Configure access to Azure Data Lake Gen 2 from Azure Databricks

There are a number of ways to configure access to Azure Data Lake Storage gen2 (ADLS) from Azure Databricks (ADB). This blog attempts to cover the common patterns, advantages and disadvantages of each, and the scenarios in which they would be most appropriate. For information on how to secure network connectivity between ADB and ADLS using Azure Private Link, please refer to the following blog.
ADLS offers more granular security than RBAC through the use of access control lists (ACLs) which can be applied at folder of file level. As per best practice these should be assigned to AAD groups rather than individual users or service principals. There are two main reasons for this; i.) changing ACLs can take time to propagate if there are 1000s of files, and ii.) there is a limit of 32 ACLs entries per file or folder.
By way of a simple example a data lake may require two sets of permissions. Engineers who run data pipelines and transformations requiring read-write access to a particular set of folders, and analysts who consume [read-only] curated analytics from another. Two AAD groups should be created to represent this division of responsibilities, and the required permissions for each group can be controlled through ACLs. Users should be assigned to the appropriate AAD group, and the group should then be assigned to the ACLs. Please see the documentation for further details. For automated jobs, a service principal which has been added to the appropriate group should be used, instead of an individual user identity. Service principal credentials should be kept extremely secure and referenced only though secret scopes.
Pattern 1. Access via Service Principal
To provide a group of users access to a particular folder (and it’s contents) in ADLS, the simplest mechanism is to create a mount point using a service principal at the desired folder depth. The mount point (/mnt/<mount_name>) is created once-off per workspace but is accessible to any user on any cluster in that workspace. In order to secure access to different groups of users with different permissions, one will need more than just a single one mount point in one workspace. One of the patterns described below should be followed.
Note access keys are not an option on ADLS whereas they can be used for normal blob containers without HNS enabled.
Below is sample code to authenticate via a SP using OAuth2 and create a mount point in Python.
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "enter-your-service-principal-application-id-here",
"fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope = "enter-your-key-vault-secret-scope-name-here", key = "enter-the-secret"),
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/enter-your-tenant-id-here/oauth2/token"}
dbutils.fs.mount(
source = "abfss://file-system-name@storage-account-name.dfs.core.windows.net/folder-path-here",
mount_point = "/mnt/mount-name",
extra_configs = configs)
The creation of the mount point and listing of current mount points in the workspace can be done via the CLI.
>databricks configure — token Databricks Host (should begin with https://): https://eastus.azuredatabricks.net/?o=#########Token: dapi############### >databricks fs ls dbfs:/mnt datalake
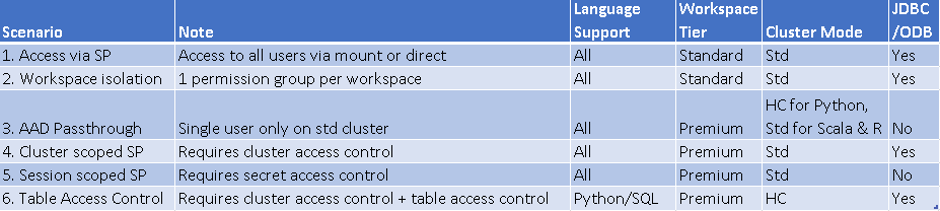
From an architecture perspective these are the basic components where “dl” is used to represent the mount name.
Note the use of default ACLs otherwise any new folders created will be inaccessible
The mount point and ACLs could be at the filesystem (root) level or at the folder level to grant access at the required filesystem depth.
Instead of mount points, access can also be via direct path — Azure Blob Filesystem (ABFS – included in runtime 5.2 and above) as shown in the code snippet below.
To access data directly using service principal, authorisation code must be executed in the same session prior to reading/writing the data for example:
# authenticate using a service principal and OAuth 2.0
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", "enter-your-service-principal-application-id-here")
spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "secret-scope-name", key = "secret-name"))
spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com//enter-your-tenant-id-here/oauth2/token")
# read data in delta format
readdf=spark.read.format("delta").load(abfs://file-system-name@storage-account-name.dfs.core.windows.net/path-to-data")
Using a single service principal to authenticate users to a single location in the lake is unlikely to satisfy most security requirements – it is too coarse grained, much like RBAC on Blob containers. It does not facilitate securing access to multiple groups of users of the lake who require different sets of permissions. One or more the following patterns may be followed to achieve the required level of granularity.
Pattern 2. Multiple workspaces — permission by workspace
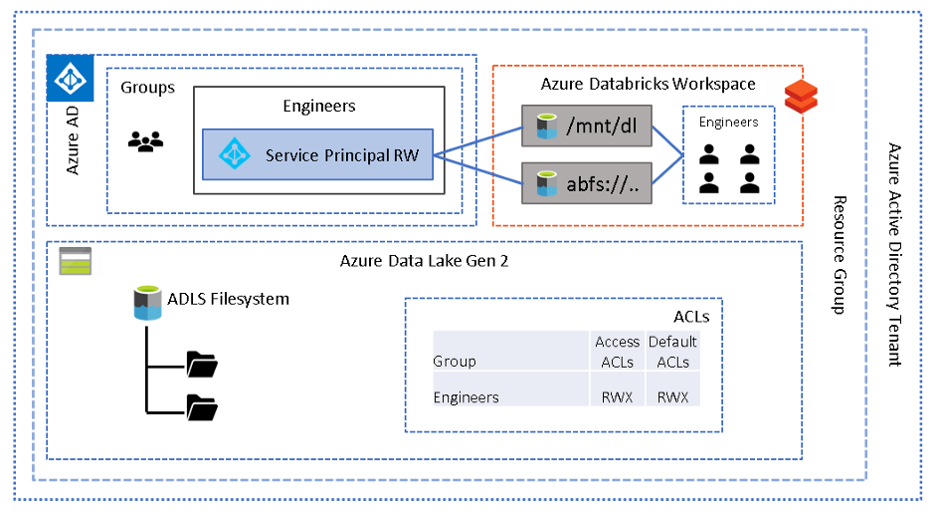
This is an extension of the first pattern whereby multiple workspaces are provisioned, and different groups of users are assigned to different workspaces. Each group/workspace will use a different service principal to govern the level of access required, either via a configured mount point or direct path. Conceptually, this is a mapping of service principal to each group of users, and each service principal will have a defined set of permissions on the lake. In order to assign users to a workspace simply ensure they are registered in your Azure Active Directory (AAD) and an admin (those with contributor or owner role on the workspace) will need to add users (with the same identity as in AAD) to the appropriate workspace. The architecture below depicts two different folders and two groups of users (readers and writers) on each.
This pattern may offer excellent isolation at a workspace level however the main disadvantage to this approach is the proliferation of workspaces — n groups = n workspaces. The workspace itself does not incur cost, but there may be an inherit increase in total cost of ownership. If more granular security is required at workspace level then one of the following patterns may be more suitable.
Pattern 3. AAD Credential passthrough
AAD passthrough allows different groups of users to all work in the same workspace and access data either via mount point or direct path authenticated using their own credentials. The user’s credentials are passed through to ADLS gen2 and evaluated against the files and folder ACLs. This feature is enabled at the cluster level under the advanced options.
To mount an ADLS filesystem or folder with AAD passthrough enabled the following Scala may be used:
val configs = Map("fs.azure.account.auth.type" -> "CustomAccessToken", "fs.azure.account.custom.token.provider.class" -> spark.conf.get("spark.databricks.passthrough.adls.gen2.tokenProviderClassName"))
// Optionally, you can add <directory-name> to the source URI of your mount point.
dbutils.fs.mount(
source = "abfss://file-system-name@storage-account-name.dfs.core.windows.net/folder-path-here",
mountPoint = "/mnt/mount-name",
extraConfigs = configs)
Any user reading or writing via the mount point will have their credentials evaluated. Alternatively, to access data directly without a mount point simply use the abfs path on a cluster with AAD Passthrough enabled, for example:
# read data in delta format using direct path
readdf = spark.read
.format("<file format>")
.load("abfss://<filesys>@<storageacc>.dfs.core.windows.net/<path>")
Originally this functionality was only available using high concurrency clusters and supported only Python and SQL notebooks, but recently standard clusters support for AAD passthrough using R and Scala notebooks were announced. One major consideration however for standard clusters, is that only a single user can be enabled per cluster.

A subtle but important difference in this pattern is that service principals are not required to delegate access, as it is the user’s credentials that are used.
Access can still be either direct path or mount point
There are some further considerations to note at the time of writing:
- The minimum runtime versions as well as which PySpark ML APIs which are not supported, and associated supported features
- Databricks Connect is not supported
- Jobs are not supported
- jdbc/odbc (BI tools) is not yet supported
If any of these limitations present a challenge or there is a requirement to enable more than one Scala or R developer to work on a cluster at the same time, then you may need to consider one of the other patterns below.
Pattern 4. Cluster scoped Service principal
In this pattern, each cluster is “mapped” to a unique service principal. By restricting users or groups to a particular cluster, using the “can attach to” permission, it will ensure that access to the data lake is restricted by the ACLs assigned to the service principal.
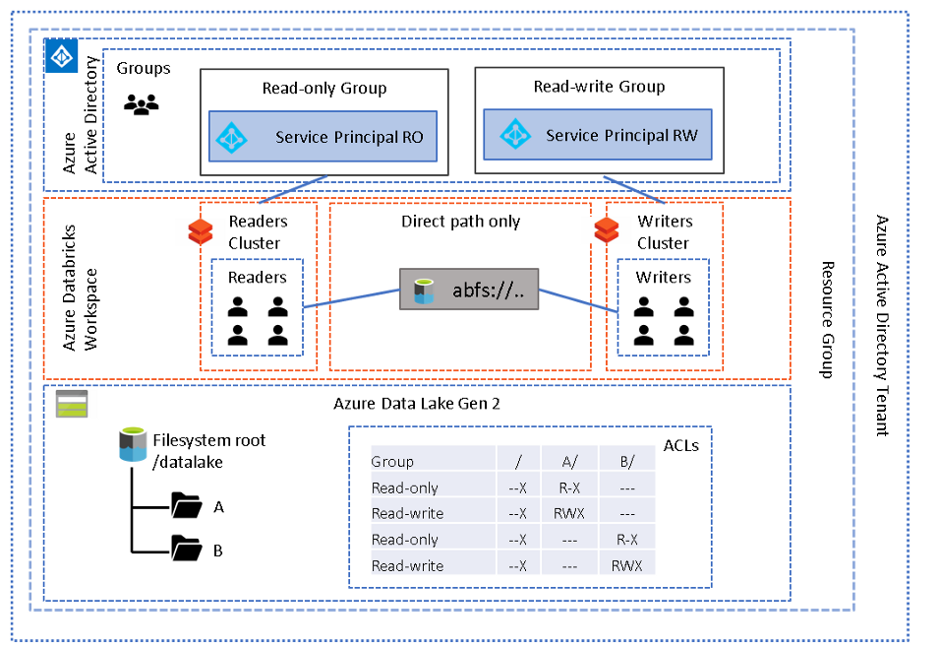
This pattern will allow you to use multiple clusters in the same workspace, and “attach” a set of permissions according to the service principal set in the cluster config:
fs.azure.account.auth.type OAuth
fs.azure.account.oauth.provider.type org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider
fs.azure.account.oauth2.client.id <service-principal-application-id>
fs.azure.account.oauth2.client.secret {{secrets/<your scope name>/<secret name>}}
fs.azure.account.oauth2.client.endpoint https://login.microsoftonline.com/<tenant id>/oauth2/token
Note the method in which secrets are referenced in the config section as it is different from the usual dbutils syntax
The benefit of this approach is that the scope and secret names are not exposed to end-users and they do not require read access to the secret scope however the creator of the cluster will.
Users should use the direct access method, via ABFS, and mount points should be forbidden, unless of course there is a global folder everyone in the workspace needs access to. Until there is an in-built way to prevent mount points being created, you may wish to write an alert utility which runs frequently checking for any mount points using the CLI (as shown in the first pattern) and sends a notification if any unauthorised mount points are detected.
This pattern could be useful when both engineers and analysts require different sets of permissions and assigned to the same workspace. The engineers may need read access to one or more source data sets and then write access to a target location, with read-write access to a staging or working location. This requires a single service principal to have access to all the data sets in order for the code to execute fully — more about this in the next pattern. The analysts however may need read access to the target folder and nothing else.
The disadvantage of this approach is dedicated clusters for each permission group, i.e. no sharing of clusters across permission groups. In other words, each service principal, and therefore each cluster, should have sufficient permissions in the lake to run the desired workload on that cluster. The reason for this is that a cluster can only be configured with a single service principal at a time. In a production scenario the config should be specified through scripting the provisioning of clusters using the CLI or API.
Depending on the number of permission groups required, this pattern could result in a proliferation of clusters. The next pattern may overcome this challenge but will require each user to execute authentication code at run time.
Pattern 5. Session scoped Service principal
In this pattern, access control is governed at the session level so a cluster may be shared by multiple groups of users, each using a set of service principal credentials. Normally, clusters with a number of concurrent users and jobs will require a high concurrency cluster to ensure resources are shared fairly. The user attempting to access ADLS will need to use the direct access method and execute the OAuth code prior to accessing the required folder. Consequently, this approach will not work when using odbc/jdbc connections. Also note, that only one service principal can be set in session at a time and this will have a significant influence the design based on Spark’s lazy evaluation, as described later. Below is sample OAuth code, which is very similar to the code used in pattern 1 above:
# authenticate using a service principal and OAuth 2.0
spark.conf.set("fs.azure.account.auth.type", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id", "enter-your-service-principal-application-id-here")
spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "secret-scope-name", key = "secret-name"))
spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com//enter-your-tenant-id-here/oauth2/token")
# read data in delta format
readdf=spark.read.format("delta").load(abfs://file-system-name@storage-account-name.dfs.core.windows.net/path-to-data")
This pattern works well where different permission groups (such as analysts and engineers) are required but one does not wish to take on the administrative burden of isolating the user groups by cluster. As in the previous approach, mounting folders using the provided service principal/secret scope details should be forbidden.
The mechanism which ensures that each group has the appropriate level of access is through their ability to “use” a service principal which has been added to the AAD group with the desired level of access. The way to effectively “map” the user group’s level of access to a particular service principal is by granting the Databricks user group access to the secret scope (see below) which stores the credentials for that service principal. Armed with the secret scope name and the associated key name(s), users can then run the authorisation code shown above. The “client.secret” (service principal’s secret) is stored as a secret in the secret scope but so to can any other sensitive details such as the service principals application ID and tenant ID.
The disadvantage to this approach is the proliferation of secret scopes of which there is a limit of 100 per workspace. Additionally the premium plan is required in order to assign granular permissions to the secret scope.
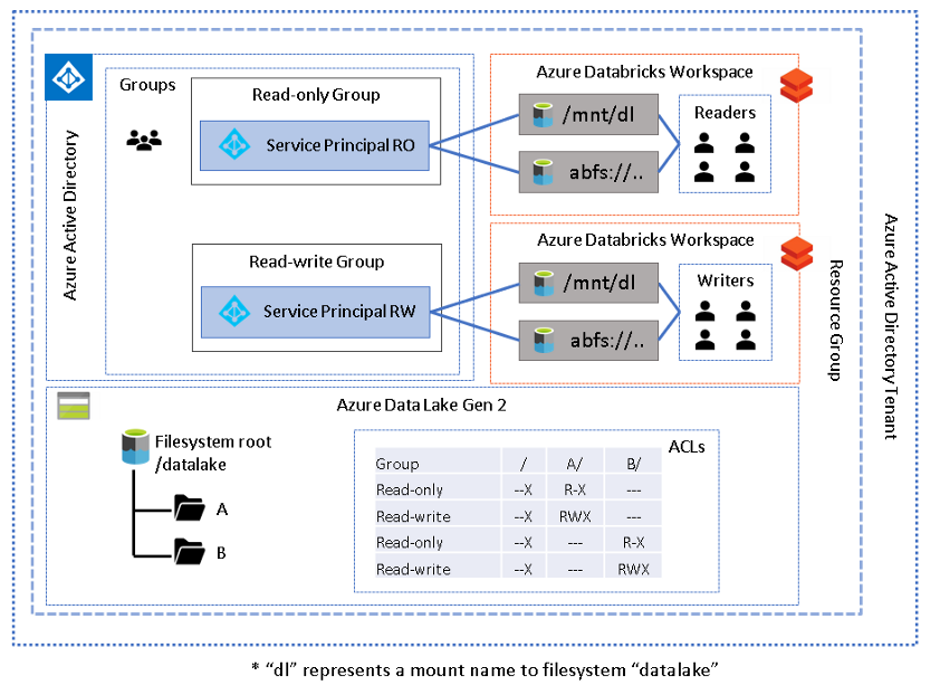
To help explain this pattern further, and the setup required, examine the following simple scenario:
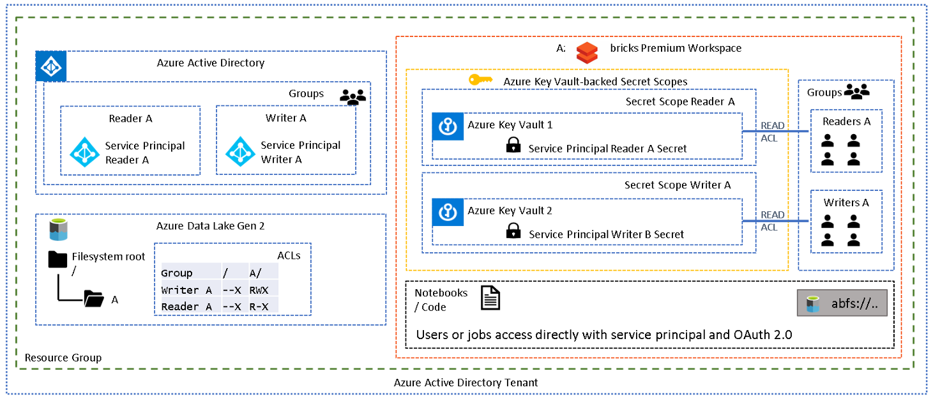
The above diagram depicts a single folder (A) with two sets of permissions, readers and writers. AAD groups reflect these roles and have been assigned appropriate folder ACLs. Each AAD group contains a service principal and the credentials for each service principal have been stored in a unique secret scope. Each group in the Databricks workspace contains the appropriate users, and the group has been assigned READ ACLs on the associated secret scope, which allows a group of users to “use” the service principal mapped to their level of permission.
Below is an example CLI command of how to grant read permissions to the “GrWritersA” Databricks group on “SsWritersA” secret scope. Note that ACLs are at secret scope level, not at secret level which means that one secret scope will be required per service principal.
databricks secrets put-acl --scope SsWritersA --principal GrWritersA --permission READ databricks secrets get-acl --scope SsWritersA --principal GrWritersA Principal Permission — — — — — — — — — — — — GrWritersA READ
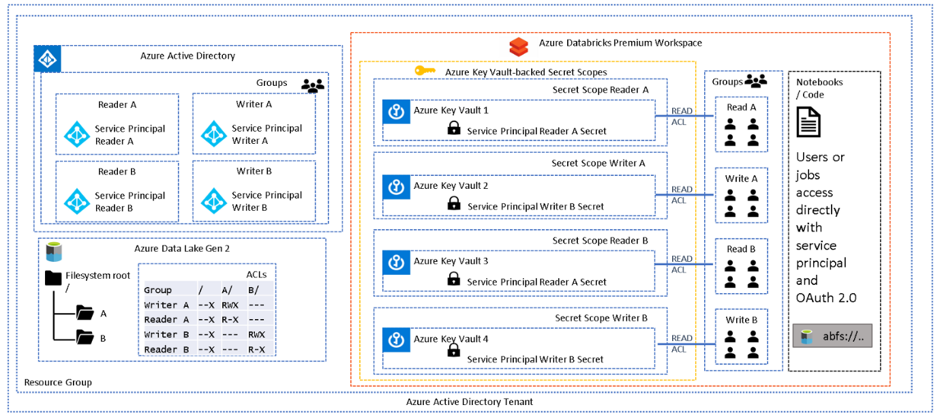
How this is may be implemented for your data lake scenario requires careful thought and planning. In very general terms this pattern being applied in one of two ways, at folder granularity, representing a department or data lake zone (1) or at data project or “data module” granularity (2):
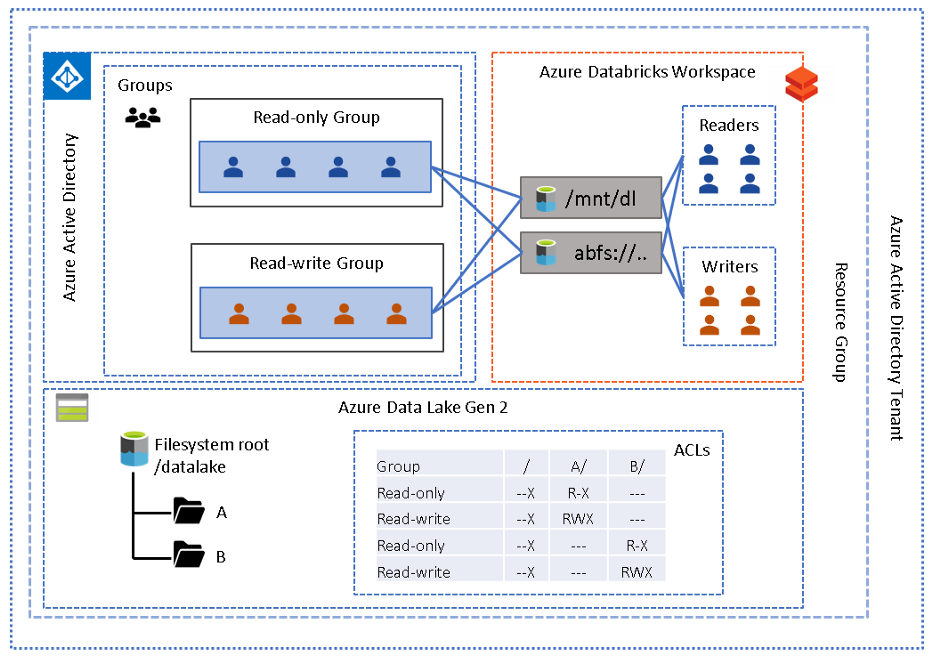
1. Analysts (read-only) and engineers (read-write) are working within a single folder structure, and they do not require access to additional datasets outside of their current directory. The diagram below depicts two folders A and B, perhaps representing two departments. Each department has their own analysts and engineers working on their data, and should not be allowed access to the other department’s data.
2. Using the diagram below for reference, engineers and analysts are working on different projects and should have clear separation of concerns. Engineers working on “Module 1” require read access to multiple source data assets (A & B). Transformations and joins are run to produce another data asset ( C ). Engineers also require a working or staging directory to persisting output during various stages (X). For the entire pipeline to execute, “Service Principal for Module 1 Developers” has been added to the relevant AAD groups which provide access to all necessary folders (A, B, X, C) through the assigned ACLs.
Analysts need to produce analytics using the new data asset ( C ) but should not have access to the source data, therefore, they use the “Service Principal for Dataset C” which was added to the Readers C group only.
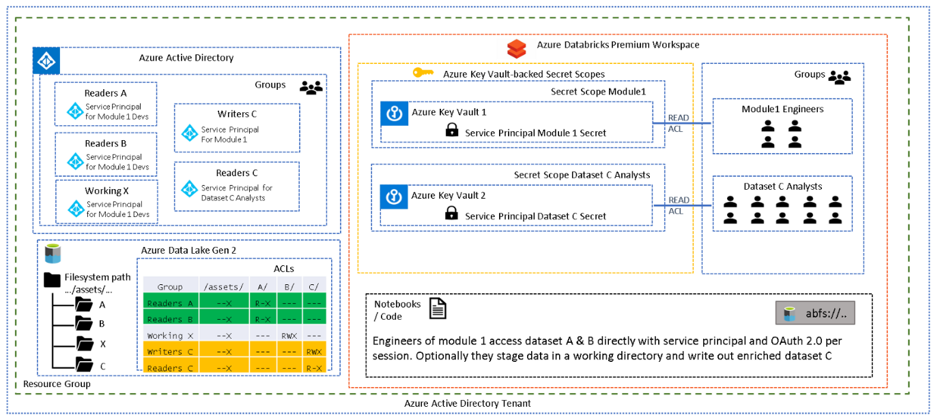
It may seem more logical to have one service principal per data asset but when multiple permissions are required for a single pipeline to execute in Spark, then one needs to consider how lazy evaluation works. When attempting to use multiple service principals in the same notebook/session one needs to remember that the read and write will be executed only once the write is triggered. One cannot therefore set the authentication to one service principal for one folder and then to another prior to the final write operation, all in the same notebook/session, as the read operation will be executed only when the write is triggered.
This means a single service principal will need to encapsulate the permissions of a single pipeline execution rather than a single service principal per data asset.
Pattern 6. Databricks Table Access Control
One final pattern, which not technically an access pattern to ADLS, implements security at the table (or view) level rather than the data lake level. This method is native to Databricks and involves granting, denying, revoking access to tables or views which may have been created from files residing in ADLS. Access is granted programmatically (from Python or SQL) to tables or views based on user/group. This approach requires both cluster and table access control to be enabled and requires a premium tier workspace. File access is disabled through a cluster level configuration which ensures the only method of data access for users is via the pre-configured tables or views. This works well for analytical (BI) tools accessing tables/views via odbc but limits users in their ability to access files directly and does not support R and Scala.
Conclusion
This article has examined a number of access patterns to Azure Data Lake gen2 available from Azure Databricks. There are merits and disadvantages of each, and most likely it will be a combination of these patterns which will suit a production scenario. Below is a table summarising the above access patterns and some important considerations of each.