


Orchestrating data with Azure Data Factory

The need for batch movement of data on a regular time schedule is a requirement for most analytics solutions, and Azure Data Factory (ADF) is the service that can be used to fulfil such a requirement. ADF provides a cloud-based data integration service that orchestrates the movement and transformation of data from various data stores.
What is orchestration?
Like a real orchestra, the conductor does not play the instruments, they simply lead the symphony members through the entire piece of music that they perform. ADF uses a similar approach, it will not perform the actual work required to transform data, but will instruct another service, such as a Hadoop Cluster, to perform a Hive query to perform the transformation on ADF’s behalf. So in this case, it would be Hadoop that performs the work, not ADF. ADF merely orchestrates the execution of the Hive query through Hadoop, and then provides the pipelines to move the data onto the next destination.
The Azure Data Factory Process
The process for Azure Data Factory can be summarised by the following graphic:
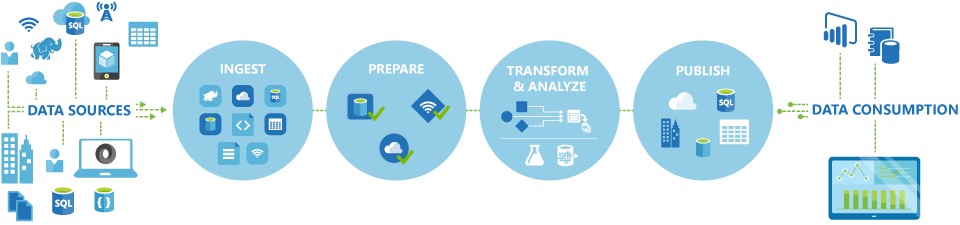
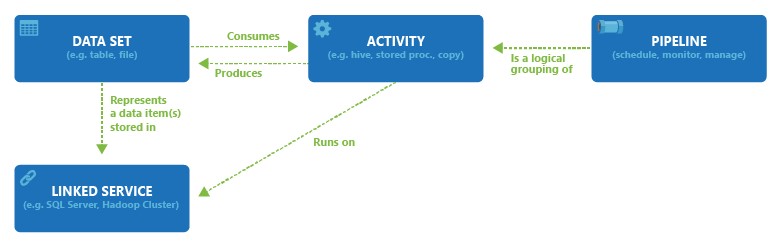
Data Factory supports a wide variety of data sources that you can connect to through the creation of an object known as a Linked Service. This enables you to ingest the data from a data source to prepare it for transformation and/or analysis. In addition, Linked Services can fire up compute services on demand. For example, you may have a requirement to start an on-demand Hadoop cluster for processing data through a Hive query. Therefore, Linked Services enables you to define data sources, or compute resource that are required to ingest and prepare data.
With the linked service defined, Azure Data Factory acquires data through a Datasets object. Datasets represent data structures within the data store that is being referenced by the Linked Service object.
Datasets can also be used by an ADF process known as an Activity. Activities typically contain the transformation logic or the analysis commands of the Azure Data Factory’s work. This could include the execution of a stored procedure, Hive Query or Pig script to transform the data. You can use U-SQL with Data Lake Analytics or push data into a Machine Learning model to perform analysis. It is not uncommon for multiple activities to take place that may include transforming data using a SQL stored procedure and then performing Data Lake Analytics with USQL. In this case, multiple activities can be logically grouped together with an object referred to as a Pipeline.
Once all the work is complete you can then use Data Factory to publish the final dataset to another linked service that can then be consumed by technologies such as Power BI or Machine Learning.
Therefore, the process discussed above can be summarised by the creation of the following objects as shown in this graphic:
Use cases
But I can move data with other tools right? Absolutely. Data movement could occur for example using SSIS to load data from SQL Server to Azure DW. However, it’s not the ideal tool to use to load data into Azure SQL DW if performance of the data loads is the key objective. PolyBase is, and we can use Azure Data Factory to orchestrate the PolyBase execution to load data into SQL Data Warehouse.
The other use case is if you want to call on demand services such as Hadoop clusters. ADF can be used to create an on demand cluster when it is required, and to shut it down once your work is complete. In which case, you can control the usage of the Azure resources to process your data, and only pay for what you use.
We can also use ADF to push data into Machine Learning models. This is particularly useful once a model has been productionised and you want to automate the process of feeding data to the Machine Learning model to perform its analytics. ADF can perform this activity with ease.


