
The service mesh may sound complex, but at its heart, it’s a very simple idea: a set of network proxies that transparently run alongside microservices, implementing reliability, observability, and security features by measuring and manipulating inter-service (“east-west”) traffic. Led by open source projects such as Linkerd, the service mesh model is increasingly popular because it addresses challenges, both computational and organizational, that occur with the adoption of microservices.
Over the past few years, the service mesh has risen to become a critical element of the cloud native stack. The first service mesh project, Linkerd, joined the Cloud Native Computing Foundation just last year, and has since grown to power the production infrastructure of companies around the globe, ranging from startups, like Monzo and OfferUp, to well-established companies, such as Comcast and Salesforce. Meanwhile, a host of other projects have followed hot on its heels, from cloud providers and startups alike. (See this video by Azure’s Lachlan Evenson on installing and run Linkerd 2.0 on Azure Kubernetes Service.)
In this article, we’ll define the service mesh and explain the various factors that are enabling the rise of service mesh adoption. Finally, we’ll provide a vision of where the service mesh is heading.
What is a service mesh?
At its heart, a service mesh is a distributed set of proxies that are deployed alongside microservices. Following common network terminology, these proxies are often referred to as the data plane, and are typically coordinated by a centralized component called the control plane. Critically, the data plane proxies handle both incoming and outgoing traffic for each microservice, typically without the application code even being aware.
The data plane proxies act as highly instrumented, out-of-process network stacks, and handle all traffic to and from a microservice. Because they’re centrally controlled, the service mesh can institute a variety of traffic control techniques globally across the application that provide reliability, observability, security, and more.
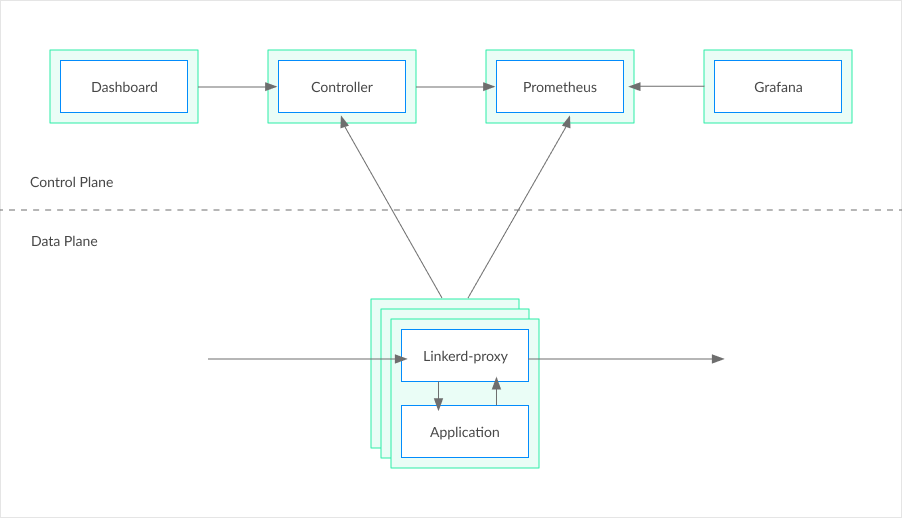
For example, the proxies can instrument all calls to a service, and provide “golden metrics,” such as success rates, latency distributions, and request volumes to that service, or even to individual paths. They can handle request retries and timeouts. They can encrypt communication transparently with TLS. And they can accomplish all these things without any involvement from the application itself.
Why use a service mesh?
For an industry that’s focused on speed and performance, the idea of adding user-space proxies in between every inter-service call can seem counterintuitive. Why introduce this new layer of complexity and latency?
The reason is more than the individual features. The service mesh provides something vital to operators: the ability to shift responsibility for much of the reliability, visibility, and security requirements out of the application code itself, down onto the underlying infrastructure. This shift means the platform itself can provide these features without developer involvement.
This decoupling of responsibility, and ability to provide reliability, visibility, and security globally across the application, are the fundamental value proposition of the service mesh.
Why are service meshes becoming so popular?
The rise of service meshes, such as Linkerd, is tied to a big shift in the industry: the adoption of cloud native architectures, in which an application is built as microservices, deployed as containers, and run on a container orchestration system, such as Azure Kubernetes Service (AKS).
The cloud native approach, in turn, is rapidly gaining popularity because it is uniquely suited to the increasingly strict demands that we place on our software systems. In the modern world, we expect our software applications to be resilient to failures in hardware, software, and network, as well as handle massive scale and maintain a breakneck pace of feature development. This is a far cry from the expectations we placed on software a decade ago, when “sorry, we’re down for maintenance” was acceptable!
The adoption of microservices especially allows us to meet those demands – not only at the technological level, but also at the organizational level. By breaking our applications into loosely-coupled microservices that can be developed and released independently of each other, we isolate our failure domains and provide ways for the application to remain functional even if individual components are failing. More importantly, we also remove organizational bottlenecks and allow our developers to iterate with a minimum of coordination required.
These changes in organization and software architecture require new types of tooling to provide visibility into what is happening; new ways to manage partial failures and prevent them from escalating into full-blown ones; and new ways to address policy for security and compliance. The service mesh is part and parcel of these changes.
The service mesh today
While many companies have adopted the service mesh as a critical component of their application infrastructure, the service mesh landscape today is still nascent and continues to evolve rapidly. A heady mix of assorted service mesh projects from cloud providers and startups alike have served to validate the approach, but the bewildering array of options can also be confusing.
As the CNCF service mesh project, and the project that “started it all,” Linkerd has had the best opportunity to learn from its community of adopters and contributors around the world. Based on these lessons, much of the recent focus has been on dramatically reducing the amount of complexity introduced by the service mesh, following the mantra of “less is more.” The recent release of Linkerd 2.0, focused on zero-config installation process and ultralight, Rust-based proxies, has demonstrated that adding a service mesh to an existing system doesn’t require inordinate amounts of configuration, conceptual overhead, or system resources.
As with all early technology patterns, the service mesh will continue to evolve rapidly over the next few years. It is, in the words of Kubernetes maintainer Tim Hockin, “an exciting time for boring infrastructure.”
Linkerd has a thriving community of adopters and contributors, and we’d love for YOU to be a part of it. For more, check out the docs and GitHub repo, join the Linkerd Slack and mailing lists (users, developers, announce), and, of course, follow @linkerd on Twitter. We can’t wait to have you aboard.
Questions or feedback? Let us know in the comments.