
An ONNX refresher
ONNX models are flexible, standardized representations of machine learning that allow them to be executed across a gamut of hardware platforms and runtime environments from large-scale cloud-based supercomputers to resource-constrained edge devices such as your web browser and phone.
Beyond its graph format, canonically represented using Protobuf, ONNX consists of a standard set of primitive operators which are implemented by runtimes and hardware vendors alike. With this broad ecosystem in mind, ONNX aims to keep the number of these operators low, encouraging composability through ONNX functions. This is important to reduce the overhead of supporting ONNX.
Typically, machine learning models are developed using higher-level frameworks such as PyTorch and TensorFlow. While these frameworks tend to be productive for iterating on the development of models, the models are not typically deployed to production in this fashion. Instead, they are exported to ONNX by facilities provided by the frameworks, and then optimized for a particular target by tools such as Olive.
Want to dive right into ONNX Script? Check it out on GitHub.
Announcing ONNX Script
ONNX Script is a new open-source library for directly authoring ONNX models in Python with a focus on clean, idiomatic Python syntax and composability through ONNX-native functions. Critically, it is also the foundation upon which we are building the new PyTorch ONNX exporter to support TorchDynamo—the future of PyTorch.
Prior to ONNX Script, authoring ONNX models required deep knowledge of the specification and serialization format itself. While eventually a more convenient helper API was introduced that largely abstracted the serialization format, it still required deep familiarity with ONNX constructs.
ONNX Script takes a new approach by integrating deeply with Python on two fronts:
- It provides a strongly typed API for all operators in ONNX (all 186 as of opset 19).1 This allows existing Python tooling, linters, and integrated development environments (IDEs) to provide valuable feedback and enforce correctness.
- ONNX Script supports idiomatic Python language constructs to make authoring ONNX more natural, including support for conditionals and loops, binary and unary operators, subscripting, slicing, and more. For example, the expression
a + bin Python would translate to the ONNX operator asAdd(a, b).
Let’s look at how we might implement GELU using ONNX Script and compare it with onnx.helper API—and to be clear—the examples below produce the same ONNX model. For reference, we’ll use this definition of GELU to guide the ONNX implementations:

As you can see, ONNX Script emphasizes the familiar readability and productivity of Python while expressing an ONNX model that can be statically reasoned about by existing Python and ONNX tooling.
This also means ONNX comes alive within the context of your existing tooling and development environments, be it debugging in Visual Studio Code or demonstrating concepts in a Jupyter Notebook—ONNX Script integrates naturally.
Why are we investing in ONNX Script?
Much has changed since ONNX support for PyTorch was originally introduced over five years ago in PyTorch 0.3.0. For PyTorch 2.0, TorchDynamo represents the eventual deprecation of TorchScript, which implies a major overhaul of the ONNX exporter is necessary. We are fully embracing this as an opportunity to revisit the fundamentals upon which the exporter is built, and ONNX Script is its new foundation. We began this effort in November 2022 and have worked closely with PyTorch engineers to ensure TorchDynamo is a fully capable starting point for exporting high-fidelity ONNX for years to come.
One of the first streams of work we started was the development of what we call Torchlib, a pure ONNX implementation of the operators in PyTorch—namely Core ATen IR and Prims IR—and of course, these operators are implemented in ONNX Script. This approach greatly simplifies the central responsibility of the exporter as it “just” needs to project FX graph nodes produced by TorchDynamo into ONNX graph nodes, without concerning itself with the implementation details of individual operators.
We will cover the new PyTorch ONNX exporter in a separate post with more depth as PyTorch 2.1 approaches, but for now, the key takeaway is that ONNX Script is pervasive throughout our renewed approach. For those willing to try bold new things, the new exporter is available as a preview in PyTorch nightly via the torch.onnx.dynamo_export API.
By deeply weaving ONNX Script support into the PyTorch ONNX exporter, we have also made it possible to augment PyTorch model code with specialized ONNX functions as custom operators. We introduced initial support for this in the TorchScript exporter starting with PyTorch 1.13 and continue to refine this capability in the new exporter.
An end-to-end example
Let’s look at an example slightly more complicated than GELU. In fact, the following example is adapted directly from the new PyTorch ONNX exporter, implementing support for torch.chunk, which attempts to split a tensor into the number of specified chunks.
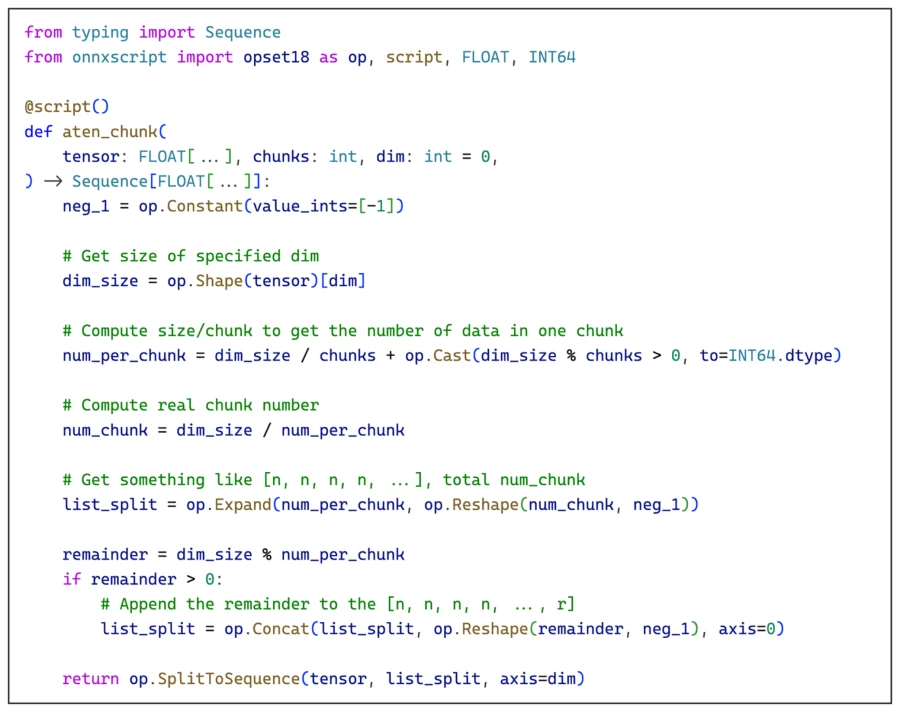
We start by importing from onnxscript the ONNX opset we wish to use (version 18 in this case), the @script decorator, and the tensor types of FLOAT and INT64. In ONNX Script, tensor shapes are denoted by subscripting the type, such as FLOAT[2, 10], symbolically such as FLOAT["M", "N"], or FLOAT[...] incase the tensor shape is unknown. Without subscripting (just FLOAT), the type is intended to indicate a scalar (a tensor of rank 0).
Next, we define the aten_chunk function with type annotations and implement the body of the function using both built-in Python syntax and explicit invocations of ONNX operators. The example uses various binary expressions and an if statement, but many other idiomatic Python constructs are also supported.
We also need to define a simple model that calls our ONNX Script function so we can export and verify an end-to-end example:

This model will simply split the provided tensor into ten tensors, but it also demonstrates that ONNX functions can of course call other ONNX functions, not just built-in ONNX operators.
We’ll now export our ONNX Script model to ONNX and explore it in Netron. Functions decorated with @script allow them to be exported using the to_model_proto function.

If we open ten_chunks_model.onnx in Netron, we can observe the composability of ONNX functions and how the Python code was translated into an ONNX model.
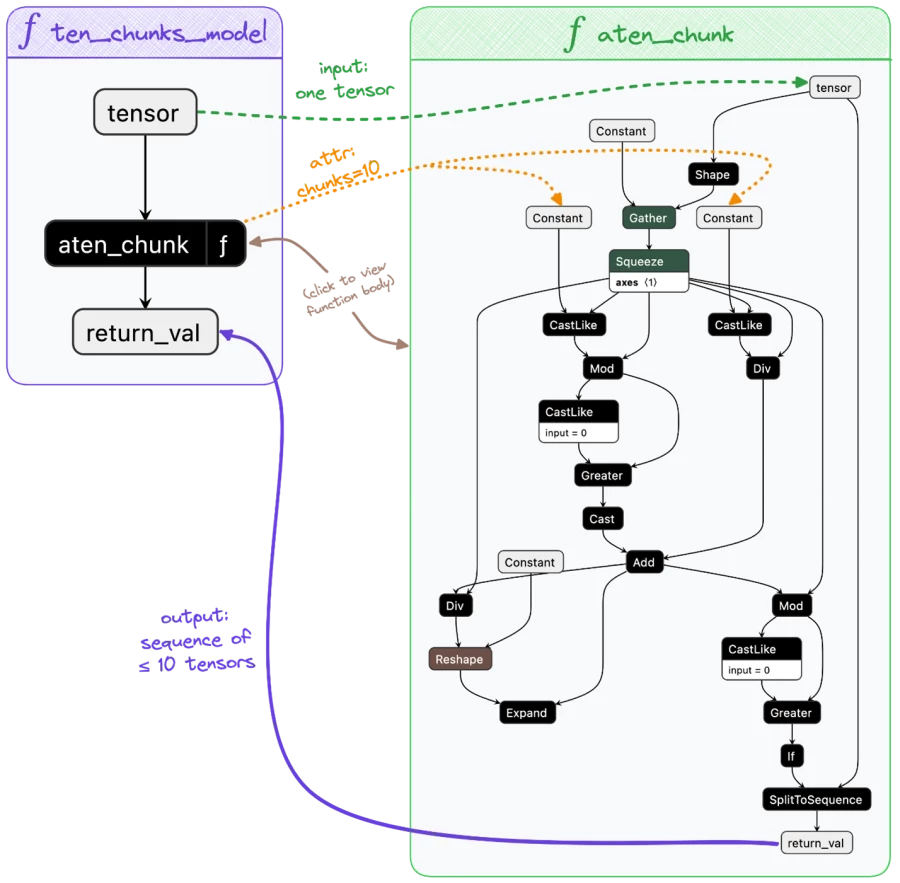
The graphs depict our two ONNX functions. We can observe the original input tensor flowing from ten_chunks_model into aten_chunk along with the attribute chunks=10. A sequence of ≤ 10 tensors is returned. As one might expect, functions in ONNX can be defined once and invoked any number of times within a model. Read more about core ONNX concepts.
Iterating and debugging
Finally, we should test our model. ONNX Script makes this easy since it provides a mechanism for eagerly evaluating the model through either ONNX Runtime or the new ONNX Reference Evaluator. Of note, ONNX Script has built-in support for NumPy for input and output values to ease the overhead of creating and filling tensors in ONNX.


Because ONNX Script’s eager mode evaluates the model on an op-by-op basis, it is conducive to debugging ONNX using standard Python tooling such as pdb directly or through richer IDE and editor integrations provided by Visual Studio and Visual Studio Code.
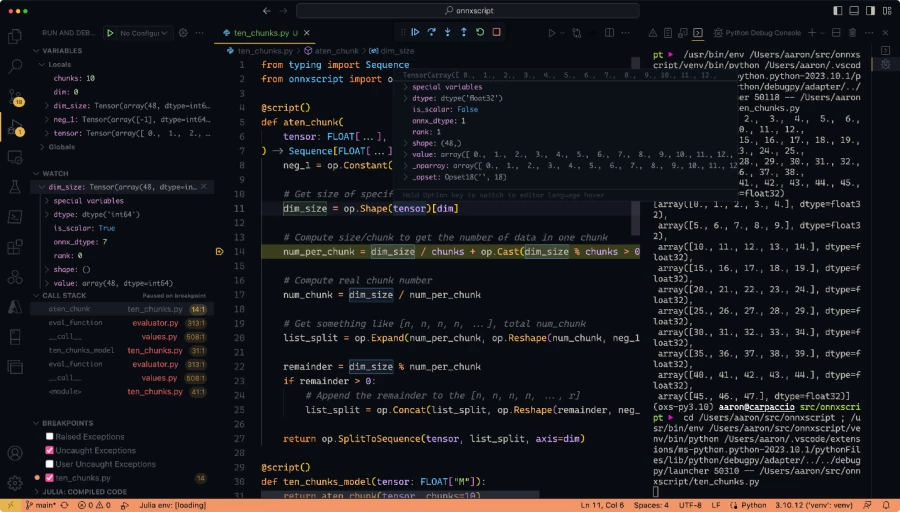
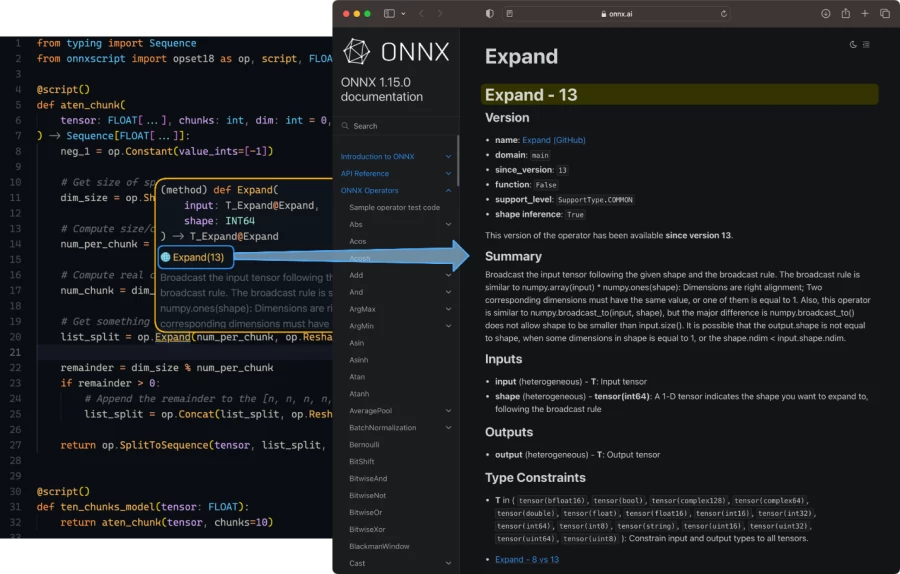
dim_size variable and call stack.Along with debuggability, IntelliSense support is front-and-center with ONNX Script. We rely heavily on Python type annotations to enforce the correctness of ONNX and to make ONNX more discoverable, including inline documentation on hover tooltips and code completion suggestions. A single click will take you to expanded online documentation in your browser as well.
What’s next for ONNX Script?
In summary, ONNX Script offers a new Python-first programming model for authoring ONNX models that integrates with the existing rich ecosystem of Python tooling and environments.
Going forward, we envision ONNX Script as a means for defining and extending ONNX itself. New core operators and higher-order functions that are intended to become part of the ONNX standard could be authored in ONNX Script as well, reducing the time and effort it takes for the standard to evolve. We have proven this is a viable strategy by developing Torchlib, upon which the upcoming PyTorch Dynamo-based ONNX exporter is built.
Over the coming months, we will also support converting ONNX into ONNX Script to enable seamless editing of existing models, which can play a key role in optimization passes, but also allow for maintaining and evolving ONNX models more naturally. We also intend to propose ONNX Script for inclusion directly within the ONNX GitHub organization soon, under the Linux Foundation umbrella.
Check out ONNX Script today on GitHub!
A huge thank you to the wonderful engineering team at Microsoft that has brought us to this point so far: Bowen Bao, Aaron Bockover, Shubham Bhokare, Jacky Chen, Wei-Sheng Chin, Justin Chu, Thiago Crepaldi, Xavier Dupre, Liqun Fu, Xaiowu Hu, Ganesan Ramalingam, Ti-Tai Wang, Jay Zhang.