
SQL Server 2014 In-Memory OLTP: Nonclustered Indexes for Memory-Optimized Tables
SQL Server 2014 CTP1 introduced hash indexes for memory-optimized tables. Hash indexes are very efficient for point lookups, when you know exactly the value you are looking for. However, they do not perform well if you need a range of value, for example a date range, or if you need to retrieve the rows in a particular order.
Memory-optimized nonclustered indexes are a new index type for memory-optimized tables in CTP2. Nonclustered indexes support retrieving ranges of values, and also support retrieving the table rows in the order that was specified when the index was created. They can be used to optimize the performance of queries on memory-optimized tables that use inequality predicates like ‘<’ and ‘>’, and queries using an ORDER BY clause.
Nonclustered indexes also support point lookups, but hash indexes still offer far better performance. You should continue to use hash indexes to optimize the performance of queries with equality predicates.
Hash Index Limitations
Consider, for example, the following (simplified) CREATE TABLE statement. The table SalesOrderHeader_inmem has a hash index on the primary key column ‘SalesOrderID’, as well as a hash index on the column ‘OrderDate’. The index definitions are bold-faced. Note that the BUCKET_COUNT should typically be set between one and two times the number of unique index key values.
CREATE TABLE [Sales].[SalesOrderHeader_inmem](
[SalesOrderID] uniqueidentifier NOT NULL
PRIMARY KEY
NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000)
DEFAULT (NEWID()),
[RevisionNumber] [tinyint] NOT NULL CONSTRAINT
[IMDF_SalesOrderHeader_RevisionNumber] DEFAULT ((0)),
[OrderDate] [datetime2] NOT NULL
INDEX ix_OrderDate HASH WITH (BUCKET_COUNT=1000000)
) WITH (MEMORY_OPTIMIZED=ON)If you run a query of the form:
SELECT * FROM Sales.SalesOrderHeader_inmem WHERE SalesOrderID = @IDSQL Server will use the hash index on the column SalesOrderID to quickly identify the row corresponding to the parameter @ID. Witness the Index Seek operation in the query plan:
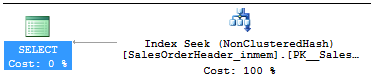
Hash indexes are very efficient for point lookup operations, because they require only a simple lookup in a hash table rather than traversing an index tree structure, as is required for traditional (non)clustered indexes. If you are looking for the rows corresponding to a particular index key value, using a hash index is the way to go.
Now, hash indexes do have some limitations. Because of the nature of hash tables, rows appear in the index in random order. This means it is not possible to retrieve ranges of values, or to scan rows in any particular order. Therefore, hash indexes do not support Index Seek operations on inequality predicates, and do not support ordered scans. The former results in a full index scan, and the latter results in a scan followed by a(n expensive) sort operator. All this results in a potential performance degradation when using such queries with hash indexes.
Consider the following two example queries:
Query with an inequality predicate
SELECT * FROM Sales.SalesOrderHeader_inmem
WHERE OrderDate > @DateThe plan for this query does not use the index on OrderDate; it simply includes full index scan for the primary index. This means that SQL Server will process all the rows in the table, and only later filter out the ones with OrderDate > @Date.

Query with an ORDER BY
SELECT * FROM Sales.SalesOrderHeader_inmem
ORDER BY OrderDateThe plan for this query includes a sort operator, which is very costly: after scanning the rows, all rows will need to be ordered to obtain the desired sort-order.

Nonclustered indexes
The new memory-optimized nonclustered indexes support both Index Seek operations using inequality predicates, and ordered scans. Consider the following amended CREATE TABLE statement, which now includes a nonclustered index on the column OrderDate.
‘SalesOrderID’, as well as a hash index on the column ‘OrderDate’. The index definitions are bold-faced.
CREATE TABLE [Sales].[SalesOrderHeader_inmem](
[SalesOrderID] uniqueidentifier NOT NULL
PRIMARY KEY
NONCLUSTERED HASH WITH (BUCKET_COUNT=1000000)
DEFAULT (NEWID()),
[RevisionNumber] [tinyint] NOT NULL CONSTRAINT
[IMDF_SalesOrderHeader_RevisionNumber] DEFAULT ((0)),
[OrderDate] [datetime2] NOT NULL
INDEX ix_OrderDate NONCLUSTERED
) WITH (MEMORY_OPTIMIZED=ON)
Note that the keyword NONCLUSTERED is optional in this example. Also note that the syntax for memory-optimized nonclustered indexes is similar to the traditional disk-based nonclustered indexes. The only difference is that with memory-optimized indexes you need to specify the index with the CREATE TABLE statement, while with traditional indexes, you can create the index after creating the table.
Consider now the following two queries:
Query with an inequality predicate
SELECT * FROM Sales.SalesOrderHeader_inmem
WHERE OrderDate > @DateThe plan for this query now uses the index on OrderDate. And when inspecting the properties of the Index Seek operator, you will see the inequality predicate OrderDate > @Date. This means that SQL Server will only need to process the rows with OrderDate > @Date.

Query with an ORDER BY
SELECT * FROM Sales.SalesOrderHeader_inmem
ORDER BY OrderDateThe plan for this query does not include a sort operator. SQL Server will scan the rows in the index in order; in this case the sort-order of the index is the same as the sort-order required by the query, thus no additional sort operator is needed.
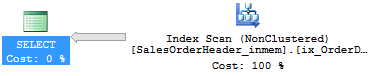
Note that, in contrast to disk-based nonclustered indexes, memory-optimized nonclustered indexes are uni-directional. This means that they support index scans only in the order that was specified when the index was created. If the ORDER BY clause in the above example would require OrderDate in DESC order, the index ix_OrderDate could not be used.
Limitations on memory-optimized indexes
Memory-optimized indexes do have a few limitations in SQL Server 2014 that we hope to address in future versions. You do need to consider these limitations when deciding on an indexing strategy for your memory-optimized tables.
- At most 8 indexes – you cannot specify more than 8 indexes on a single memory-optimized table.
- BIN2 collations – when using n(var)char columns in an index key, the columns must have a _BIN2 collation. Using BIN2 allows very fast lookup, as this can be based simply on binary comparison. However, you need to consider the implications of using a BIN2 collation, such as case and accent sensitivity. For more details see the Books Online topic on Collations and Code Pages.
- NOT NULL columns in the index key – memory-optimized indexes do not support nullable columns; all columns in the index key must be declared as NOT NULL.
Guidelines for choosing indexes
A few simple guidelines to help choose the type of index you need for your application:
- If you need to perform only point lookups, meaning you need to retrieve only the rows corresponding to a single index key value, use a hash index.
- If you need to retrieve ranges of rows, or need to retrieve the rows in a particular sort-order, use a nonclustered index.
- If you need to do both, particularly if point lookups are frequent, you can consider creating two indexes: it is possible to create both a hash and a nonclustered index with the same index key.
Hash indexes require an estimate of the number of unique index key values, to determine an appropriate value for the BUCKET_COUNT – typically between 1X and 2X. Because nonclustered indexes do not require setting the BUCKET_COUNT, it can be tempting to simply use a nonclustered index instead of a hash index. However, this could lead to sub-optimal performance for point lookup operations. In many scenarios where point lookup performance is critical and there is no good estimate for the number of unique index key values, it is better to over-provision the BUCKET_COUNT: i.e., pick a very high bucket count that you know is going to be larger than the number of index keys. Note that over-provisioning does not affect the performance of point lookups, but under-provisioning does. However, over-provisioning does increase memory-consumption and it slows down full index scans.
For more details on usage of memory-optimized indexes see the Books Online article on Guidelines for Using Indexes on Memory-Optimized Tables.