
About two years ago, we heard an increasing demand from the .NET community for an easier way to build big data applications with .NET, outside of needing to learn Scala or Python. Thus, in a collaboration between Azure Data and .NET teams, we started the .NET for Apache® Spark™ open source project.
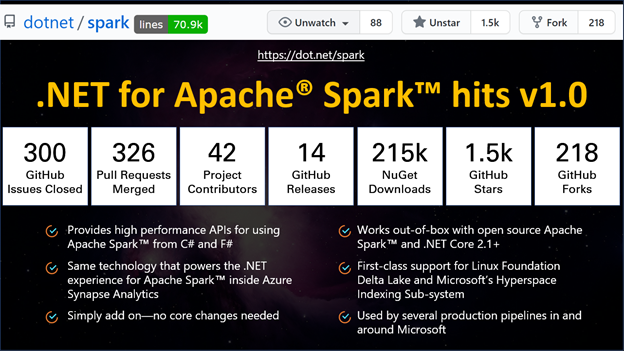
Today, we are happy to announce the release of version 1.0 of .NET for Apache Spark, an open source package that brings high performance APIs for using Apache Spark from C# and F#. Indeed, it is the same technology that powers the .NET experience for Apache Spark inside Azure Synapse Analytics.
At a high-level, .NET for Apache Spark offers users the ability to:
- Write Spark applications in C# or F# targeting .NET Core 2.1+.
- Reuse existing C#/F# libraries and use the power of Apache Spark to parallelize them.
- Leverage the high-quality Visual Studio or Visual Studio Code IDEs for building Spark apps.
The new .NET for Apache Spark v1.0 brings in additional capabilities to an already rich library:
- Support for DataFrame APIs from Spark 2.4 and 3.0.
- 47 new Spark SQL functions to support Spark 3.0 and 464 Spark SQL functions for Spark 2.4, bringing the total to 511 out-of-box Spark SQL functions to make it even easier for you to author Spark apps.
- First-class support for the Linux Foundation’s Delta Lake, Microsoft’s Hyperspace Indexing Sub-system, ML.NET, and support for Apache Spark’s MLLib functionality.
- Community-contributed Docker images that allow you to try and debug .NET for Apache Spark in a single-click, play with it using .NET Interactive notebooks, as well have a full-blown local development environment in your browser using VS Code so you can contribute to the open source project, if that’s of interest to you.
We are extremely grateful to everyone who contributed towards reaching this important milestone. For more about the history of the project, key contributors, and its use in production pipelines, read the full announcement.
To learn more about .NET for Apache Spark, check out our presentation at the Databricks’ Spark+AI Summit 2019, Microsoft Build 2019, SQLBits 2020, and the demo at Ignite 2020.
Learn more about .NET for Apache Spark:
- Check out the .NET for Apache Spark code on GitHub.
- Ready to try this out? Check out getting started.
- Feel like contributing? Start with the outstanding issues.
Don’t miss our presentation describing this major release in the upcoming .NET Conf 2020: “The Missing Piece: Diving into the World of Big Data with .NET for Apache Spark”!
Questions or feedback? Let us know in the comments below.