

Open sourcing MS-DOS 4.0
In partnership with IBM, we’re releasing the source code to MS-DOS 4.00…

At last year’s Microsoft Build conference in May 2020, Microsoft introduced three responsible AI (RAI) toolkits available in both open source as well as integrated within Azure Machine Learning: InterpretML, Fairlearn, and SmartNoise. These tools enable machine learning data scientists to understand model predictions, assess fairness, and protect sensitive data.
Building on this family of tools, we are announcing new capabilities for debugging inaccuracies in your model with the new Error Analysis toolkit and boost privacy using synthetic data in SmartNoise.
When analyzing machine learning models, we often focus on aggregate metrics such as accuracy. However, the model accuracy is often not uniform across subgroups of data and certain intersections of input conditions cause the model to fail more often. To improve accuracy, we need to dig in and evaluate these different sources of errors. Historically, troubleshooting these issues has been manual and time-consuming.
Introducing Error Analysis, the latest addition to the responsible AI open source toolkits. Error Analysis uses machine learning to partition model errors along meaningful dimensions to help you better understand the patterns in the errors. It enables you to quickly identify subgroups with higher inaccuracy and visually diagnose the root causes behind these errors.
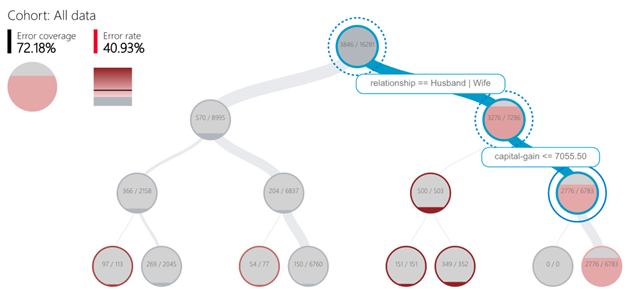
Use the tool to answer deep dive questions such as “Will the self-driving car recognition model still perform well even when it is dark and snowing outside?”
“Azure Machine Learning is used to support more SAS critical workflows, leading to increased requirements to efficiently debug and understand the models. We need tools to ensure the model performs equally well for all groups of individuals, and to understand not only feature importance but also the causality in model predictions. Error Analysis can potentially help us achieve just that and will be able to add great value.” —Kamran Chohan, Head of Artificial Intelligence, Scandinavian Airlines
While newly available to open source, Error Analysis is already an essential tool in AI development at Microsoft. Error Analysis started as a research project in 2018 as a collaboration with Microsoft Research and the AI, Ethics, and Effects in Engineering and Research (AETHER) Committee. In 2019, the team collaborated closely with the Microsoft Mixed Reality group to make the tool part of the internal AI infrastructure. The open source release was made possible by the RAI tooling team in Azure Machine Learning, who are passionate about democratizing Responsible AI. Looking forward, Error Analysis together with other RAI toolkits will also come under a larger model assessment dashboard available in both OSS and Azure Machine Learning by mid 2021.
Differential privacy is the emerging gold standard technology for protecting personal data while allowing data scientists to extract useful statistics and insights from the dataset. SmartNoise is an open source toolkit jointly developed by Microsoft and Harvard, as part of the Open Differential Privacy initiative.
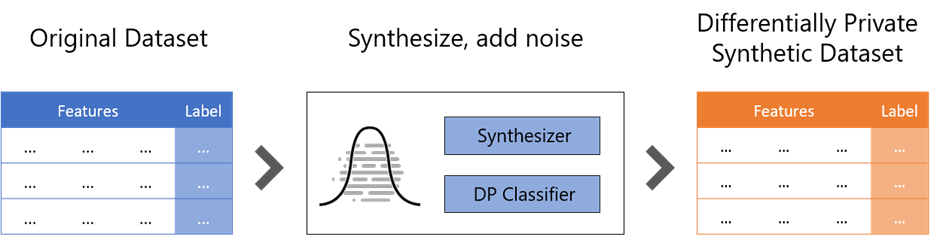
With the new release of SmartNoise led by Andreas Kopp, you can use differential privacy to not only protect individual’s data but also the full dataset using the new synthetic data capability. A synthetic dataset represents a manmade sample derived from the original dataset while retaining as many statistical characteristics as possible. The original dataset combined with the synthetic one together produces a differentially private synthetic dataset that can be analyzed many times without increasing the privacy risk. This enables increased collaboration between several parties, democratized knowledge, and open dataset initiatives.
Join us at Open Data Science Conference webinar to see privacy-preserving machine learning in action. Moreover, we’ll show you how to create differentially private synthetic data with the newest release of SmartNoise.

The work doesn’t stop here. We continue to expand the capabilities in FairLearn, InterpretML, Error Analysis, and SmartNoise. We hope you’ll join us on GitHub and contribute directly to helping everyone build AI responsibly. The next innovation we feature could be yours!
Learn more about Microsoft’s contributions to Responsible AI:
In partnership with IBM, we’re releasing the source code to MS-DOS 4.00…

Our focus this past year has been on security, business excellence in…

Join Microsoft at Open Source Summit North America 2024, taking place in…

Microsoft is excited to be able to support and contribute to the…
Notifications