
Data-intensive Applications in the Cloud Computing World
Building data-intensive applications in emerging cloud computing environments is fundamentally different and more exciting. The levels of scale, reliability, and performance are as challenging as anything we have previously seen. Databases are still prevalent in design, but new patterns and storage options need to be considered, as well.
To provide a little context, I have developed and supported database software for over 30 years. I started with IMS/DLI and CICS/VSAM, then quickly moved to DB2 while it was still in beta (System R). I became a pretty hard core RDBMS expert with 11 years of DB2 experience and over 20 years of Microsoft SQL Server experience. I have been involved with some of the largest RDBMS projects in the world. (Example: a reliable, large-scale application in Europe that is available 24/7 and is designed to process up to 500,000 batch requests/sec, which equates to greater than 4 million SQL statements/sec.) Before the emerging era of cloud computing, my database thinking was all about scale-up computing with transaction latency measured in a few microseconds and IOPS measured in many GBs/sec.
For the past 18 months, my team has worked with customers to build applications on the Windows Azure platform. We’ve learned a lot about scale-out distributed computing—composing applications and solutions using different sets of services and resources while exploiting cloud platform fundamentals such as scalability, availability, and manageability. We’ve learned that developing data-intensive applications to a set of online services is very different than writing traditional client/server applications.
In the remainder of this post, I take a high-level look at the role of databases in cloud-based applications.
The design pattern and use of a database for a cloud-based application is different and, generally, expanded. You still have the need to store the persisted database transactions of the traditional RDBMS application. And, due to the use of distributed computing resources in a cloud-based application with higher standards for reliability, performance, and manageability, you also need extensive telemetry data captured about the entire application—if you want to build a great cloud application.
When we first started working with customers writing cloud-based data-intensive applications, most would use a relational database like Windows Azure SQL Database for all data storage, including telemetry data. This could be expected because developers often use the tool(s) they are most familiar with, TSQL provides a quick and well-known interface to get data in and out of the database, and relational databases generally take care of threading and concurrency for developers. At the time, the default thinking was that most data belongs in a traditional relational database where data is always stateful and carries atomic transactional properties. However, in the distributed cloud computing environment, scale will likely come from the implementation of stateless as well as stateful data properties. The new paradigm shifts us away from the use of a traditional RDBMS for all data.
An Example
Let me show you an example of a cloud application where multiple data stores are used. The architecture is for an online gaming experience. This application is designed to manage several thousand concurrent users and can scale out at several points, as needed. After the diagram, I will explain the different functions of the application, the type of data store used for each function, and why that particular type of data store is used for that function. As I describe each function, I will refer to a number in the diagram as a reference.
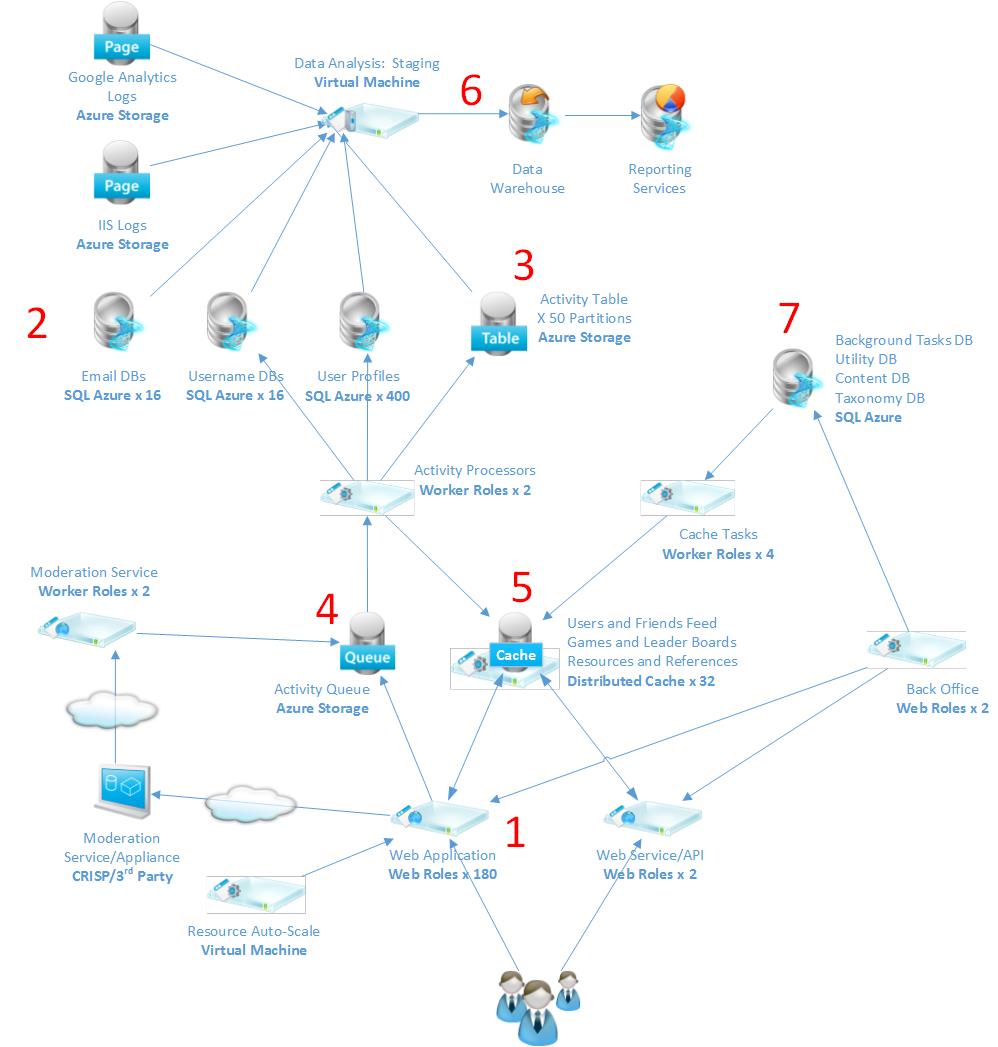
Function: Login and Initialize Profile — Looking at the bottom of the diagram, you see three users; let’s start there. These users log in and their sessions are assigned to a Windows Azure web role (#1). The web role hosts them while they are active on the system. The first step is to authenticate them and bring their profiles into Windows Azure Cache (#5). Their profiles are stored in Windows Azure SQL Database (#2). Complex queries retrieve profile data from the SQL Database by joining data (game history, scores, activity, etc.) from multiple relational tables to store in the Cache. A relational database is best suited for this type of persistent storage and complex query activity. The user profile also needs to be updated when information changes, so the same types of complex transactions are required to update the information back into the SQL Database. This is a good example of where a traditional relational database is best utilized as your data store.
Function: Play Games and Perform Online Activities — After the users are logged in and their profiles are in Cache, they can start the gaming experience. As you might expect, the gaming experience will be all in Cache (#5). The Cache is a high performance data store and is the obvious place to store active game data. Because Cache is non-durable, leaderboard, profile, and friend information is pushed out to other data stores for persistence.
Function: Documenting and Updating Activities — All active game activity is recorded while the users are playing, and this activity needs to be durable during play while constantly making changes to it. Activity data is stored in a Queue (#4). This is a durable Queue, so unlike the Cache, activity data is not lost if an outage takes place. Data stored in the Queue is processed by “activity processors” (hosted as Windows Azure worker roles) that process the data, carry-out application logic, and persist results and history.
Function: Activity History — For each user, all activity is stored and kept as history. Activity history is persisted on a periodic basis from the active Queue (#4) to a NoSQL store (#3). This NoSQL store rests in a table, using Windows Azure Table service. The table is used because the data is mostly write-only, with a requirement to easily grow in place with little need for complex query activity against it. So, the Table service is the best store for this type of data activity.
Function: Friend Interaction and Leaderboard — While users are playing, they can communicate and interact with friends (other users) in the system. They also might want to keep tabs of the leaderboard. Friend and leaderboard data changes often but not constantly, so this data is best stored in an Azure SQL Database (#7). The relational database is updated often, and the “cache tasks” role continuously pulls the latest information and ensures the active cache (#5) is always updated with the latest leaderboard and friend information through a query to the SQL Database.
Function: Data Warehouse — All user profile data and activity data is stored in a data warehouse (#6) for reporting purposes. Unstructured data from the Azure Table service is stored in Hadoop (Windows Azure HDInsight), and structured data is stored in a relational data warehouse (Azure SQL Database).
Summary
In summary, you can see that this single application uses five different data storage options: Windows Azure Cache, Azure SQL Database, Azure Queue service, Azure Table service, and Azure HDInsight (Hadoop). Each type of store was chosen because it represents the best option for the transactional needs of the operation being executed:
- Windows Azure Cache is used for performance (non-durable).
- Azure SQL Database is used for strong transactional consistency and for complex query needs.
- Azure Queue service is used for performance with heavy activity (durable).
- Azure Table service (NoSQL) is used for heavy inserts (write-only) and the need to grow easily and quickly.
- Azure HDInsight (Hadoop) is used for reporting against unstructured data.
If this was an on-premise application, you could have used multiple data stores, too, but the overhead of procurement, installation, and configuration of all of these sources adds time and money to your solution. As the diagram below suggests, with only a couple of clicks in the Windows Azure portal, you can have any of these data sources installed, configured, and up and running.
My world has changed. I am no longer just a relational database developer. The Windows Azure platform and Microsoft cloud services make it easy to use the best data store for whatever task I am trying to accomplish—and, in many cases, this means using several different types of data stores. For more information about our data platform vision and the future of data-intensive applications on the Windows Azure platform, see Quentin Clark’s blog, “What Drives Microsoft’s Data Platform Vision?”
Mark Souza
General Manager
Windows Azure Customer Advisory Team