
For Microsoft’s internal teams and external customers, we store datasets that span from a few GBs to 100s of PBs in our data lake. The scope of analytics on these datasets ranges from traditional batch-style queries (e.g., OLAP) to explorative ”finding the needle in a haystack” type of queries (e.g., point-lookups, summarization).
Resorting to linear scans of these large datasets with huge clusters for every simple query is prohibitively expensive and not the top choice for many of our customers, who are constantly exploring ways to reducing their operational costs – incurring unchecked expenses are their worst nightmares. Over the years, we have seen a huge demand for bringing indexing capabilities that come de facto in the traditional database systems world into Apache Spark™. Today, we are making this possible by releasing an indexing subsystem for Apache Spark called Hyperspace – the same technology that powers indexing within Azure Synapse Analytics.

At a high-level, Hyperspace offers users the ability to:
- Build indexes on your data (e.g., CSV, JSON, Parquet).
- Maintain the indexes through a multi-user concurrency model.
- Leverage these indexes automatically, within your Spark workloads, without any changes to your application code for query/workload acceleration.
When running test queries derived from industry-standard TPC benchmarks (Test-H and Test-DS) over 1 TB of Parquet data, we have seen Hyperspace deliver up to 11x acceleration in query performance for individual queries. We ran all benchmark derived queries using open source Apache Spark™ 2.4 running on a 7-node Azure E8 V3 cluster (7 executors, each executor having 8 cores and 47 GB memory) and a scale factor of 1000 (i.e., 1 TB data).
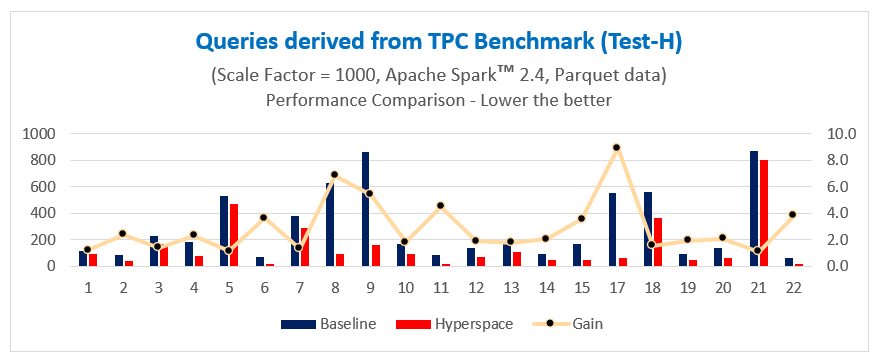
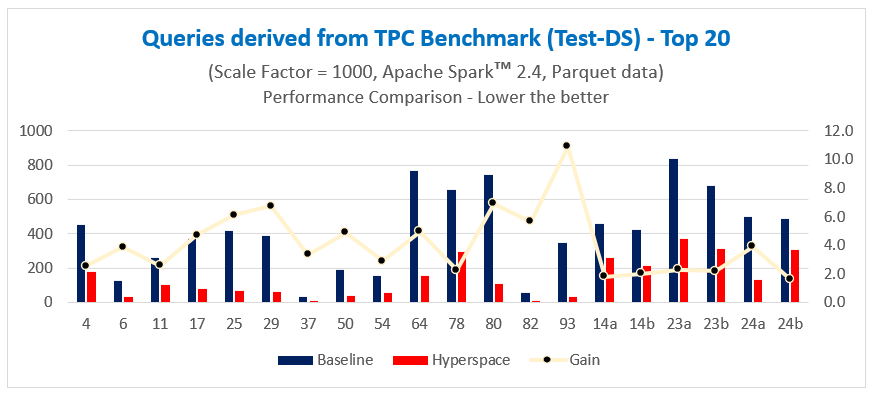
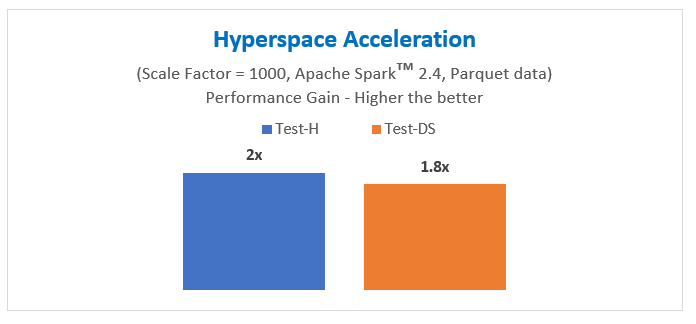
Overall, we have seen an approximate 2x and 1.8x acceleration in query performance time, respectively, all using commodity hardware.
To learn more about Hyperspace, check out our recent presentation at Spark + AI Summit 2020 and stay tuned for more articles on this blog in the coming weeks.
Learn more and explore Hyperspace:
- Check out the Hyperspace code on GitHub.
- Ready to try this out? Check out getting started guidance.
- Feel like contributing? Start with the current outstanding issues.