
This post was co-authored by Alejandro Saucedo, Director of Machine Learning Engineering at Seldon Technologies.
About the co-author: Alejandro leads teams of machine learning engineers focused on the scalability and extensibility of machine learning deployment and monitoring products with over five million installations. Alejandro is also the Chief Scientist at the Institute for Ethical AI and Machine Learning, where he leads the development of industry standards on machine learning explainability, adversarial robustness, and differential privacy. With over 10 years of software development experience, Alejandro has held technical leadership positions across hyper-growth scale-ups and has a strong track record building cross-functional teams of software engineers.
As organizations adopt machine learning in production, they face growing challenges that arise when the number of production machine learning models starts to increase. In this article, we provide a practical tutorial that will enable AI practitioners to leverage production-ready workflows to deploy their machine learning models at scale. More specifically, we will demonstrate the benefits of open source tools and frameworks like ONNX Runtime, Seldon Core, and HuggingFace, as well as how these can be integrated with Azure Kubernetes Services to achieve robust and scalable machine learning operations capabilities.
By the end of this blog post, you will have a simple, repeatable, and scalable process to deploy complex machine learning models. You will learn by example, deploying the OpenAI GPT-2 natural language processing (NLP) model as a fully-fledged microservice with real-time metrics, and robust monitoring capabilities. Try out our GPT-2 Azure AKS Deployment Notebook that demonstrates the full process.
The steps that will be carried out in this blog are outlined in the image below, and include the following:
- Fetch the pre-trained GPT2 Model using HuggingFace and export to ONNX.
- Setup Kubernetes Environment and upload model artifact.
- Deploy ONNX Model with Seldon Core to Azure Kubernetes Service.
- Send inference requests to Kubernetes deployed GPT2 Model.
- Visualize real-time monitoring metrics with Azure dashboards.

Furthermore, the tools that we’ll be using in this framework will be the following:
- Seldon Core: A machine learning model deployment and monitoring framework for Kubernetes which will allow us to convert our model artifact into a scalable microservice with real-time metrics.
- ONNX Runtime: An optimized runtime engine to improve the performance of model inference, which we’ll be using to optimize and run our models.
- Azure Kubernetes Service (AKS): Azure’s managed Kubernetes service, where we will be running the deployed machine learning models.
- Azure Monitor: Azure’s service for managed monitoring, where we will be able to visualize all the performance metrics.
- HuggingFace: An ecosystem for training and pre-trained transformer-based NLP models, which we will leverage to get access to the OpenAI GPT-2 model.
Let’s get started.
1. Fetch the trained GPT-2 Model with HuggingFace and export to ONNX
GPT-2 is a popular NLP language model trained on a huge dataset that can generate human-like text. We will use Hugging Face’s utilities to import the pre-trained GPT-2 tokenizer and model. First, we download the tokenizer as follows.
from transformers import GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
Now we can download the GPT2 Tensorflow model and export it to deploy it:
from transformers import GPT2Tokenizer,
TFGPT2LMHeadModel tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = TFGPT2LMHeadModel.from_pretrained("gpt2", from_pt=True, pad_token_id=tokenizer.eos_token_id)
model.save_pretrained("./tfgpt2model", saved_model=True)
Finally, we convert it and optimize it for ONNX Runtime with the command below:
python -m tf2onnx.convert --saved-model ./tfgpt2model/saved_model/1 --opset 11 --output model.onnx
One of the main advantages of using the ONNX Runtime is the high-performance inference capabilities and broad compatibility that it brings. The ONNX Runtime enables practitioners to use any machine learning framework of their choice, and convert it to the optimized Open Neural Network Exchange (ONNX) format. Once these models are converted, the ONNX Runtime can be used to deploy it to a variety of targets including desktop, IoT, mobile, and in our case Azure Kubernetes through Seldon Core.
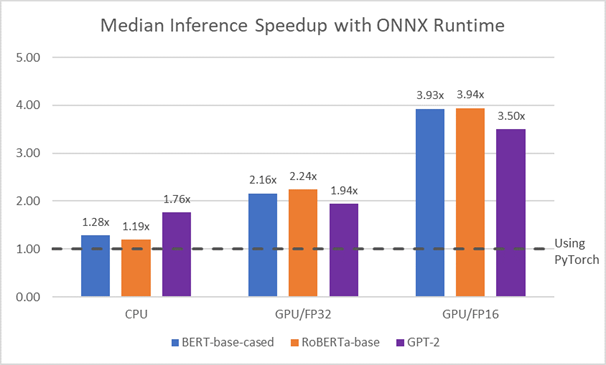
This framework has benefited from a broad range of rich benchmarks that showcase the high throughput and low latencies that can be achieved, which you can see in “Accelerate your NLP pipelines using Hugging Face Transformers and ONNX Runtime”, as well as in “Faster and smaller quantized NLP with Hugging Face and ONNX Runtime”.
2. Setup Kubernetes environment and upload model artifact
Seldon Core is one of the leading open-source frameworks for machine-learning model deployment and monitoring at scale on Kubernetes. It allows machine learning practitioners to convert their trained model artifacts or machine learning model code into fully-fledged microservices. All models deployed with Seldon are enabled with advanced monitoring, robust promotion strategies, and scalable architectural patterns. We will be using Seldon Core to deploy our GPT-2 model.
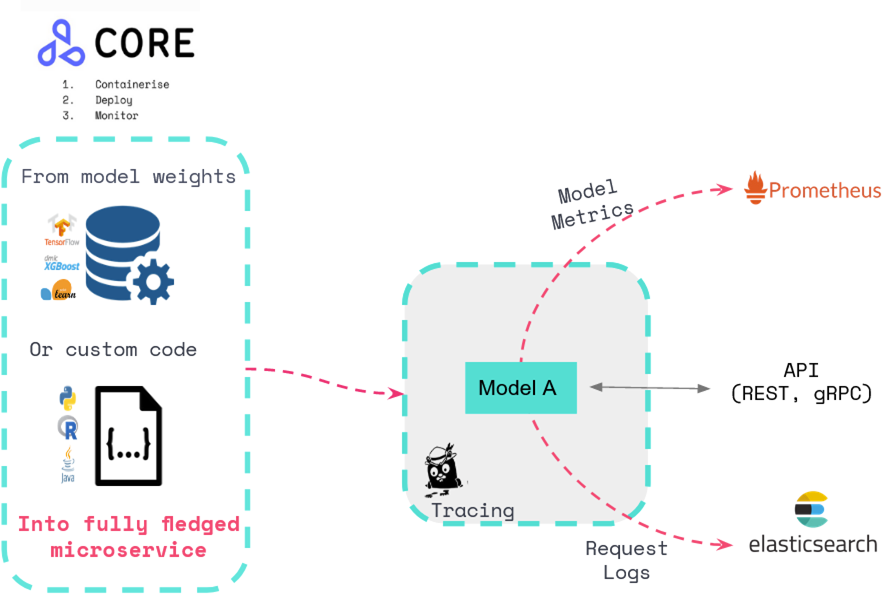
Seldon provides out-of-the-box a broad range of Pre-Packaged Inference Servers to deploy model artifacts to TFServing, Triton, ONNX Runtime, etc. It also provides Custom Language Wrappers to deploy custom Python, Java, C++, and more. In this blog post, we will be leveraging the Triton Prepackaged server with the ONNX Runtime backend. In order to set up Seldon Core in you can follow Seldon core setup instructions.
Setting Up the Azure Kubernetes Environment
The following diagram depicts our target architecture utilizing Azure Kubernetes Service (AKS)—fully-managed Kubernetes service provided on Azure which removes the complexity of managing infrastructure and allows developers and data scientists to focus on machine learning models.
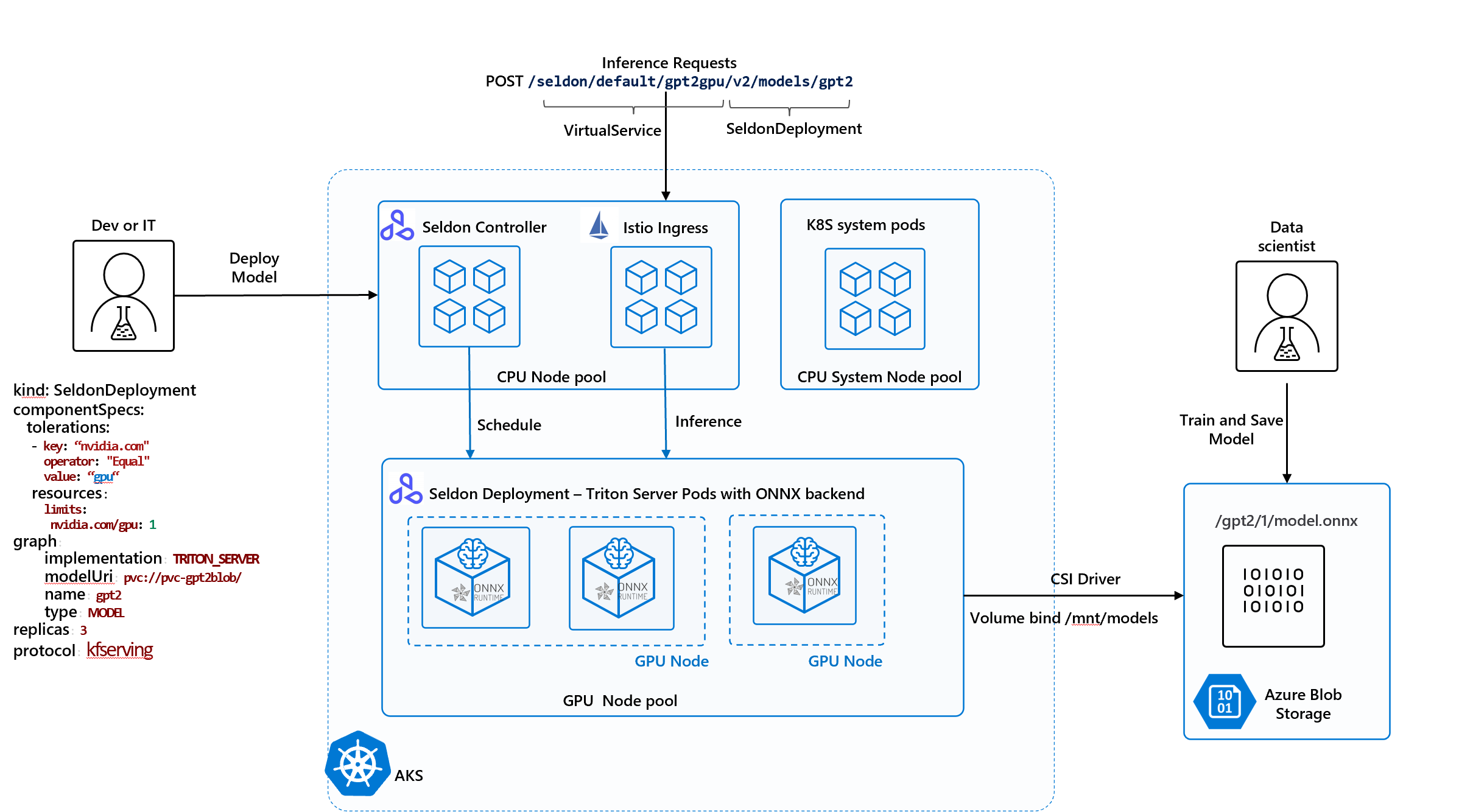
We recommend creating an AKS cluster with three node pools and installed CSI driver—refer to the following notebook for the scripts which you can run yourself (Azure Setup Notebook):
- CPU System Nodepool: running Kubernetes system components.
- CPU User Nodepool: running Seldon Operator and Istio components.
- GPU User Nodepool: running machine learning model inference with GPU hardware optimizations.
- Azure Blob CSI driver mounting Azure Storage Account for model hosting.
Upload model artifacts
Seldon is able to automatically download your model artifacts from an object store, so we will start by uploading our model in Azure blob storage. To abstract away details of storage connection from SeldonDeployment, we will be able to use the PersistentVolume reference in our model manifest, which will be mounted with our model container. For details on setting up PersistentVolume for Azure Blob with Blob CSI driver refer to our example here. We can then upload ONNX model file to Azure Blob following the default directory structure as per the Triton model repository format:

3. Deploy to Kubernetes (AKS) with Seldon Core
Now, we are ready to deploy our model using Seldon Core’s Triton pre-packaged server. For that we need to define and apply a SeldonDeployment for prepackaged Triton server Kubernetes manifest file as shown below:
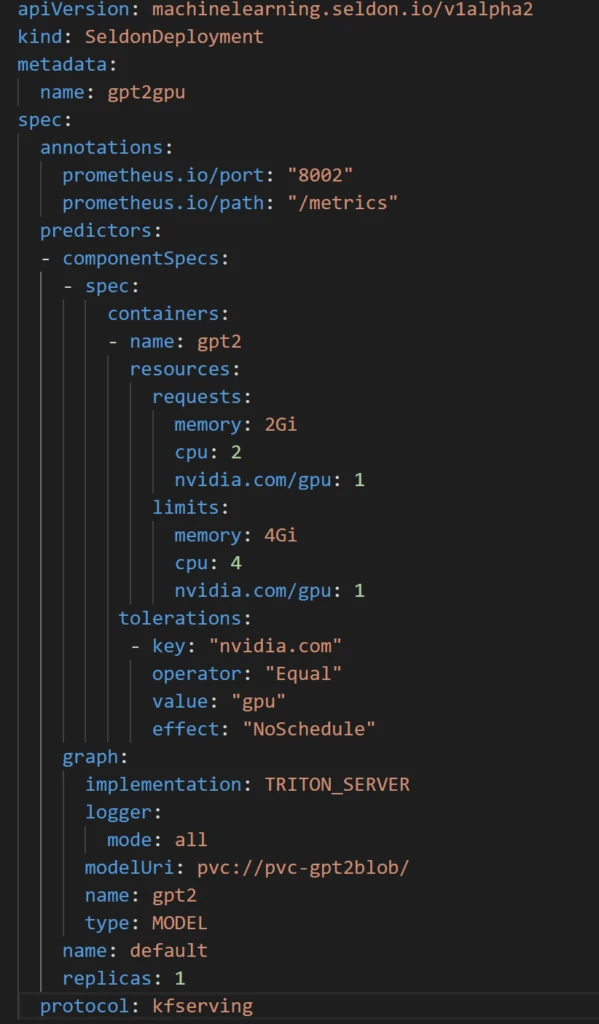
Some of the key attributes to notice:
- implementation field is set to `TRITON_SERVER`.
- ‘model_url’ points to PVC to download the model (<pvc>://<name>).
- ‘name’ field is GPT-2 to instruct what model to download.
- ‘componentSpecs’ override Pod spec fields such as limits/requests and tolerations to instruct Kubernetes scheduler to run the Pods on GPU nodes.
- ‘protocol’ field is using the widely adopted inference protocol.
- annotations direct Azure Monitor to scrape real-time metrics.
Once you deploy it, you can verify the logs as follows:
kubectl logs <podname> -c gpt2 ============================= == Triton Inference Server == ============================= I0531 14:01:19.977429 1 metrics.cc:193] GPU 0: Tesla V100-PCIE-16GB I0531 14:01:19.977639 1 server.cc:119] Initializing Triton Inference Server I0531 14:01:21.819524 1 onnx_backend.cc:198] Creating instance gpt2_0_gpu0 on GPU 0 (7.0) using model.onnx I0531 14:01:24.692839 1 model_repository_manager.cc:925] successfully loaded 'gpt2' version 1 I0531 14:01:24.695776 1 http_server.cc:2679] Started HTTPService at 0.0.0.0:9000
4. Run inference requests with your deployed model
Now that we have deployed our model, we are able to perform text generation in real-time. This can be done by sending REST requests directly against our productionized model; however, we’ll have to carry out a couple of steps first: namely tokenization of our input, then sending the request, and then decoding the resulting tokens. This is shown in detail below.
- Tokenize the input sentence using Hugging Face GPT-2 pre-trained tokenizer:
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
input_text = 'I love Artificial Intelligence'
token_input = tokenizer.encode(gen_sentence, return_tensors='tf')
- Now we can send the tokens by constructing the input payload:
payload = # ...input payload
shape = input_ids.shape.as_list()
payload = {
"inputs": [
{"name": "input_ids:0",
"datatype": "INT32",
"shape": shape,
"data": input_ids.numpy().tolist()
},
...
]
}
res = requests.post(
'http://<ingressIP>/seldon/seldon/gpt2gpu/v2/models/gpt2/infer',
json=payload
)
- Our GPT-2 model will return the probability distribution for the next token over the vocabulary for the input vector (logits). Following the “greedy” approach we decode the response to a string and append to the input sentence.
next_token_str = postprocess_response(res) generated_sentence += ' ' + next_token_str
- We repeat this to generate the full synthetic sentence:
'I love Artificial Intelligence. I love the way it’s designed'
The full end-to-end implementation could be found in our GPT-2 Notebook.
5. Visualize monitoring metrics with Azure Monitor
We are now able to visually monitor the real-time metrics generated by our Seldon Model by enabling Azure Monitor Container Insights in the AKS cluster. We can navigate to the insights blade page and check whether resources/limits configured for SeldonDeployment are within the healthy thresholds and monitor the changes in Memory or CPU during model inference.
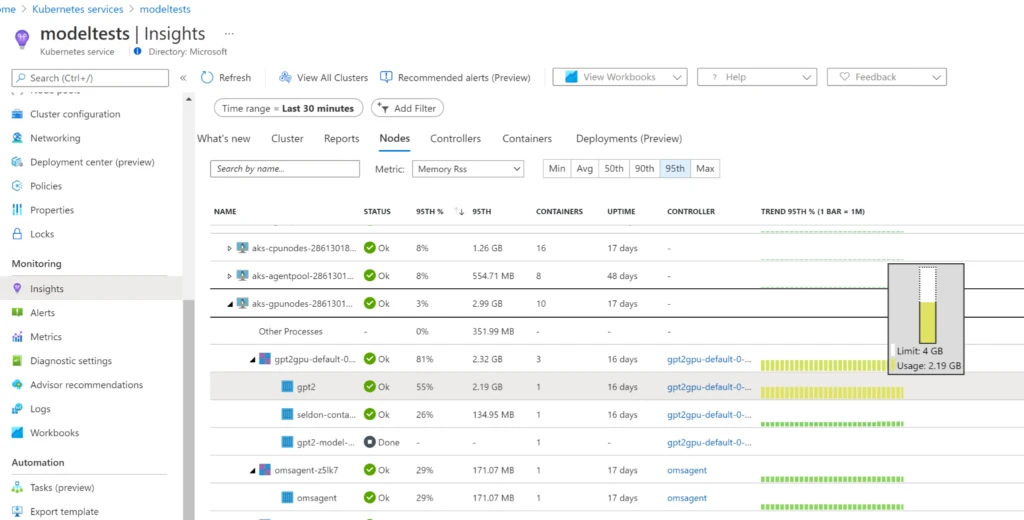
In addition to container metrics, we can collect the specialized metrics generated by Seldon Triton orchestrator. Azure Monitor Container Insights provides out-of-the-box ability to scrape Prometheus metrics from declared endpoints, no need to install and operate Prometheus server. To learn more see Microsoft docs—Prometheus metrics with Container insights. For our case we can now visualize the real-time metrics with specialized dashboards as demonstrated in our GPT-2 Notebook and the following example dashboard:
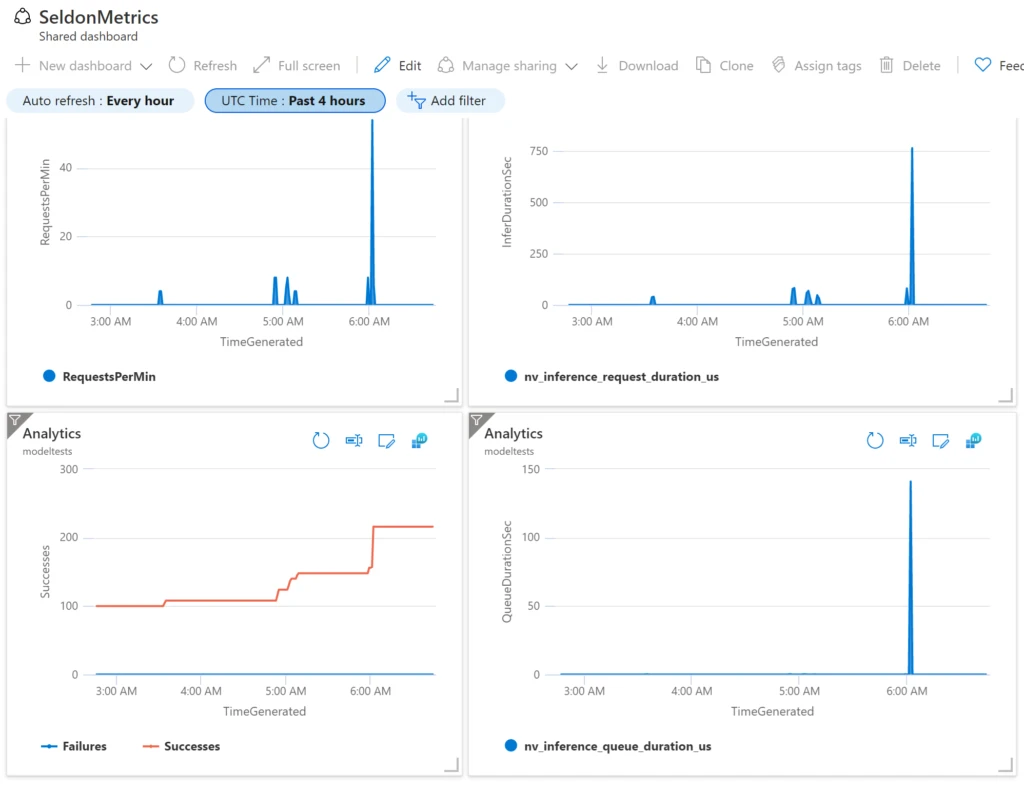
Uncover repeatable ML deployment processes today
In this blog, we have been able to cover a repeatable and scalable process to deploy a GPT-2 NLP model as a fully-fledged microservice with real-time metrics to enable observability and monitoring capabilities at scale using Seldon Core in Azure.
More specifically, we were able to:
- Fetch the trained GPT-2 Model with HuggingFace and export to ONNX.
- Setup Kubernetes Environment and Upload Model Artifact.
- Deploy ONNX Model with Seldon Core to Azure Kubernetes Service.
- Send requests to generate text with deployed GPT-2 Model.
- Visualize monitoring metrics with Azure dashboards.
These workflows are continuously being refined and evolved through the Seldon Core open source project, and advanced state-of-the-art algorithms on outlier detection, concept drift, explainability, and more are improving continuously—if you are interested in learning more or contributing please feel free to reach out. If you are interested in further hands-on examples of scalable deployment strategies of machine learning models, you can check out:
- Production machine learning monitoring: Outliers, drift, explainers, and statistical performance.
- Real-time machine learning at scale using SpaCy, Kafka, and Seldon Core.
- Seldon Core quick-start documentation.