
Model training is an important step when developing and deploying large scale Artificial Intelligence (AI) models. Training typically utilizes a large amount of compute resources to tune the model based on the input dataset. Transformer models, with millions and billions of parameters, are especially compute-intensive and training costs increase with model size and fine-tuning steps required to achieve acceptable model accuracy. Reducing overall training time leads to efficient utilization of compute resources and faster model development and deployment.
ONNX Runtime (ORT) is an open source initiative by Microsoft, built to accelerate inference and training for machine learning development across a variety of frameworks and hardware accelerators. As a high-performance inference engine, ORT is part of core production scenarios for many teams within Microsoft, including Office 365, Azure Cognitive Services, Windows, and Bing.
During the Microsoft Build conference this year, we announced a preview feature of the ONNX Runtime that supports accelerated training capabilities of Transformer models for advanced language understanding and generation. Today, we’re introducing an open source training example to fine-tune the Hugging Face PyTorch GPT-2 model, where we see a speedup of 34% when training using the ONNX Runtime. We’re also sharing recently-released updates to the ONNX Runtime Training feature that further improve the performance of pre-training and fine-tuning.
The GPT-2 model and its applications
GPT-2 is a 1.5 billion parameter Transformer model released by OpenAI, with the goal of predicting the next word or token based on all the previous words in the text. There are various scenarios in the field of natural language understanding and generation where the GPT-2 model can be used. These capabilities stem from the fact that GPT-2 was trained with a causal language model objective on an extremely large corpus of data, which can be further fine-tuned to accomplish tasks involving the generation of coherent conditional long-form text. Some examples include machine-based language translation, creation of chatbots or dialog agents, or even writing joke punchlines or poetry.
The GPT-2 model has been pre-trained on a large corpus of text data with millions of internet webpages. This means the model can already perform tasks related to generating synthetic text based on this pre-training. However, for domain-specific tasks, GPT-2 benefits from fine-tuning with domain-specific data to improve the relevance and quality of the predicted text.
Depending on the application, the dataset for fine-tuning can be obtained from openly available public sources like the Reddit Pushshift big-data storage or the WikiText language modeling dataset. Other sources are book corpora, song lyrics, poems, or other publicly available text-based data. For certain classes of predictions, it is recommended that the fine-tuning be done on sample data that matches the target application. For example, if the goal is to create a chatbot, the fine-tuning dataset could include chat transcripts from real people involved in the domain-specific scenarios that the AI chatbot will handle.
Fine-tuning GPT-2 Medium with the ONNX Runtime
Hugging Face Transformers provides pre-trained models in 100+ languages for Natural Language Processing with deep interoperability for PyTorch or TensorFlow frameworks. The Hugging Face GPT-2 Medium model is a 345 million parameter English language model for language modeling and multiple choice classification. This pre-trained PyTorch model can be fine-tuned efficiently with ORT using Wikitext-103 data in Azure Machine Learning.
Wikitext-103 dataset is a collection of good quality articles from Wikipedia with punctuation, case, and numbers retained. Fine-tuning with this data set is expected to improve the quality of the predicted output of GPT-2. The steps in the example also discuss how to fine-tune GPT-2 Medium using a custom dataset or in any other environment.
The example discusses the initial setup of the model and the docker image to include changes needed to execute fine-tuning using the ONNX Runtime. It then provides instructions to download and transfer data to Azure Blob Storage and the Docker image to Azure Container Registry for running on Azure Machine Learning instances.
Alternatively, there is also guidance to build the image and the ONNX Runtime .whl file for executing in other environments. Once the machines are setup for execution, one can run the fine-tuning job on GPU optimized compute targets, like the Azure NDv2 or NCv3 VM series.
Accelerated Training Performance
When using ONNX Runtime for fine-tuning the PyTorch model, the total time to train reduces by 34%, compared to training with PyTorch without ORT acceleration. The run is an FP32 (single precision floating point using 32-bit representation) run with per GPU batch size 2. PyTorch+ORT allows a run with a maximum per-GPU batch size of 4 versus 2 for PyTorch alone.
These improvements are a result of ONNX Runtime natively incorporating innovations from the AI at Scale initiative, allowing efficient memory utilization and distributed training. It has also implemented graph optimizations and optimized device kernels that allow higher throughput and reduced training time. Detailed results from the finetuning runs are enclosed in the table below.
For comparable perplexity scores, we observe a reduction in both the global step time and the total time taken for fine-tuning the model. Perplexity refers to how well a model may predict sample data or the degree of uncertainty a model has in predicting text.
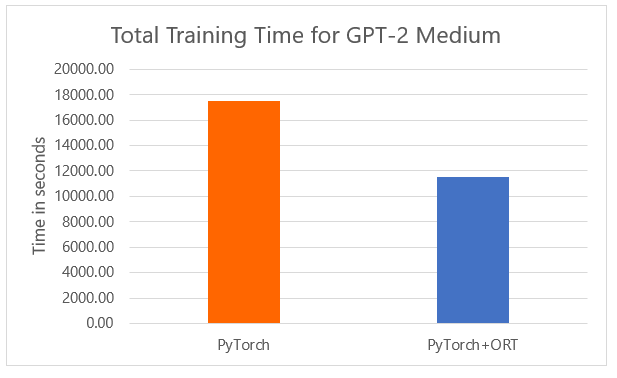
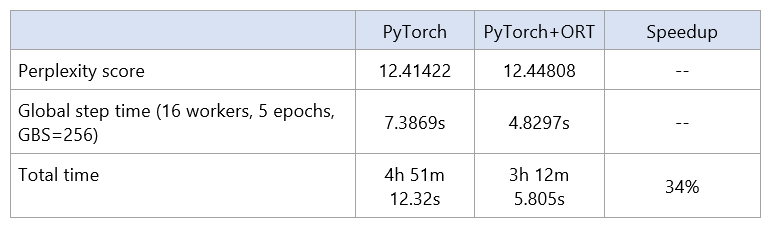
The PyTorch version used was 1.6 and the runs were performed using the Standard_ND40rs_v2 VM Size in Azure on a cluster with 2 nodes (16 GPUs – V100 32GB).
Features in the current update for ONNX Runtime training
We recently released updates that further improve Transformer model training performance, including optimized CUDA kernels and enabling fusion for certain operators. We have upgraded the existing Transformer training model examples to Opset 12. As part of the release, the Docker images are built from PyTorch 1.6, use the NVIDIA CUDA 10.2 base image and are now available for use in Microsoft Azure.
We encourage AI developers to try the GPT-2 Medium training example with the public data set in the example or with their customized data and share any feedback through GitHub about the ONNX Runtime. Looking forward, we plan to share more updates during Microsoft Ignite related to distributed training and large Transformer model training for the ONNX Runtime. Stay tuned!