
SQL Server 2017 Features Bring ‘Choice’ to Developers
Data is everywhere today: in the cloud, on premises, and everywhere in between, tied up in systems of nearly endless complexity. Microsoft solutions allow developers to innovate while also scaling and growing their data infrastructure. In SQL Server 2016 SP1, SQL Server made available a consistent programmable surface layer for all its editions, making it easy to write applications that target any edition of the database. This year’s release takes it a step further with native support for Linux and Docker.
Microsoft puts the needs of the developer front and center in its data solutions. We have created the most advanced set of tools to radically lower the barriers to getting data – of any type, from anywhere – into the application design and build process. Today with the preview of Microsoft SQL Operations Studio, you can now access, run and manage this data from the system of your choice, on Windows, Linux and Docker.
Committed to choice for both database platform and tools
SQL Server 2017 also makes it easier to drive innovation via a CI/CD pipeline with the support of Docker containers. Since the Community Technology Preview of SQL Server 2017, there have been over 2 million Docker pulls. You can use any container orchestration layer, as SQL Server 2017 effectively becomes an application component within your compiled code hosted in the container. It is light weight and very fast to install – SQL Server on Linux installs in less than a minute. As a result, you can update the entire software stack with each check-in and deployment. Learn more on DevOps using SQL Server.
There are also SQL Server client drivers for the major languages, including C#, Java, PHP, Node.js, Python, Ruby and C++. Any language that supports ODBC data sources should be able to use the ODBC drivers. And any language based on the JVM should be able to use the JDBC or ODBC drivers. Choose any of the above languages to trial at our new hands-on labs.
In the spirit of choice, the data tools team today released SQL Operations Studio for public preview (see below). It is a light weight, cross-platform database development and operations tool designed to help non-database professionals with routine tasks necessary to update and maintain a database environment. It’s based on .NET Core and forks from Visual Studio Code, making it extremely extensible and easy to use. Download it, try it out, and please give us feedback via GitHub issues!

R + Python built-in for in-database analytics
The confluence of cloud, data and AI is driving unprecedented change. The ability to manage and manipulate data and to turn it into breakthrough actions and experiences, is foundational to innovation today. We view data as the catalyst to augment the human ingenuity, removing friction and driving innovation. We want to enable people to change and adapt quickly. Most of all, we want to equip today’s innovators and leaders to turn data into the insights and applications that will improve our world.
Developers and data scientists who explore and analyze data also have several new options. Now that SQL Server 2017 on Windows supports R and Python natively, they can either write R or Python scripts in the text editor of choice, or they can embed their scripts directly into their SQL query in SQL Server Management Studio. See example below:

Or if the analysis calls for highly complex joins, SQL Server 2017 also supports graph-based analytics, making it possible to describe nodes and edges within a SQL query. See example below:

CREATE TABLE Product (ID INTEGER PRIMARY KEY, name VARCHAR(100)) AS NODE;
CREATE TABLE Supplier (ID INTEGER PRIMARY KEY, name VARCHAR(100)) AS NODE;
CREATE TABLE hasInventory AS EDGE;
CREATE TABLE located_at(address varchar(100)) AS EDGE;
In-memory + performance for blazing-fast applications
And we mentioned, choice does not need to sacrifice performance! SQL Server 2017 also has some great performance enhancing features, including adaptive query processing (AQP) and automatic plan correction (APC). AQP uses Adaptive Memory Grants in SQL Server to track and learn how much memory is used by a given query to right-size memory grants. While APC ensures continuous performance by finding and fixing performance regressions. Customers have been highly favorable of these features, including dv01 who switched off their OSS stack on AWS to move everything to their stack run on SQL Server.
In-Memory OLTP is the premier technology available in SQL Server and Azure SQL Database for optimizing performance of transaction processing, data ingestion, data load, and transient data scenarios. Expect to see a 30x-100x increase in performance by keeping tables in-memory and using natively compiled queries.
A couple of steps to consider if you’re going to use In-Memory OLTP:
1. Recommended to set the database to the latest compatibility level, particularly for In-Memory OLTP:
ALTER DATABASE CURRENT SET COMPATIBILITY_LEVEL = 140; GO
2. When a transaction involves both a disk-based table and a memory-optimized table, it’s essential that the memory-optimized portion of the transaction operates at the transaction isolation level named SNAPSHOT:
ALTER DATABASE CURRENT SET MEMORY_OPTIMIZED_ELEVATE_TO_SNAPSHOT=ON
GO
3. Before you can create a memory-optimized table, you must first create a memory-optimized FILEGROUP and a container for data files:
ALTER DATABASE AdventureWorks ADD FILEGROUP AdventureWorks_mod CONTAINS memory_optimized_data GO ALTER DATABASE AdventureWorks ADD FILE (NAME='AdventureWorks_mod', FILENAME='c:\var\opt\mssql\data\AdventureWorks_mod') TO FILEGROUP AdventureWorks_mod GO
Security built-in at every level
Every edition of SQL Server provides a robust set of features designed to keep organizational data separate, secure, and safe. Two of the most interesting security features for developers are Always Encrypted and Row-Level Security.
Always Encrypted is a feature designed to protect sensitive data, such as credit card numbers or national identification numbers (social security numbers), stored in Azure SQL Database or SQL Server databases. Always Encrypted allows customers to encrypt sensitive data inside their applications and never reveal the encryption keys to the Database Engine (SQL Database or SQL Server). The driver encrypts the data in sensitive columns before passing the data to the Database Engine, and automatically rewrites queries so that the semantics to the application are preserved. Similarly, the driver transparently decrypts data, stored in encrypted database columns, contained in query results. See the graphic below:
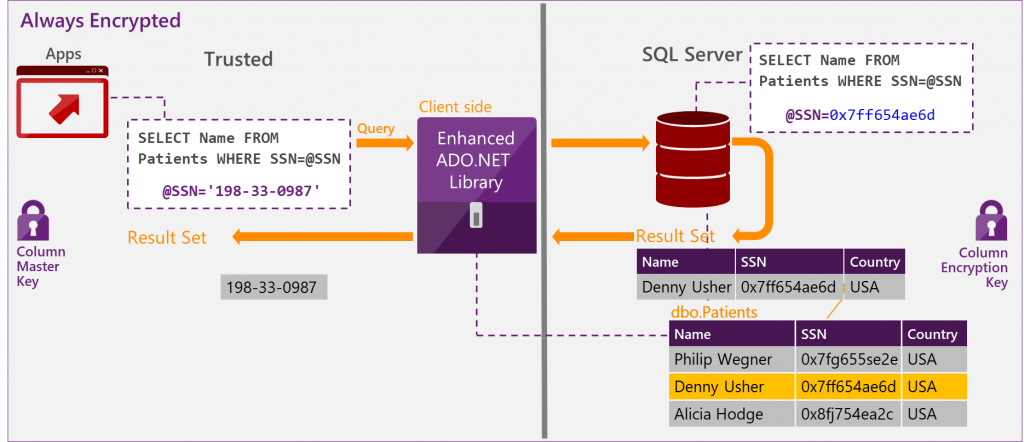
Row-Level Security (RLS) enables customers to control access to rows in a database table based on the characteristics of the user executing a query (for example, group membership or execution context).
Row-Level Security simplifies the design and coding of security in an application. Row-Level Security enables organizations to implement restrictions on data row access. For example, an organization can ensure that employees can access only those data rows that are pertinent to their department, or restrict a customer’s data access to only the data relevant to their company.
To configure Row-Level Security, follow the steps below:
1. Create user accounts to test Row-Level Security
USE AdventureWorks2014; GO CREATE USER Manager WITHOUT LOGIN; CREATE USER SalesPerson280 WITHOUT LOGIN;
2. Grant read access to users on required table
GRANT SELECT ON Sales.SalesOrderHeader TO Manager; GRANT SELECT ON Sales.SalesOrderHeader TO SalesPerson280;
3. Create a new schema and inline table-valued function
CREATE SCHEMA Security;
GO
CREATE FUNCTION Security.fn_securitypredicate(@SalesPersonID AS int)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN SELECT 1 AS fn_securitypredicate_result WHERE ('SalesPerson' + CAST(@SalesPersonId as VARCHAR(16)) = USER_NAME())
OR (USER_NAME() = 'Manager');
4. Create a security policy adding the function as both a filter and block predicate on the table
CREATE SECURITY POLICY SalesFilter ADD FILTER PREDICATE Security.fn_securitypredicate(SalesPersonID) ON Sales.SalesOrderHeader, ADD BLOCK PREDICATE Security.fn_securitypredicate(SalesPersonID) ON Sales.SalesOrderHeader WITH (STATE = ON);
5. Execute the query to the required table as each user to see the result (can also alter the security policy to disable policy)
Thanks for joining us on this journey to SQL Server 2017. We hope you love it! Going forward, we will continue to invest in our cloud-first development model, to ensure that the pace of innovation stays fast, and that we can bring you even more and improved SQL Server features soon.
Here are a few links to get started:
- Get started with SQL Server by building a sample app on the stack of your choice
- Download SQL Operations Studio and provide feedback during the public preview phase
- Watch the SQL Server 2017 Deep Dive from Microsoft Ignite 2017
- Learn about Microsoft’s hybrid data platform strategy from on-premises to cloud
