
Enhancing query performance with Adaptive Query Processing in SQL Server 2017
This post was authored by Joe Sack, Principal Program Manager, Data Systems Group, Microsoft
SQL Server 2017 and Azure SQL Database introduce a new generation of query processing improvements that will adapt optimization strategies to your application workload’s runtime conditions. For this first version of this adaptive query processing feature family, we have three new improvements: batch mode adaptive joins, batch mode memory grant feedback, and interleaved execution for multi-statement table valued functions.

Legacy optimization behavior
During optimization, the cardinality estimation process is responsible for estimating the number of rows processed at each step in an execution plan. Cardinality estimation uses a combination of statistical techniques and assumptions and when estimates are accurate (enough), we make informed decisions around the order of operations and physical algorithm selection.
When estimates are inaccurate, the query optimizer may make poor decisions regarding algorithm selection and order of operations. The cost of incorrect estimates can result in:
- Slow query response time due to inefficient plans
- Excessive resource utilization (CPU, Memory, IO)
- Spills to disk due to insufficient memory grant requests
- Reduced throughput and concurrency due to excessive memory grant sizes
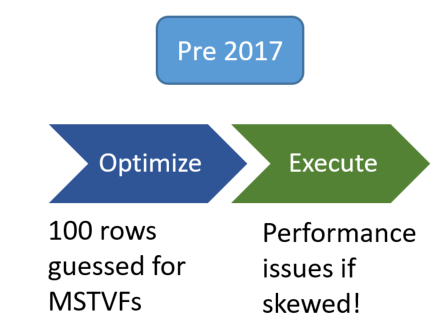
There are several reasons why incorrect cardinality estimates occur, from missing or stale statistics to inadequate statistics sample rates, bad parameter sniffing scenarios or cases where SQL Server does not have visibility to cardinality estimates and must make fixed-estimate guesses (e.g. multi-statement table valued functions, table variables, XQuery references).
Prior to SQL Server 2017, if we make poor assumptions due to bad cardinality estimates, we do not change our query plan execution strategy during execution.
Adapting to your workloads
The new adaptive query processing feature family in SQL Server 2017 and Azure SQL Database introduces three new techniques for adapting to your application workload characteristics.
Batch Mode Adaptive Joins
The query optimizer has three physical operator options for processing a join operation: nested loop, merge, and hash match. Which algorithm is appropriate or necessary, is highly dependent on the cardinality estimates of the join inputs. If we have inaccurate input cardinality estimates, this can result in the selection of an inappropriate join algorithm.
The new batch mode adaptive join feature enables the choice of a hash join or nested loop join method to be deferred until after the first input has been scanned. The adaptive join operator defines a threshold that is used to decide when to switch to a nested loop plan. Your plan can then dynamically switch to a better join strategy during execution using a single cached plan.

Batch Mode Memory Grant Feedback
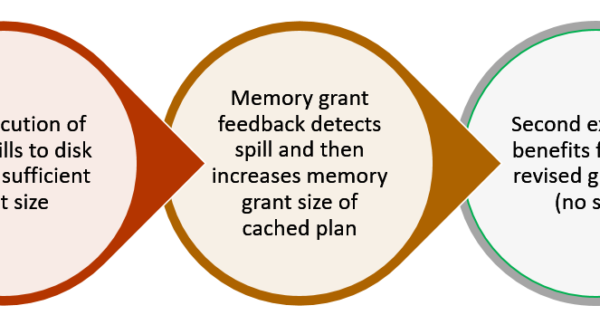
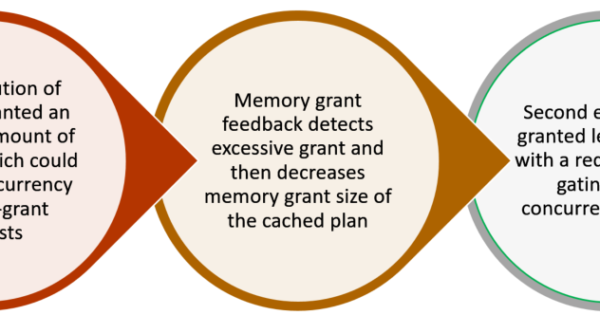
A query’s execution plan in SQL Server includes the minimum required memory needed for execution and the ideal memory grant size to have all rows fit in memory. When memory grant sizes are inadequate or excessive, performance suffers. Excessive grants result in wasted memory and reduced concurrency. Insufficient memory grants cause expensive spills to disk.
Addressing repeating workloads, batch mode memory grant feedback recalculates the actual memory required for a query and then updates the grant value for the cached plan. When an identical query statement is executed, the query uses the revised memory grant size, reducing excessive memory grants that impact concurrency and fixing underestimated memory grants that cause expensive spills to disk.
Inadequate grant scenario:
Excessive grant scenario:
Interleaved execution for multi-statement table valued functions
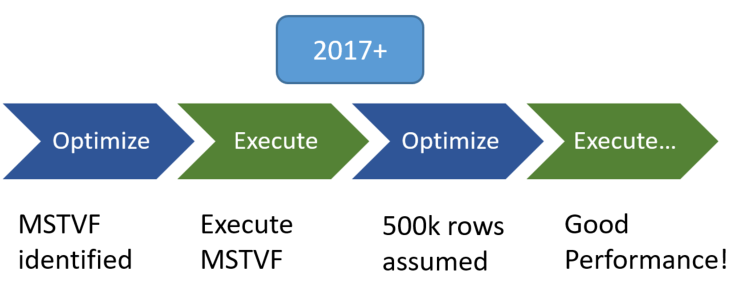
Interleaved execution for multi-statement table valued functions (MSTVFs) changes the unidirectional boundary between the optimization and execution phases for a single-query execution and enables plans to adapt based on the revised cardinality estimates. During optimization, if we encounter a candidate for interleaved execution, which for SQL Server 2017 is currently multi-statement table valued functions (MSTVFs), we will pause optimization, execute the applicable subtree, capture accurate cardinality estimates, and then resume optimization for downstream operations.
MSTVFs have a fixed cardinality guess of “100” in SQL Server 2014 and SQL Server 2016, and an estimate of “1” for earlier versions.
Interleaved execution helps workload performance issues that are due to these fixed cardinality estimates associated with multi-statement table valued functions. With interleaved execution, we will use the actual row counts from the MSTVF to make plan optimizations downstream from the MSTVF references. The result is a better-informed plan based on actual workload characteristics.
Enabling adaptive query processing
Adaptive query processing is enabled in SQL Server 2017 and Azure SQL Database under compatibility level 140. To learn more about this compatibility level, see Public Preview of Compatibility Level 140 for Azure SQL Database.
Learning more about adaptive query processing
For a comprehensive overview of all three features, see the Books Online topic Adaptive query processing in SQL databases.
Just getting started
We have several other opportunities in the query processing space to further add and enhance workload-adaptation mechanisms and strategies. Continued investment in the adaptive query processing feature family will help support and meet the requirements of a wide range of workload characteristics, from high-throughput transaction processing workloads to petabyte-scale relational data warehousing databases. Have feedback related to the query processor or other areas in SQL Server? If so, please submit feedback via the Microsoft Connect website.
