
SQL Server 2016 Community Technology Preview 3.0 is available
The SQL Server engineering team is pleased to announce the availability of SQL Server 2016 October public preview release CTP 3.0. This release is a key milestone for SQL Server 2016 with all the key capabilities landing, including RRE integration. To learn more about this release, visit the SQL Server 2016 preview page.
To experience the new, exciting features in SQL Server 2016 and the new rapid release model, download the preview, and start evaluating the impact these new innovations can have for your business. Have questions? Join the discussion of the new SQL Server 2016 capabilities at MSDN and Stack Overflow. If you run into an issue or would like to make a suggestion, you can let us know using Microsoft’s Connect tool. We look forward to hearing from you.
Advanced Analytics (RRE integration)
With this release, we are very excited to announce the public availability SQL Server R Services in SQL Server 2016, an Advanced Analytics capability which supports enterprise-scale data science, significantly reducing the friction for adopting machine learning in your business. SQL Server R Services is all about helping customers embrace the highly popular open source R language in their business. R is the most popular programming language for Advanced Analytics. You can use it to analyze data, uncover patterns and trends and build predictive models. It offers an incredibly rich set of packages and a vibrant and fast-growing developer community. At the same time, embracing R in an enterprise setting presents certain challenges, especially as the volume of data rises and with the switch from modeling to production environments. Microsoft SQL Server R Services with in-database analytics helps customers embrace this technology by supporting several scenarios. Two of the key scenarios are:
One: Data Exploration and Predictive Modeling with R over SQL Server data
The data scientist can choose to analyze the data in-database or to pull data from SQL Server and analyze it on the client machine (or a separate server). Analyzing data in-database has the advantage of performance and speed by removing the need to move data around and leverage the strong compute resources on the SQL Server. RevoScaleR package and APIs contains a set of common functions and algorithms that were designed for performance and scale, overcoming R limitations of single-threaded execution and memory bound datasets.
Two: Operationalizing your R code using T-SQL
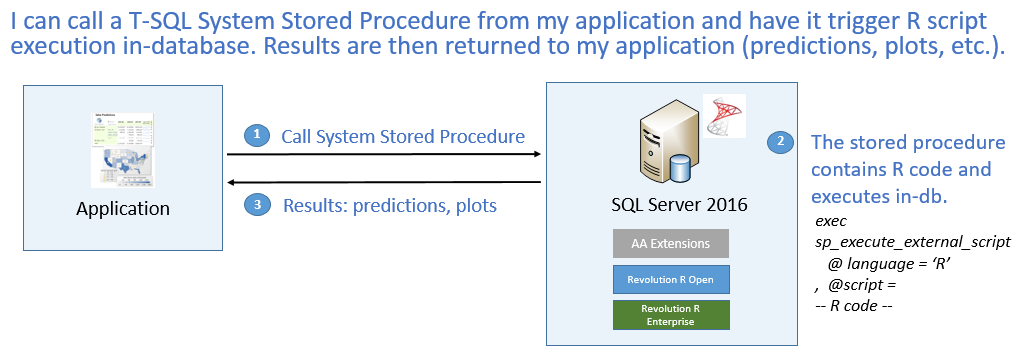
For SQL Server 2016 CTP3, we support ad-hoc execution of R scripts via a new system stored procedure. This stored procedure will support pushing data from a single SELECT statement and multiple input parameters to the R side and return a single data frame as output from the R side.
execute sp_execute_external_script.
Transactional replicate from SQL Server to Azure SQL DB in new in CTP3. Now you can setup Azure SQL DB as a subscriber of transaction replication, allowing you to migrate data from SQL Server instance on-premises or in IaaS to Azure SQL database without downtime. The replication is one way in this release, and works with SQL Server 2016, SQL Server 2014 and SQL Server 2012. This is the same Transactional Replication technology you have been using for many years on premise. As you configure a subscriber (from SSMS or by script), instead of entering an instance name, you enter the name of your Azure SQL DB subscription along with the associated login and password. A snapshot (as in a Replication Snapshot) will used to initialize the subscription and subsequent data changes will be replicated to you Azure SQL DB in the same transactional consistent way you are used to. A transactional publication can deliver changes to subscribers both in Azure SQL DB and/or on premise/Azure VM. There is no Replication service hosted in Azure for this. Everything is driven from on-premise distribution agents. To use this feature, you just need to set it up the way you do to replicate on-premises: Install the Replication components, configure the Distributor, the Publisher and create the Publication, the Articles and you the Subscriptions. In this case, one of the subscriptions will be your Azure SQL DB.
In-Memory improvements in this release:
- In-Memory OLTP
- FOREIGN KEY constraints
- CHECK constraints
- UNIQUE constraints
- DML triggers (AFTER only)
- EXECUTE AS CALLER
- Inline table-values functions
- Security built-ins and increased math function support
- Real-time Operational Analytics
- Support for in-memory tables
- Existing nonclustered columnstore index (NCCI) are updateable without requiring index rebuild
- Parallel Index build of nonclustered columnstore index (NCCI)
- Performance improvements (INSERT, String pushdown, bypassing delete buffer when processing deleted rows)
- In-Memory Analytics
- You can upgrade databases with nonclustered columnstore index and have it updateable without requiring rebuild of the index
- General performance improvements for analytics queries with columnstore index especially involving aggregates and string predicates
- Improved supportability with DMVs and XEvents
Stretch Database updates in this release:
- Engine Update
- Create/Drop index support
- AlwaysEncrypted support
- Improved credential management for remote Stretch database stores
- Improved performance for joins between stretched tables
- New external data source integration
- SSMS Wizard updates
- Database and Table level fly out menu options were updated to reflect new Stretch functionality
- Stretch monitor functionality added to allow users to monitor current migration status, including the ability to pause the migration at the table level
- XEVENT support for diagnostics session support in monitor
- Updated and simplified stretch wizard flow to reduce the amount of steps required to enable or reconfigure Stretch
- Help icon links Updated to point to new MSDN content focusing specifically on wizard topic
- Added functionality that allows users to pause or disable migration at the table level
- Added ability to Stretch individual tables
- Added database scoped credential support – for AlwaysOn
- Ability to enabling stretch on the server using the wizard
- Updated table level validation error/warning messaging
- The ability to Stretch to new SQL Azure or existing SQL Azure server
- Updated SSMS Object Explorer Stretch Databases icons
- SMO model for Stretch status query and updates
Always Encrypted updates in CTP3 include the following; please see the SSMS team blog for additional detail.
- Encrypting columns and key management made easy with new UI in SSMS
- Encrypt Columns Wizard
- Key management/rotation workflows
- Azure Key Vault support
- Integration with hardware security modules (.NET 4.6.1) and Azure Key Vault
Polybase in CTP3 includes the following new capabilities:
- Improved PolyBase query performance with scale-out computation on external data (PolyBase scale-out groups)
- Improved PolyBase query performance with faster data movement from HDFS to SQL Server and between PolyBase Engine and SQL Server
- Support for exporting data to external data source via INSERT INTO EXTERNAL TABLE SELECT FROM TABLE
- Support for push-down computation to Hadoop for string operations (compare, LIKE)
- Support for ALTER EXTERNAL DATA SOURCE statement
Built-in JSON support improvements in this release include:
- OPENJSON – Table value function that parses JSON text and returns rowset view of JSON. By default, OPENJSON returns properties of object or elements of array that is parsed. Advanced version of OPENJSON function with defined schema allows user to define schema of resulting rowset, and mapping rules that define where can be found values in the parsed JSON text that will be returned in the resulting rowset. It enables developers to easily parse JSON text and import it into relational tables.
- JSON_VALUE – Scalar function that returns a value from JSON on the specified path. It can be used in any query, view, computed column. It can be also used to define indexes on properties of JSON text stored in table columns.
- ISJSON – function that validates that JSON is properly formatted. It can be used to define check constraints on the columns that contain JSON text. It is not supported in check constraints defined on in-memory tables.
- JSON_QUERY – Scalar function that returns a fragment from the JSON text. Unlike JSON_VALUE that returns scalar values, JSON_QUERY returns complex object (i.e. JSON arrays and objects).
Temporal support improvements in this release include:
- Support for using temporal system-versioning with In-Memory OLTP
- Combining disk-based table for cost-effective storing of history data with memory-optimized tables for storing latest (actual) data
- Super-fast DML and current data querying supported from natively compiled code
- Temporal querying supported from interop mode
- Internal in-memory table created to minimally impact performance of DML operations
- Background process that flushes the data from internal in-memory to permanent disk-based history table
- Direct ALTER for system-versioned temporal tables enables modifying table schema without introducing maintenance window
- Support for adding/altering/dropping columns while SYSTEM_VERSIONING is ON
- Support for ADD/DROP HIDDEN for period columns while SYSTEM_VERSIONING is ON
- Support for temporal querying clause FOR SYSTEM_TIME ALL that enables users to query entire data history easily without specifying period boundaries
- Optimized CONTAINED IN implementation with minimized locking on current table. If your main case is analysis on historical data only, use CONTAINED IN.
Query Store improvements in this release include:
- Performance monitoring supported for natively compiled code from In-Memory OLTP workloads:
- Collecting queries, plans and compile time statistics enabled for natively compiled queries when Query Store is ON
- Stored plan is semantically equivalent to one that is produced when SET SHOWPLAN_XML is set to ON with one difference: plans in Query Store are always split and stored per individual statement
- Runtime statistics collection is controlled with sys.sp_xtp_control_query_exec_stats (does not enabled by default)
- is_natively_compiled field added to sys.query_store_plan to help finding queries generated by the native code compilation
- Plan forcing for queries from natively compiled modules is available and forced plans are honored during module recompilation. As for disk-based workloads, Query Store does not guarantee success of plan forcing operation as some plan shapes cannot be forced
- Memory grants metrics within sys.query_store_runtime_stats are not populated for natively compiled queries – their values are always 0
- Improving implementation of time-based cleanup (configured with STALE_QUERY_THRESHOLD_DAYS) to run in multiple transactions, holding database lock for a shorter period of time and thus minimize impact on customer workload
- Hadoop Connector: SSIS Hadoop connector allows customer to copy data to/from HDFS and trigger Hive/Pig job on Hadoop cluster. This brings in following components: Hadoop Connection Manager, H
SQL Server Integration Services (SSIS) improvements in this release include:
- SSIS control flow template enables customers to save a commonly used control flow task or container to a standalone template file and reuse it multiple times in a package or multiple packages in a project. This reusability introduced by template makes SSIS packages easier to design and maintain.
- Added Azure blob source support for the Import/Export wizard; user can use Azure blob source as source or destination during the transformation.
- Relaxed Max Buffer Size of Data Flow Task. The max Default Buffer Size of Data Flow Task is relaxed to 2G-1 from 100M. A new attribute ‘AutoAdjustBufferSize’ is added to Data Flow Task, which can be set in SSDT. If it is set to true, the Default Buffer Size will be set automatically in runtime according to Default Buffer Max Rows.
SQL Server Analysis Services (SSAS) improvements in this release include the following; please visit the SSAS team blog to learn more.
- DBCC support
- The Microsoft.AnalysisServices library has been re-factored to include a second namespace, Microsoft.AnalysisServices.Core. The new namespace separates out common classes like Server, Database, and Role that have broad application in Analysis Services, irrespective of server mode.
- SSMS and SSDT updates for Tabular
SQL Server Reporting Services (SSRS) improvements in this release include the following; please visit the SSRS team blog to learn more.
- Pin Reporting Services report items – Including charts, gauge panels, maps, and images – to Power BI dashboards. Dashboard tiles always show up-to-date data thanks to scheduled refresh. Click a dashboard tile to drill through to the complete Reporting Services report.
- Design reports using Visual Studio 2015 with an updated version of SQL Server Data Tools.
- Uses .NET Framework 4.x code in report expressions, report code, referenced assemblies, and extensions for report security, data processing, rendering, or delivery.
Master Data Services (MDS) improvements in this release include:
- Entity Change Approve Flow. Admin can mark an entity requiring approvals for changes. Examples include:
- Admin marks an entity requiring approval for changes in the entity administrator page
- User needs to save pending change to change set and submit to admin for approval
- Admin approves or rejects the pending changes
- The approved pending changes will be committed to the master data services
- Domain Based Attribute Constrained List. For domain-based attributes, optionally, user can select a parent attribute whose value will constrain the allowed values for this attribute. Examples include:
- Model has State, City, Account entity
- Account has a City DBA to City entity and State DBA to State entity
- City has a State DBA to State entity and a derived hierarchy from State to City
- A constrain can be added on Account; City attribute which parent is Account.State. so the City attribute dropdown list is constrained by State value
Query memory grant enhancement improvement in CTP3:
- Updated sort_warning and hash_warning XEvent to include spill IO stats
- New hash_spill_details XEvent for detailed spill information
- Statistics XML and SSMS updated to include spill warning
- sys.dm_exec_query_stats DMV: updated with new memory grant and parallelism info
- sys.dm_exec_requests DMV: updated with new memory grant and parallelism info
- sys.dm_exec_query_parallel_workers: new DMV to show worker threads status for parallel queries
- sys.dm_exec_query_optimizer_memory_gateways: new DMV to show query optimizer compile gates
Instant File Initialization setting for engine setup
SQL Server 2016 CTP 3.0 Setup adds the setting to enable instant file initialization for Database Engine. The instant file initialization option can be enabled in Service Accounts page of the Installation Wizard or through /SQLSVCINSTANTFILEINIT command line switch. Read our online documentation to learn more about Database Instant File Initialization.
SESSION_CONTEXT
SESSION_CONTEXT is an enhanced version of CONTEXT_INFO that supports key-value pairs. It has the following characteristics:
- Like CONTEXT_INFO, SESSION_CONTEXT is session-scoped and is reset by sp_reset_connection
- Values are set using a new system stored procedure: sp_set_session_context @key = N’key’, @value = N’value’ [, @read_only = { 1 | 0 } ]
- The @read_only option indicates that the value for that key cannot be changed again on that logical connection. This is reset by sp_reset_connection.
- Values are stored as sql_variant type, and keys are of type sysname.
- Values are retrieved using a new built-in function: SESSION_CONTEXT(N’key’)
- The total size of the session_context is limited to 256 kb per connection
Row-Level Security Block Predicates
Row-Level Security (RLS) now supports the following:
- Block predicates
- Block predicates prevent users from inserting, updating, and/or deleting rows that violate the predicate
- Block predicates use inline table-valued functions, just like filter predicates
- Separate predicates can be defined for different operations: AFTER INSERT, AFTER UPDATE, BEFORE UPDATE, BEFORE DELETE (where BEFORE and AFTER indicate whether the predicate will be evaluated against either the existing or the new row values)
- Non-schemabound security policies
- Security policies can now be created with SCHEMABINDING = OFF
- This is intended for scenarios where the predicate functions or helper tables must reside in an external database; in general, it is highly recommended that you use schemabound security policies (default) due to the security guarantees this provides CTP 3.0
For additional details, please read our individual Engineering team CTP 3.0 blogs for SQL Server Analysis Services (SSAS), SQL Server Data Tools (SSDT), SQL Server Management Studio (SSMS) and SQL Server Reporting Service (SSRS).