


Building your Data Lake on Azure Data Lake Storage gen2 – Part 1

For those organisations starting their data lake journey, they will attempt to answer these frequently asked questions:
- How do we structure the lake?
- Which file formats should we use?
- Should we have multiple lakes or just one?
- How best to secure and govern the lake?
It is unlikely that these can be finalised “in perpetuum” in the beginning as they tend to evolve over time, as requirements change and through continuous learning and observation.
There is no definitive guide to building a data lake, as each organisation’s situation is unique in terms of ingestion, processing, consumption and governance. This two-part blog will provide guidance to those planning their data lake and attempts to address some key considerations to the questions above. Part 1 will cover general data lake concepts such as planning, design and structure. Part 2 will predominantly focus on ADLS gen2 such as implementation, security and optimisation.
Data Lake Planning
Structure, governance and security are key aspects which require an appropriate amount of planning relative to the potential size and complexity of your data lake. Consider what data is going to be stored in the lake, how it will get there, the transformations it will undergo, who or what will be accessing it and the typical access patterns. This will influence the structure of the lake and how it will be organised. Then consider who will need access to which part of the lake, and how to group these consumers and producers of data. Planning how to implement and govern access control across the lake will be well worth the investment in the long run.
If your data lake is likely to start out with a few data assets and only automated processes (such as ETL offloading) then this planning phase may be a relatively simple task. Should your lake contain hundreds of data assets and have both automated and manual interaction then certainly planning is going to take longer and require more collaboration from the various data owners.
Most people by now are probably all too familiar with the dreaded “data swamp” analogy. According to Blue Granite; “Hard work, governance, and organisation” is the key to avoiding this situation. Of course, it may be impossible to plan for every eventuality in the beginning, but laying down solid foundations will increase the chance of continued data lake success and business value in the long run.
A robust data catalogue system also becomes ever-more critical as the size (number of data assets) and complexity (number of users or departments) of the data lake increases. The catalogue will ensure that data can be found, tagged and classified for those processing, consuming and governing the lake. This important concept will be covered in further detail in another blog.
Data Lake Structure — Zones
This has to be the most frequently debated topic in the data lake community, and the simple answer is that there is no single blueprint for every data lake — each organisation will have it’s own unique set of requirements. A simple approach may be to start with a few generic zones (or layers) and then build out organically as more sophisticated use-cases arise. The zones outlined below are often called different things, but conceptually they have the same purpose — to distinguish the different states or characteristics of the data as it flows through the lake, usually in terms of both business value and the consumers accessing that data.

Raw zone
Using the water based analogy, think of this layer as a reservoir which stores data in it’s natural originating state — unfiltered and unpurified. You may choose to store it in original format (such as json or csv) but there may be scenarios where it makes sense to store it in compressed formats such as Avro, Parquet or Databricks Delta Lake. This raw data should be immutable -it should be locked down and permissioned as read-only to any consumers (automated or human). The zone may be organised using a folder per source system, each ingestion processes having write access to only their associated folder.
As this layer usually stores the largest amount of data, consider using lifecycle management to reduce long term storage costs. At the time of writing ADLS gen2 supports moving data to the cool access tier either programmatically or through a lifecycle management policy. The policy defines a set of rules which run once a day and can be assigned to the account, file system or folder level. The feature is free although the operations will incur a cost.

Cleansed zone
The next layer can be thought of as a filtration zone which removes impurities but may also involve enrichment.
Typical activities found in this layer are schema and data type definition, removing of unnecessary columns, and application of cleaning rules whether it be validation, standardisation, harmonisation. Enrichment processes may also combine data sets to further improve the value of insights.
The organisation of this zone is usually more business driven rather than by source system — typically this could be a folder per department or project. Some may also consider this as a staging zone which is normally permissioned by the automated jobs which run against it. Should data analysts or scientists need access to the data in this form, they could be granted read-only access only.

Curated zone
This is the consumption layer, which is optimised for analytics rather than data ingestion or data processing. It may store data in denormalised data marts or star schemas as mentioned in this blog. The dimensional modelling is preferably done using tools like Spark or Data Factory rather than inside the database engine. Should you wish to make the lake the single source of truth then this becomes a key point. If the dimensional modelling is done outside of the lake i.e. in the data warehouse then you may wish to publish the model back to the lake for consistency. Either way, a word of caution though; don’t expect this layer to be a replacement for a data warehouse, as discussed in this video. Typically the performance is not adequate for responsive dashboards or end-user/consumer interactive analytics. It is best suited for internal analysts or data scientists who want run large-scale adhoc queries, analysis or advanced analytics, and those who do not have strict time-sensitive reporting needs. As storage costs are generally lower in the lake compared to the data warehouse, it may be more cost effective to keep granular, low level data in the lake and store only aggregated data in the warehouse. These aggregations can be generated by Spark or Data Factory and persisted to the lake prior to loading the data warehouse.
Data assets in this zone are typically highly governed and well documented. Permission is usually assigned by department or function and organised by consumer group or by data mart.

Laboratory zone
This is the layer where exploration and experimentation occurs. Here, data scientists, engineers and analysts are free to prototype and innovate, mashing up their own data sets with production data sets. This is similar to the notion of self-service analytics (BI) which is useful during the initial assessment of value. This zone is not a replacement for a development or test data lake, which is still required for more rigorous development activities following a typical software development lifecycle.
Each lake user, team or project will have their own laboratory area by way of a folder, where they can prototype new insights or analytics, before they are agreed to be formalised and productionised through automated jobs. Permissions in this zone are typically read and write per user, team or project.
—
In order to visualise the end-to-end flow of data, the personas involved, the tools and concepts, in one diagram, the following may be of help:
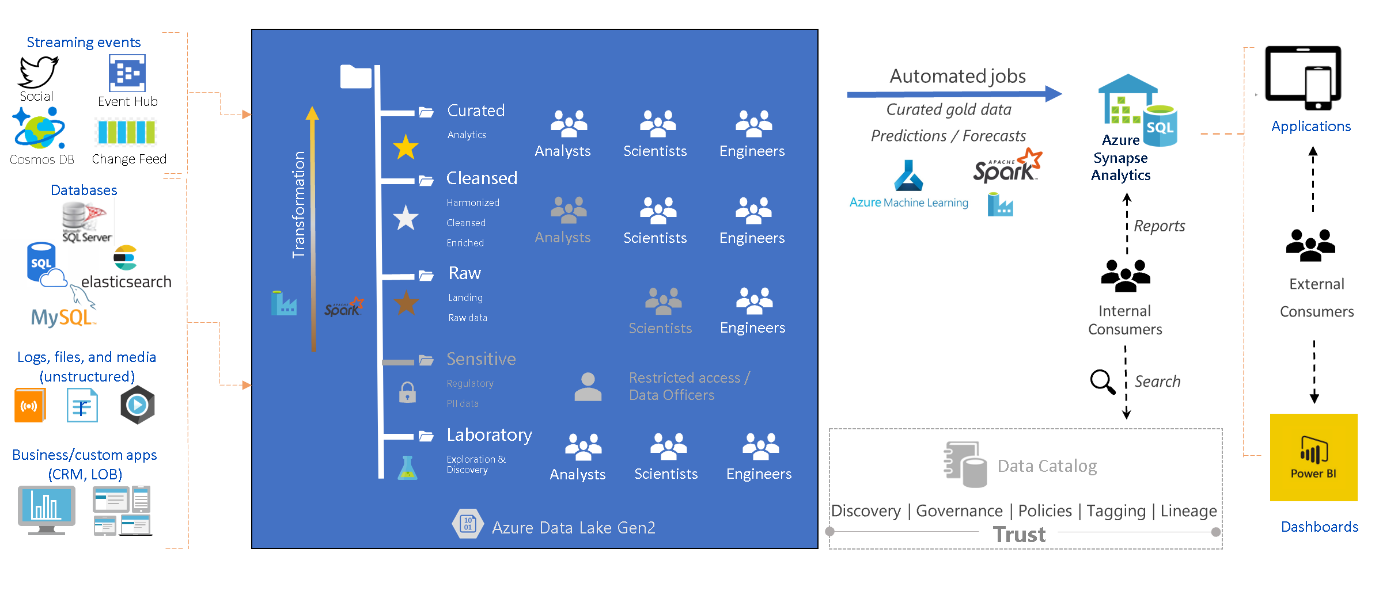
Concepts, tools, & personas in the Data Lake
The sensitive zone was not mentioned previously because it may not be applicable to every organisation, hence it is greyed out, but it is worth noting that this may be a separate zone (or folder) with restricted access.
The reason why scientists are greyed out in the raw zone is that not all data scientists will want to work with raw data as it requires a substantial amount data preparation before it is ready to be used in machine learning models. Equally analysts do not usually require access to the cleansed layer but each situation is unique and it may occur.
Folder structure – Hierarchy
An appropriate folder hierarchy will be as simple as possible but no simpler. Folder structures should have:
- a human-readable, understandable, consistent, self documenting naming convention
- sufficiently granular permissions but not at a depth that will generate additional overhead and administration.
- partitioning strategies which can optimise access patterns and appropriate file sizes. Particularly in the curated zones, plan the structure based on optimal retrieval but be cautious of choosing a partition key with high cardinality which leads to over partitioning which in turn leads to sub-optimal file sizes.
- each folder with files of the same schema and the same format/type
Whilst many use time based partitioning there are a number of other partitioning options which may provide more efficient access paths. Some other options you may wish to consider are by subject area, department/business unit, downstream application or purpose, retention policy or freshness or sensitivity.
The raw zone may be organised by source system, then entity. Here is an example folder structure, optimal for folder security:
\Raw\DataSource\Entity\YYYY\MM\DD\File.extension
Typically each source system will be granted write permissions at the DataSource folder level with default ACLs (more on ACLs in the next blog) specified. This will ensure permissions are inherited as new daily folders and files are created. In contrast, the following structure can become tedious for folder security as defaults at DataSource level do not help in this case and individual DataSource write permissions will need to be granted for every new daily folder:
\Raw\YYYY\MM\DD\DataSource\Entity\File.extension
Sensitive sub-zones in the raw layer can be separated by top level folder. This will allow one to define a separate lifecycle management policy using rules based on prefix matching. Eg:
\Raw\General\DataSource\Entity\YYYY\MM\DD\File.extension \Raw\Sensitive\DataSource\Entity\YYYY\MM\DD\File.extension
—
Be sure to keep an open mind during this planning phase. The zones and folder structures do not need to be cast in stone, they can evolve over time to suit ever-changing requirements. Equally, folders and zones do not need to always reside in the same physical data lake— they could exist in separate file systems or different storage accounts, even in different subscriptions. If you are likely to have huge throughput requirements in a single zone which may exceed a request rate of 20,000 per second, then multiple physical lakes (storage accounts) in different subscriptions would be a sensible idea. See the next blog post for more details!


