
This post was co-authored by Jithun Nair and Aswin Mathews, members of technical staff at AMD.
In recent years, large-scale deep learning models have demonstrated impressive capabilities, excelling at tasks across natural language processing, computer vision, and speech domains. Companies now use these models to power novel AI-driven user experiences across a whole spectrum of applications and industries. However, efficiently training large models with 10’s or 100’s of billions of parameters is difficult—the sheer size of these models requires them to be distributed across multiple nodes with careful orchestration of compute and communication.
DeepSpeed, as part of Microsoft’s AI at Scale initiative, is a popular open-source library for PyTorch that addresses these difficulties and vastly improves the scale, speed, cost, and usability of large model training and inference. It addresses the scaling challenges by allowing users to easily apply a powerful suite of compute, memory, and communication optimization techniques with minimal code changes. With these techniques, DeepSpeed has enabled training the largest transformer model with 530 billion parameters for language generation and helped speed-up training and inference time by a factor of two times to 20 times for real-life scenarios. It is also integrated into popular training libraries like HuggingFace Transformers and PyTorch Lightning.
Since 2006, AMD has been developing and continuously improving their GPU hardware and software technology for high-performance computing (HPC) and machine learning. Their open software platform, ROCm, contains the libraries, compilers, runtimes, and tools necessary for accelerating compute-intensive applications on AMD GPUs. Today, the major machine learning frameworks (like PyTorch, TensorFlow) have ROCm supported binaries that are fully upstreamed so that users can directly run their code written using these frameworks on AMD Instinct GPU hardware and other ROCm compatible GPU hardware—without any porting effort.
AMD has worked closely with the Microsoft DeepSpeed team to bring the suite of parallelization and optimization techniques for the training of large models efficiently on AMD GPUs supporting ROCm. This unlocks the ability to efficiently train models with hundreds of billions of parameters on a wide choice of GPU hardware and system configurations ranging from a single desktop to a distributed cluster of high-performance AMD Instinct™ MI100/MI200 accelerators.
Enabling state-of-the-art DL Stack on AMD GPU
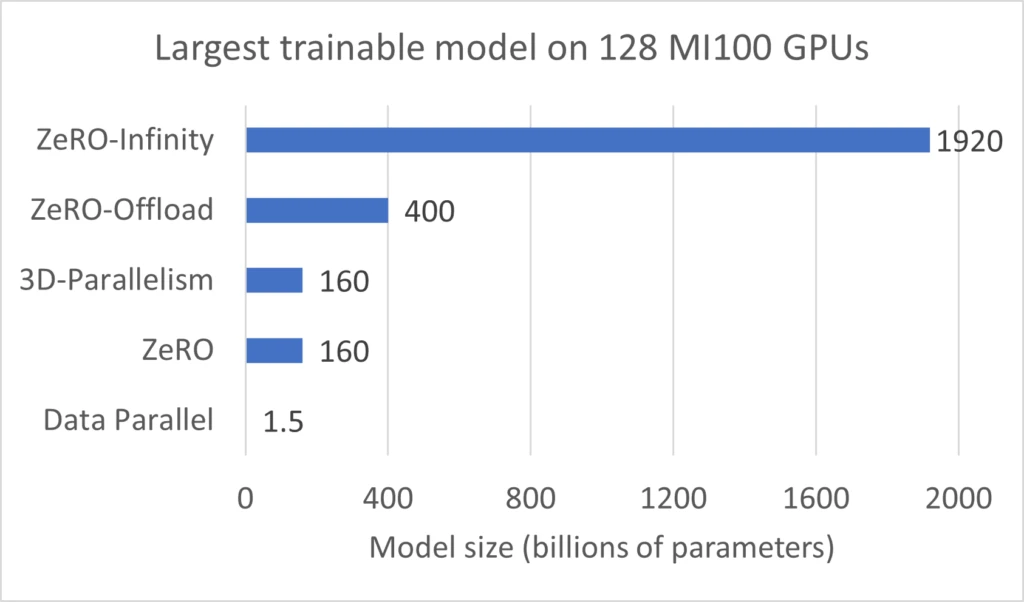
As an effective enabler of large model training, DeepSpeed provides a suite of powerful parallelism and memory optimizations, such as ZeRO, ZeRO-Offload, ZeRO-Infinity, and 3D parallelism, which are crucial for efficient training at massive model scales. With DeepSpeed, model scientists can significantly scale up their model sizes on AMD GPUs well beyond the limits of pure data parallelism. As an example, figure 1 shows model sizes that can be trained using 128 MI100 GPUs (on eight nodes) using different DeepSpeed optimizations. In general, each DeepSpeed optimization enables model scaling of two orders of magnitude compared to the 1.5 billion parameters limits of data parallelism. At the extreme, ZeRO-Infinity powers models with nearly 2 trillion parameters.
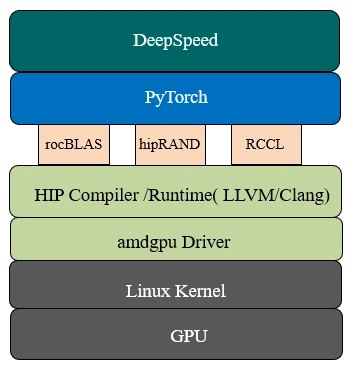
To achieve the optimizations in compute, memory, and communication, DeepSpeed makes use of HIP (language/runtime), rocBLAS (for GEMMs), and RCCL (for communication) libraries in the ROCm stack. The following figure shows how DeepSpeed interacts with AMD’s ROCm software stack. It requires a version of PyTorch that is built for ROCm.
Through careful work across both AMD and Microsoft engineers, we are proud to announce that DeepSpeed v0.6 works natively with ROCm-enabled GPUs. This new release of DeepSpeed uses the same APIs as prior releases and does not require any user code changes to leverage the full features of DeepSpeed on ROCm-enabled GPUs. DeepSpeed’s python-level code remains unchanged primarily due to the seamless ROCm experience on PyTorch. DeepSpeed’s CUDA-specific kernels are exposed to users through ROCm’s automatic hipification tools embedded in the PyTorch runtime. This automatic hipification allows DeepSpeed users to continue to enjoy a simple install through PyPI and just-in-time (JIT) hipification and compilation at runtime if or when kernels are utilized by end-users. In addition, ROCm has become an integral part of DeepSpeed’s continuous integration (CI) testing, which will elevate ROCm support in DeepSpeed for all future pull requests and new features.
Power efficient distributed training of large models
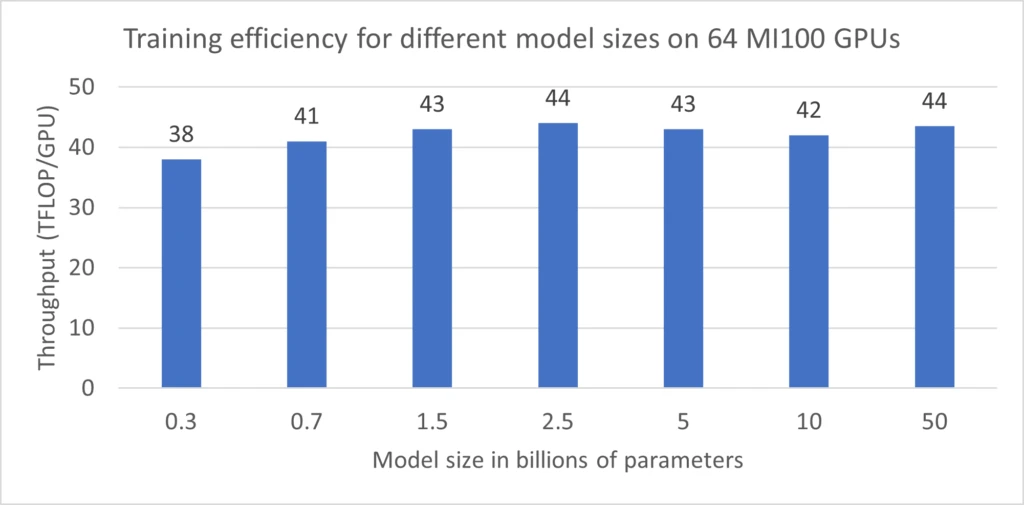
DeepSpeed enables high training efficiency while running distributed training for large models with billions of parameters across multiple MI100 GPUs and nodes. For example, figure 3 shows that on 8 MI100 nodes/64 GPUs, DeepSpeed trains a wide range of model sizes, from 0.3 billion parameters (such as Bert-Large) to 50 billion parameters, at efficiencies that range from 38TFLOPs/GPU to 44TFLOPs/GPU.
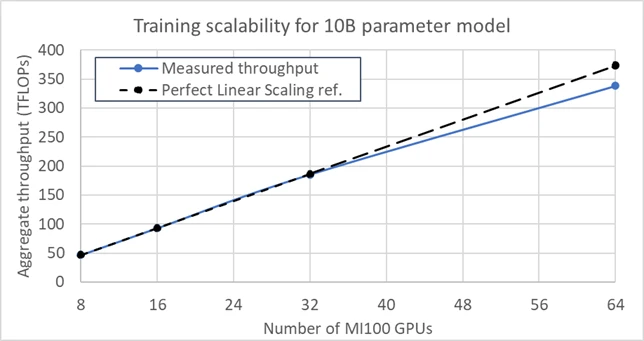
DeepSpeed also empowers MI100 GPUs to obtain good training scalability for large models as the number of GPUs increases. For example, the plot below in figure 4 shows that for training a 10B parameter model on up to 64 MI100 GPUs, DeepSpeed achieves a throughput scaling (weak scaling) that is close to perfect linear speedup.
Democratizing large model training
An important democratizing feature of DeepSpeed is the ability to reduce the number of GPUs required to fit large models by offloading model states to the central processing unit (CPU) memory and NVMe memory. Offloading makes large models accessible to users with a limited GPU budget by enabling the training (or finetuning) of models with 10s or 100s of billions of parameters on a single node. Below, we briefly provide a flavor of the model scaling that DeepSpeed enables on a single MI100 GPU.
Efficient model scaling on single GPU
The figure below shows that ZeRO-Offload (such as offloading to CPU memory) can train much larger models (such as 12B parameters), on a single MI100 GPU, compared to the baseline PyTorch which runs out of memory (OOM) for models larger than 1.2B parameters. Moreover, ZeRO-Offload sustains higher training throughput (41—51 TFLOPs) than PyTorch (30 TFLOPs) by enabling larger batch sizes. In summary, ZeRO-Offload supports model sizes ten times larger than otherwise possible and at higher performance.
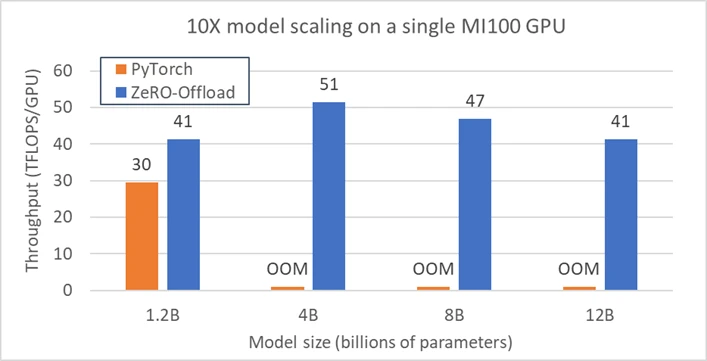
Extreme model scaling on single GPU
The figure below shows that ZeRO-Infinity (such as offloading to NVMe memory) enables even more dramatic scaling in model size on a single MI100 GPU. ZeRO-Infinity utilizes the available 3.5TB NVMe memory in the server to train models as large as 120B parameters on one GPU, thereby scaling the model size by two orders of magnitude compared to the baseline.
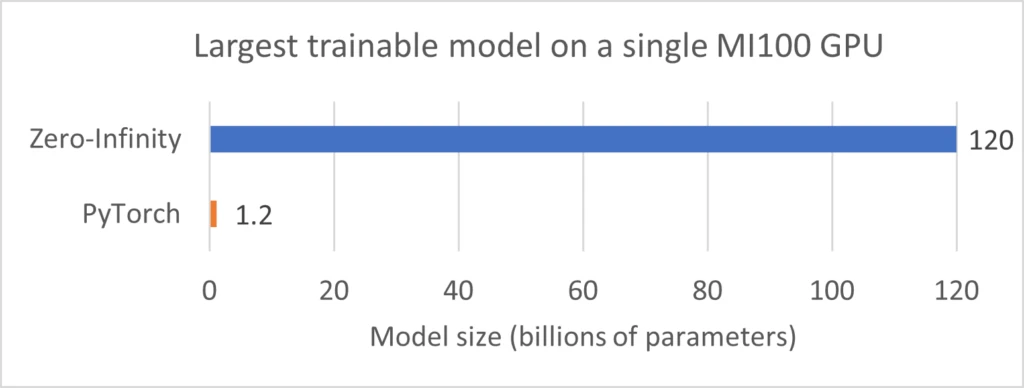
We also noticed that the training throughput with a single NVMe device (6.2GB/sec reads and 3.2GB/sec writes) was 12 TFLOPs and we can increase the throughput by using more NVMe devices. For example, we observed that by using four NVMe devices we were able to double the throughput to 24 TFLOPs.
Using DeepSpeed on AMD GPUs—Getting started
It is convenient to use DeepSpeed with the latest ROCm software on a range of supported AMD GPUs.
Installation
The simplest way to use DeepSpeed for ROCm is to use the pre-built docker image (rocm/deepspeed:latest) available on Docker Hub.
You can also easily install DeepSpeed for ROCm by just using “pip install deepspeed”. For details and advanced options please refer to the installation section of the DeepSpeed documentation page.
Using DeepSpeed on ROCm with HuggingFace models
The HuggingFace Transformers is compatible with the latest DeepSpeed and ROCm stack.
- Several language examples on HuggingFace repository can be easily run on AMD GPUs without any code modifications. We have tested several models like BERT, BART, DistilBERT, T5-Large, DeBERTa-V2-XXLarge, GPT2 and RoBERTa-Large with DeepSpeed ZeRO-2 on ROCm.
- DeepSpeed can be activated in HuggingFace examples using the deepspeed command-line argument, `
--deepspeed=deepspeed_config.json`.
We’ve demonstrated how DeepSpeed and AMD GPUs work together to enable efficient large model training for a single GPU and across distributed GPU clusters. We hope you can take these capabilities to quickly transform your ideas into fully trained models in no time on top of AMD GPUs.
We would love to hear feedback and welcome contributions on the DeepSpeed and AMD ROCm GitHub repos.
Related work
AMD ROCm is also supported as an execution provider in the ONNX Runtime for Training, another open-source project led by Microsoft. We refer you to a previous blog for more details. DeepSpeed is composable with ONNX Runtime using the open source ORTModule that is part of ONNX Runtime for PyTorch package. This allows the composition of DeepSpeed and ONNX Runtime optimizations. You can find more details in this blog post.
Contributors
This work was made possible with deep collaboration between system researchers and engineers at AMD and Microsoft. The contributors of this work include Jithun Nair, Jeff Daily, Ramya Ramineni, Aswin Mathews, and Peng Sun from AMD; Olatunji Ruwase, Jeff Rasley, Jeffrey Zhu, Yuxiong He, and Gopi Kumar from Microsoft.
This posting is the authors’ own opinion and may not represent AMD’s or Microsoft’s positions, strategies or opinions. Links to third-party sites are provided for convenience and unless explicitly stated, neither AMD nor Microsoft is responsible for the contents of such linked sites and no endorsement is implied.