This blog was co-authored with Manash Goswami, Principal Program Manager, Machine Learning Platform.

The performance improvements provided by ONNX Runtime powered by Intel® Deep Learning Boost: Vector Neural Network Instructions (Intel® DL Boost: VNNI) greatly improves performance of machine learning model execution for developers. In the past, machine learning models mostly relied on 32-bit floating point instructions using AVX512. Now, machine learning models can use 8-bit integer instructions (Intel® DL Boost: VNNI) to achieve substantial speed increases without significant loss of accuracy. To fully understand these performance improvements, you must first understand ONNX Runtime, Bi-Directional Encoder Representations from Transformers (BERT), Intel DL Boost: VNNI, and steps to achieve the best performance with ONNX Runtime on Intel platforms. Keep reading to learn more about accelerating BERT model inference with ONNX Runtime and Intel® DL Boost: VNNI.
What is ONNX Runtime?
ONNX Runtime is an open-source project that is designed to accelerate machine learning across a wide range of frameworks, operating systems, and hardware platforms. It enables acceleration of machine learning inferencing across all of your deployment targets using a single set of APIs.1Intel has partnered with the Microsoft ONNX Runtime team to add support for Intel® DL Boost and take advantage of microarchitectural improvements, such as non-exclusive caches on the new 11th Gen Intel® Core™ processors to significantly improve performance. Read more to learn how to achieve the best performance using Intel® Deep Learning Boost: VNNI on ONNX Runtime’s default CPU backend (Microsoft Linear Algebra Subroutine (MLAS)).
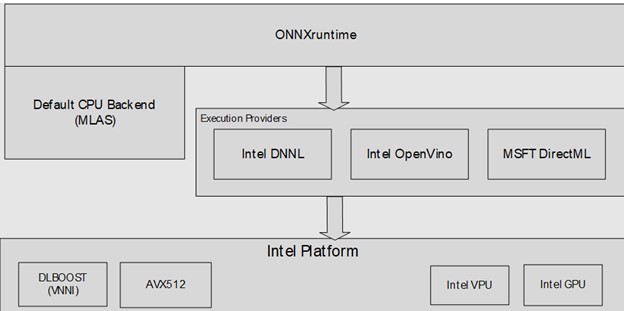
Figure 1: ONNX Runtime Architecture
What is BERT?
BERT was originally created and published in 2018 by Jacob Devlin and his colleagues at Google. It’s a machine learning technique that greatly improves machine natural language processing (NLP) capabilities. This technique does not process individual words (as previously done), but instead, it processes complete sentences. Machine learning models can now understand the relationship between words within a sentence and understand the context of a sentence. This approach to neuro-linguistic programming (NLP) has revolutionized language processing tasks such as search, document classification, question answering, sentence similarity, text prediction, and more. BERT class models are widely applied in the industry. Recently techniques such as knowledge distillation and quantization have been successfully applied to BERT, making this model deployable on Windows PCs.
What is Deep Learning Boost: VNNI?
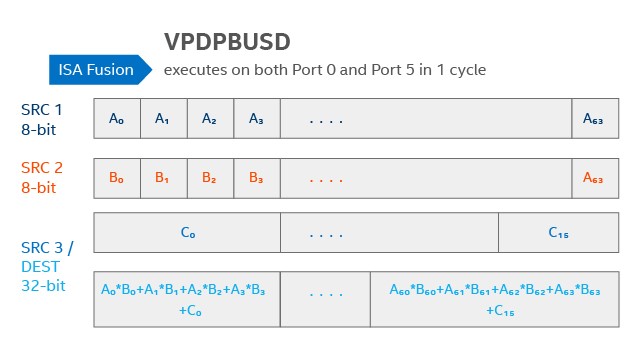
Intel Deep Learning Boost: VNNI is designed to deliver significant deep learning acceleration, as well as power-saving optimizations. A single vector instruction (such as VPDPBUSD) can be used to multiply two 8-bit integers and combining the result into a 32-bit output.
Steps to build and execute ONNX Runtime for Windows 10 on 11th Gen Intel® Core™ Processors
Pre-requisites:
- Install Python 3.8.
- Install jupyter notebook.
Preparing the model:
In the Command Line terminal, open the jupyter notebook:
jupyter notebookOnce the notebook opens in the browser, run all the cells in notebook and save the quantized INT8 ONNX model on your local machine.
Build ONNXRuntime:
When building ONNX Runtime, developers have the flexibility to choose between OpenMP or ONNX Runtime’s own thread pool implementation. For achieving the best performance on Intel platforms, configure ONNX Runtime with OpenMP and later explicitly define the threading policy for model inference.
In the Command Line terminal:
git clone --recursive https://github.com/Microsoft/ONNXRuntime cd ONNXRuntime Install cmake-3.13 or higher from https://cmake.org/download/ .\build.bat --config RelWithDebInfo --build_shared_lib –parallel --use_openmpTuning Performance for ONNX Runtime’s Default Execution Provider:
In conditions where threading can be explicit, it is recommended to parallelize threads, binding each thread to separate physical cores. On platforms where hyperthreading is enabled, the recommendation is to skip alternate cores (if the number of threads needs to be less than the number of logical cores). This reduces the overhead of cache thrashing caused by repeated thread swapping between cores.
For Windows, use “start /affinity AA” to keep four threads of ONNX Runtime on physical cores by skipping alternate logical cores. To explicitly fix the number of threads OMP_NUM_THREADS environment variable is used. For example, in the Command Line terminal:
set KMP_AFFINITY=granularity=fine,compact,1,0 set OMP_NESTED=0 set OMP_WAIT_POLICY=ACTIVE set /a OMP_NUM_THREADS=4Run the quantized model with ONNX Runtime:
When executing the runtime, you need to place a folder in the same directory as the runtime with the input test dataset you want to use. For illustration purposes, we will generate a random test input dataset with the following python script which we will name generate_test_data_set.py:
import numpy as np from onnx import numpy_helper batch_range = [1,2, 4, 8, 16] for batch in range(len(batch_range)): for seq in [20,32,64]: numpy_array = np.random.rand(batch_range[batch],seq).astype(np.int64) tensor = numpy_helper.from_array(numpy_array) name = "input_0_" + str(batch_range[batch]) +"_"+ str(seq) + ".pb" f = open(name, "wb") f.write(tensor.SerializeToString()) f.close() name = "input_1_" + str(batch_range[batch]) +"_"+ str(seq) + ".pb" f = open(name, "wb") f.write(tensor.SerializeToString()) f.close() name = "input_2_" + str(batch_range[batch]) +"_"+ str(seq) + ".pb" f = open(name, "wb") f.write(tensor.SerializeToString()) f.close() print (name)In the Command Line terminal:
python generate_test_data_set.pyThis will generate test data set for three inputs for BERT base:
- input_0_<batch_size>_<seqLength>.pb
- input_1_<batch_size>_<seqLength>.pb
- input_2_<batch_size>_<seqLength>.pb
Create a new folder ‘test_data_set_0’ folder in the same location as the ONNX model Files. Make sure no other folder exists in the same location. Copy the three inputs of the SAME sequence and batch length to the test_data_set_0 folder.
In the test_data_set_0 folder, rename
- input_0_<batch_size>_<seqLength>.pb to input_0.pb
- input_1_<batch_size>_<seqLength>.pb to input_1.pb
- input_2_<batch_size>_<seqLength>.pb to input_2.pb
Now run ONNX Runtime. In the Command Line terminal:
cd&lt;root&gt;\onnxruntime\build\Windows\RelWithDebInfo\RelWithDebInfo onnxruntime_perf_test.exe -m times -r&lt;#iterations&gt;-o 99 -e cpu MODEL_NAME.onnxRepeat steps for the next set of batch and seq lengths.
Get extensive details about ONNX Runtime inference.
Results
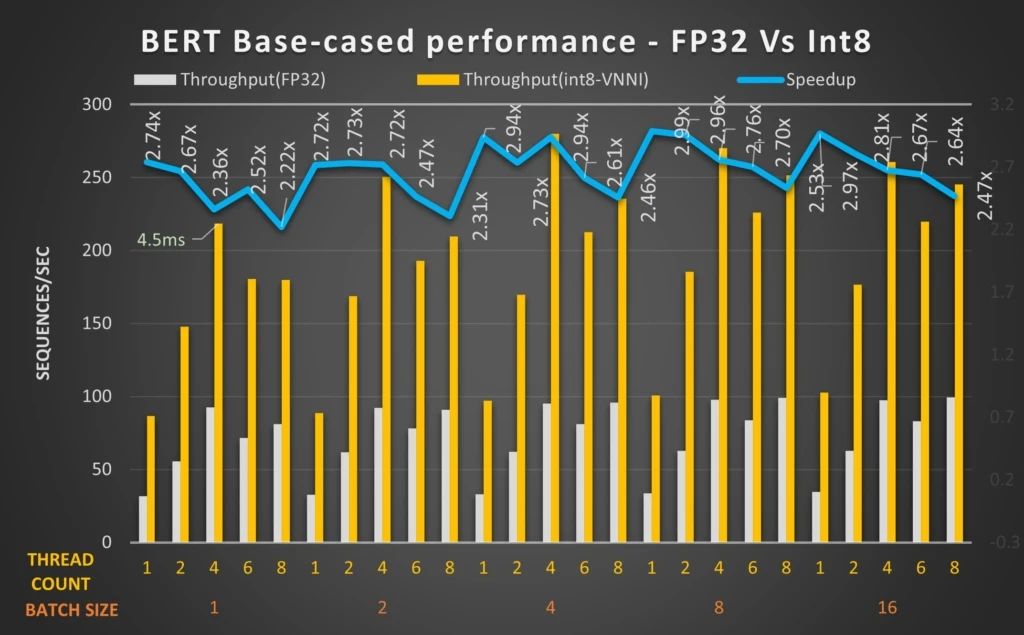
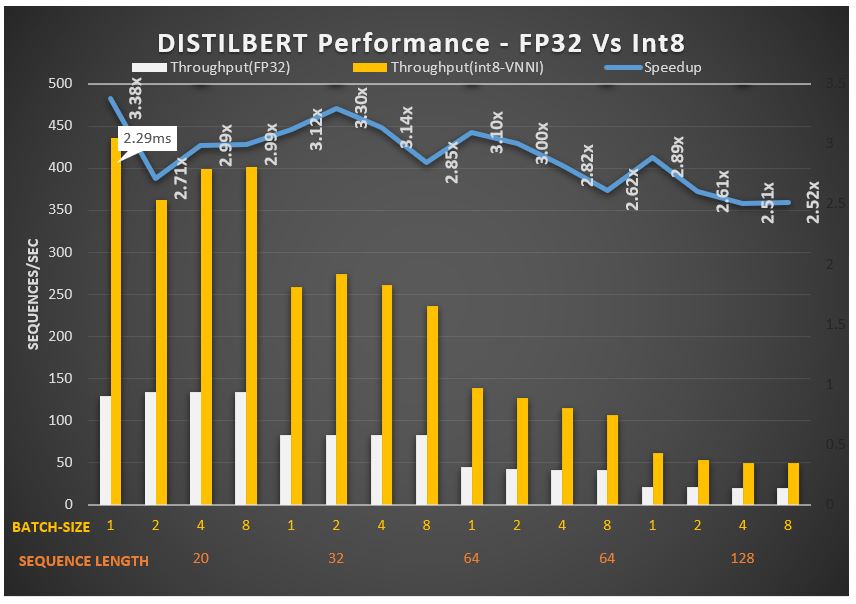
With Intel® DL Boost: VNNI and ONNX Runtime, developers can significantly increase throughput and performance for transformer-based Natural Language Processing models with quantization. For example, the quantized BERT 12-layer model with Intel® DL Boost: VNNI and ONNX Runtime can achieve up to 2.9 times performance gains. The Distilled BERT can achieve up to 3.3 times performance gains.
To participate, check out GitHub repos located on ONNX Runtime.
BERT 12-layer language processing workload on 11th Gen Intel® Core™ processor get increased speeds up to 2.9 times with DLBoost: VNNI
Distilled BERT model achieves 3.38 times increased speeds due to DLBoost: VNNI (Number of threads = four)
1https://microsoft.github.io/onnxruntime/about.html, 10/1/2020