

How Hotpatching on Windows Server is changing the game for Xbox
In this article you’ll learn how Microsoft has been using Hotpatch with Windows Server 2022 Azure Edition to substantially reduce downtime for SQL Server databases running on…



Over the coming weeks, we’ll be publishing more on Windows Server 2016 and the key capabilities coming in the next wave of Microsoft datacenter solutions. In this installment we’ll be looking at software defined networking. We’ll begin with 4 challenge areas, move to how we’ve addressed them in our operations and double-click on ways you can apply the new technology to these challenges in your practice. Stay tuned for more on software-defined datacenter and the modern application platform.
It happens often. I’m with a group of customers talking about their network infrastructure and the conversation circles one (or more) of these 4 challenges:
It might be interesting to know that Microsoft faced very similar challenges when building to our present day hyper-scale datacenters. We have the luxury of having significant software development resources available to us to address these issues head-on. It’s been an ongoing process since we opened our first datacenter in 1989, exceeding $15 billion investment in our infrastructure. And we’ve learned a few things along the way.
Our datacenters hold over a million physical servers. It is unthinkable to run infrastructure at this scale using designs from prior to the cloud revolution. Given our volumes in both infrastructure and subscribers, we found that there was no other option other than write new code to software-define almost everything. In the process everything changed in networking. With Windows Server 2016, the SDN stack we use in Microsoft Azure will be available for your datacenters as well.
When I describe that in conversation people look at me with an expression on their faces indicating that they just learned something unexpected; seemingly adding up to the question of “Windows Server does what?!?!”
In this blog post, I will give an overview of networking in Windows Server 2016 and begin a series of articles that unwrap the technology underpinnings. I hope that you find these articles interesting and relevant, and reach back to us on areas you would like to see deeper drill-downs on.
Our SDN stack begins with disaggregating the management plane from the control plane, and in turn control plane from the data plane.
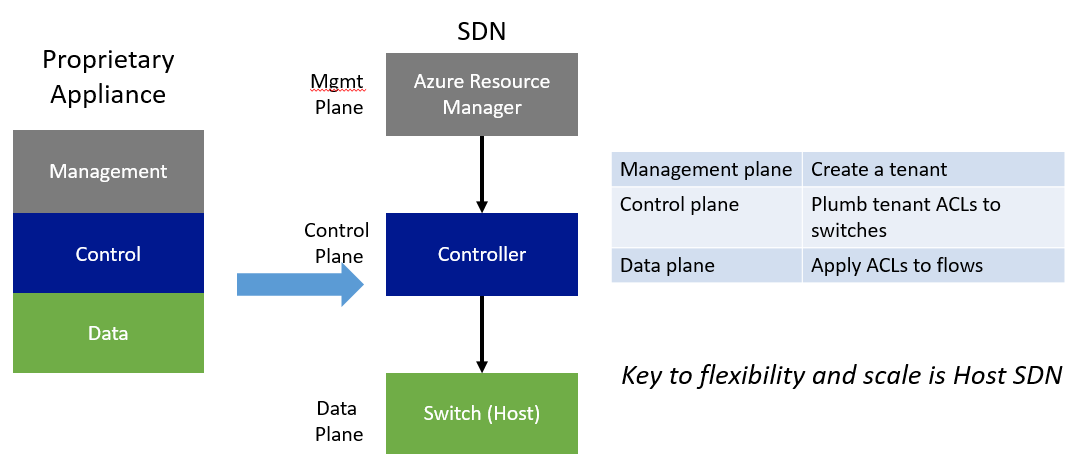
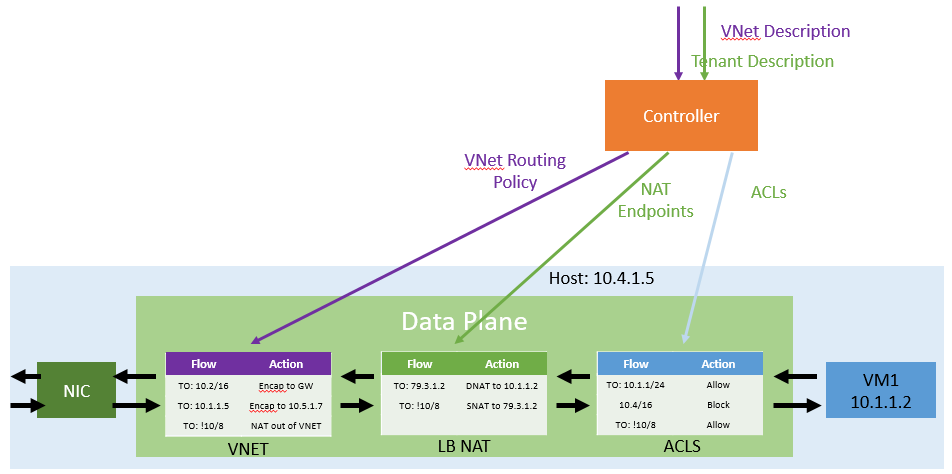
The most important thing we learned is that the key to flexibility and scale is a host-based SDN model. This means that each entity in the network platform must be programmable. Consider a simple access policy rule: using a host based model, policies are transformed into a specific set of instructions, pushed out by a centralized controller all the way down to the hosts – we are effectively using a tiny bit of distributed computing across the power of millions of servers to solve for a security issue using SDN. Such a model also enables network operators to compose a uniform software defined network overlaid upon an existing architecture, utilize other SDN products or build something brand new without requiring a fork-lift network upgrade.
In the conceptual architecture above the data plane is responsible for enforcing policies, with extreme efficiency in order to enable scale; using programmable rule/flow tables to perform per packet and per connection operations enabling 40GbE+ with all the underlying offloads.
A key innovation to reduce cost and simplify the infrastructure requirements was to converge RDMA based storage and the SDN fabric to run on the same underlying NIC. In Windows Server 2016 you can use RDMA to connect your compute nodes to your storage nodes using the same NICs used to service the rest of your network traffic. This eliminates the need for you to maintain separate physical networks for networking and RDMA based storage.
Layered on this data plane is the control plane. Our network controller uses a micro-services architecture, and is highly available. It exposes a RESTful Northbound API for provisioning fabric and tenant state and drives this state southbound into the data plane using interoperable southbound protocols and schemas, such as OMI, OVSDB, NetConf, and SNMP.
A key challenge we had to deal with was around configuration drift, which seemingly happened unbeknownst to us at unexpected times. What we did was to create the notion of a goal state for every element in the data plane – and then have agents that ensured that the data plane did not drift from that state. So, if an admin came and incorrectly changed the policy by some out of band means, the goal state agents would quickly reset it back to what it needed to be. This effectively eliminated all the challenges associated with configuration drift we were suffering from.
The loose coupling of the three planes enables rapid innovation and delivery. In Azure, we find that we introduce capabilities extremely rapidly (sometimes daily) into production. The integration across the three planes also enables a key set of capabilities that enables us to overcome the challenges outlined earlier in the blog.
We hear from many of our customers that they are keen on agility because they need to rapidly and efficiently introduce new services in order to remain competitive in market. In some cases, this is the core business of the firm and in others IT is competing with external service organizations for the opportunity. Looking back to the four challenge areas there’s one thing that spans each area to shorten cycle times and increase quality – templates. You can express all network policies associated with the application in place – subnets, routes, load balancing VIPs, NAT policies, ACLs, QoS policies (and many other non-networking policies as well) in our software defined and template driven model. The template can be deployed in seconds, and the same way every time; shortening tenant onboarding time and increasing quality. By using a goal-state template model you also increase the portability of your workload because you’re no longer concerned with spending time defining what the infrastructure configuration looks like, but rather describing how it functionally behaves.
The impact of changing customer demands for capacity, downtime expectations, application performance and user experiences tends to be that IT operators must not be constrained by infrastructure available in a single location. To date this has resulted in several complex scenarios including stretch clusters and L2 extension. What we learned in getting Azure public cloud services to where they are now, where an estimated 100,000 virtual networks are on-boarded every month, is that the simplest scenario is to build an overlay SDN. In this style of networking virtual networks are built on top of, and abstracted from, the physical network so that tenants and workloads are completely isolated from one another. It’s much easier to allow tenants to bring IP address spaces and routes to an overlay network environment than to manage this by yourself. We do this by including NVGRE and VXLAN in our SDN. Combining the overlay networks with dynamic routing protocols, results in a network where relocating workloads with live migration can be done without re-addressing any of the workload VMs or operator interaction.
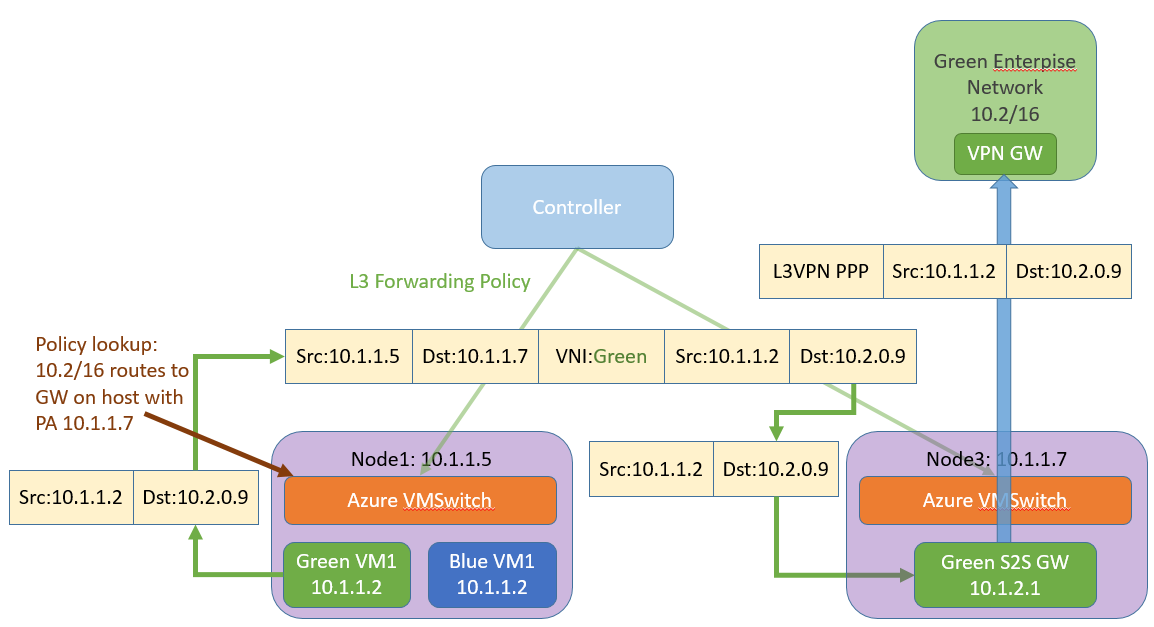
Building connections to other areas of your infrastructure, such as from the edge of your private cloud to the edge of your datacenter, for instance to an MPLS edge node, is simplified using the gateway functionality in Windows Server. A single gateway is able to service multiple tenants at a time, while maintaining isolation, provide secure connectivity for site-to-site, or a simple network address translation service. By deploying the gateway, you are able to connect the edge of the hybrid cloud to the resource without the complexity of coordinating subnets, routes and switch configuration on a transit network. The gateway can be deployed as a service, or dedicated to a specific function.
Limiting downtime for any infrastructure component is a first step forward – having the processes in place for minimizing disruption during upgrades, well established communications channels for when something unexpected happens will help you assure that your customer’s SLAs are met. Though, you can improve your service levels by building fault management into your infrastructure and applications. Components fail, application software has bugs, people make mistakes, and you can use networking strategies to mitigate risks for all of these things. Switch Embedded Teaming, L4 server load balancing and monitoring are each available in the Windows Serer 2016 platform as tools for helping you cope with unexpected events.
Switch Embedded Teaming helps you guard against NIC failure and interruptions in L1 cabling. L4 Server Load Balancers increase availability and high performance for traffic within your cloud, and for traffic entering and leaving your cloud. We use Direct Server Return so that the load balancer itself doesn’t present a risk to the connection once it is established with the server – once the LB decision is made the client and the server communicate directly. This also increases the scalability of the load balancer, and makes it so that the load balancers are all active all the time. We disaggregate the SLB itself such that the load balancer is simple, fast and stateless, while address translation happens on the destination host. More on the SLB in future blogs.
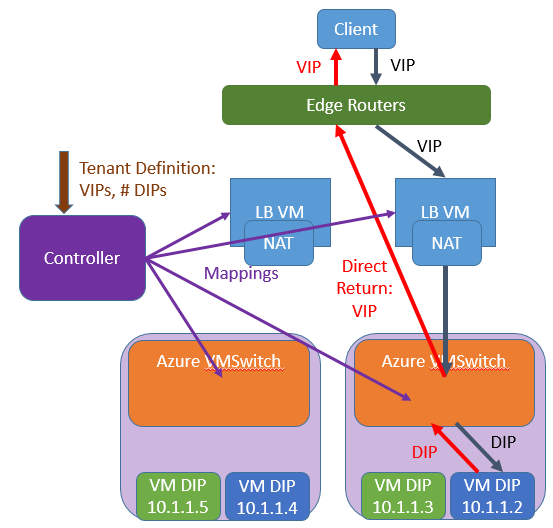
We reduce the likelihood of failure by reducing the coupling amongst the different planes (data/control), by disaggregating the infrastructure associated with a typical network appliance, and by using scale-out models. And if something is to fail, another instance picks up immediately.
When something unexpected does occur it can be difficult to separate the most pertinent information from loosely related information. Traditional network monitoring solutions that rely on the passive health data from SNMP traps, syslog messages, counters and statistics, etc. are often found to be very noisy, with many false alarms. Instead, in Windows Server 2016 our data collection system solution uses a synthetic transaction method that is built into the network controller. It uses active probes on the network to exchange packet flows for measuring performance. You can set the right amount of diagnostic traffic by increasing or decreasing the number of nodes running the network performance diagnostic services (NPDS). The solution also leverages passive health data for fault localization of the issue and identifying impact. It accounts for changes in topology, discovery results. With this capability user will be able to get a clear perspective on Virtual Networks affected due to failures in the physical network.
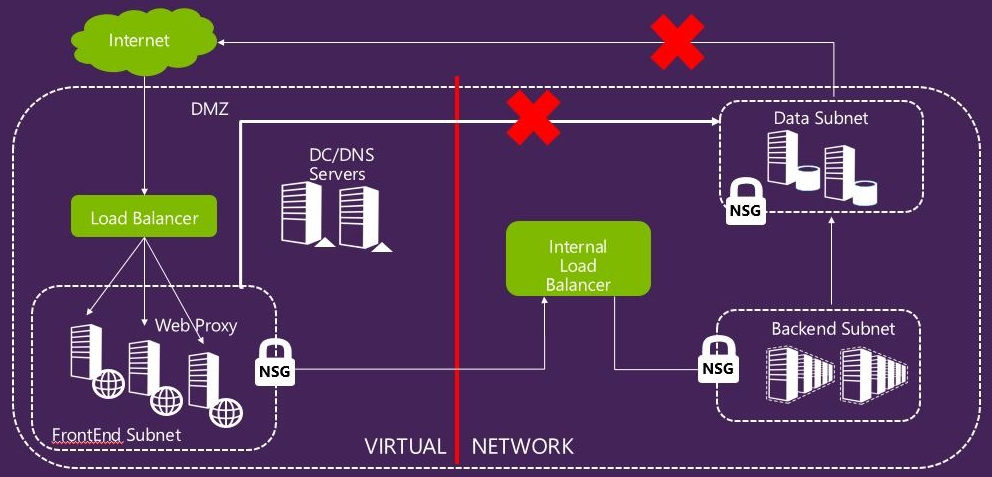
Many of you I speak to talk about having tens of thousands of IP-based ACLs, but with no abstraction layered on top that makes management of these rules easy.
With Network Security Groups (NSG), we allow you to name a set of security policies. For instance, you may name a group, DMZ, and associate with it a set of strong ACLs. Now, every VM that is in this security group will automatically be provisioned with the set of ACLs corresponding to this group. If you want to change an ACL at a later point of time, it’s easy – just change the policies in the network security group!
What challenges are you going to solve with networking and Windows Server 2016?
Be sure to check out the Windows Server Technical preview forum and Platform networking uservoice forum
In this article you’ll learn how Microsoft has been using Hotpatch with Windows Server 2022 Azure Edition to substantially reduce downtime for SQL Server databases running on…

This year, Microsoft Ignite 2023 took place in Seattle, Washington from November 12 to 15, 2023 and it was such a wonderful experience to meet and interact…

October 10th, 2023 marks the end of support date for Windows Server 2012/R2 and we want to outline options for customers to stay protected and compliant.