future-outliers:
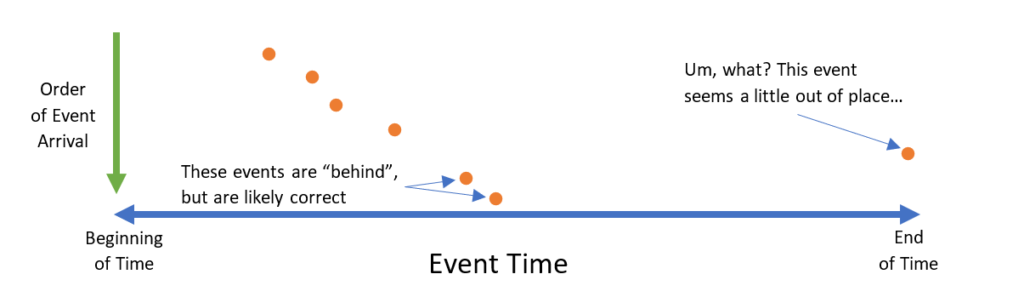
A data point may arrive seemingly so far out of order that it must be an error. For instance, what if a data point arrives that claims to be three years beyond the most recently seen timestamp? Such a situation could be caused by a network partition closing, or a new device coming online with a defective clock, or any number of other reasons. This pattern, among others, could be recognized at ingress time and dealt with in a user-defined way. Identifying and defining these patterns is a small task that is an excellent entry point for anyone who is interested in contributing to Trill.
In the meantime, our code can be found here, and our amazing samples can give you a good head start on programming over Trill. Reach out to us anytime if there’s something we can do to help you on your way. We hope to see you next time with our last entry in the Introduction to Trill blog series when we deep-dive into aggregation and pattern matching, possibly the most powerful feature Trill offers.