
Model training has been and will be in the foreseeable future one of the most frustrating things machine learning developers face. It takes quite a long time and people can’t really do anything about it. If you have the luxury (especially at this moment of time) of having multiple GPUs, you are likely to find Distributed Data Parallel (DDP) helpful in terms of model training. DDP performs model training across multiple GPUs, in a transparent fashion. You can have multiple GPUs on a single machine, or multiple machines separately. DDP can utilize all the GPUs you have to maximize the computing power, thus significantly shorten the time needed for training.
For a reasonably long time, DDP was only available on Linux. This was changed in PyTorch 1.7. In PyTorch 1.7 the support for DDP on Windows was introduced by Microsoft and has since then been continuously improved. In this article, we’d like to show you how it can help with the training experience on Windows.
Walkthrough
For reference, we’ll set up two machines with the same spec on Azure, with one being Windows and the other being Linux, then perform model training with the same code and dataset.
We use this very nice resource in Azure called a Data Science Virtual Machine (DSVM). This is a handy VM image with a lot of machine learning tools preinstalled. At the time of writing, PyTorch 1.8.1(Anaconda) is included in the DSVM image, which will be what we use for demonstration.
You can search directly for this resource:
You can also follow the normal VM creation process and choose the desired DSVM image:
In this article, we use the size “Standard NC24s_v3”, which puts four NVIDIA Tesla V100 GPUs at our disposal.
To better understand how DDP works, here are some basic concepts we need to learn first.
One important concept we need to understand is “process group”, which is the fundamental tool that powers DDP. A process group is, as the name suggests, a group of processes. Each of the processes is responsible for the training workload of one dedicated GPU. Additionally, we need some method to coordinate the group of processes (more importantly, the GPUs behind them), so that they can communicate with each other. This is called “backend” in PyTorch (–dist-backend in the script parameter). In PyTorch 1.8 we will be using Gloo as the backend because NCCL and MPI backends are currently not available on Windows. See the PyTorch documentation to find more information about “backend”. And finally, we need a place for the backend to exchange information. This is called “store” in PyTorch (–dist-url in the script parameter). See the PyTorch documentation to find out more about “store”.
Other concepts that might be a bit confusing are “world size” and “rank”. World size is essentially the number of processes participating in the training job. As we mentioned before, each process is responsible for one dedicated GPU. Thus, world size also equals to the total number of GPUs used. Pretty straightforward, right? Now let’s talk about “rank”. Rank can be seen as an index number of each process, which can be used to identify one specific process. Note that a process with rank 0 is always needed because it will act like the “controller” which coordinates all the processes. If the process with rank 0 doesn’t exist, the entire training is a no-go.
With the necessary knowledge in our backpack, let’s get started with the actual training. We use a small subset of ImageNet 2012 as the dataset. Let’s assume we have downloaded and placed our dataset at some location in the filesystem, we’ll use “D:\imagenet-small” for this demonstration.
Obviously, we also need a training script. We use the imagenet training script from PyTorch Examples repo and ResNet50 as the target model. The training script here can be seen as a normal training script, plus the DDP power provided packages like “torch.distributed” and “torch.multiprocessing”. The script doesn’t contain too much logic and you can easily set up your own script based on it. You can also refer to this Getting Started tutorial for more inspiration.
On a single machine, we can simply use FileStore which is easier to set up. The complete command looks like this:
> python main.py D:\imagenet-small --arch resnet50 --dist-url file:///D:\pg --dist-backend gloo --world-size 1 --multiprocessing-distributed --rank 0
You probably noticed that we are using “world-size 1” and “rank 0”. This is because the script will calculate the desired world size and rank based on the available GPUs. Here the actual world size used is the same as the number of GPUs available, which is four. The rank of each process will also be automatically assigned with the correct number, starting from zero.
If you’re not a fan of command-line arguments, you can also use environment variables to initialize the DDP arguments. This might be helpful if you need to automate the deployment. More details can be found in the “Environment variable initialization” section of the PyTorch documentation.
If everything goes well, the training job will start shortly after.
Troubleshooting
If something doesn’t go well, here are some troubleshooting tips that might be helpful:
- If you’re using FileStore on Windows, make sure the file used is not locked by other processes, which can happen if you forcefully kill the training processes. This can lead to freezing of the DDP training process, because the script fails to initialize the FileStore. A workaround is to manually kill previous training processes and delete the file before you conduct the next training.
- If you’re using TcpStore, make sure the network is accessible and the port is in fact available. Otherwise, the training may freeze because the script fails to initialize the TcpStore. The process with rank zero will bind and listen on the port you provided. Other processes will try to connect to that port. You can use network monitoring tools like “netstat” to help debugging the TCP connection issue.
- You can use tools like nvidia-smi to monitor the GPU load while performing the training. Ideally, we want all the GPUs fully utilized and running at 100 percent usage. If you find that the GPU load is low, you may want to increase the batch size and/or the number of DataLoader workers.
- Be aware that the number of GPUs used in DDP also affects the effective batch size. For example, if we use 128 as batch size on a single GPU, and then we switch to DDP with two GPUs. We have two options: a) split the batch and use 64 as batch size on each GPU; b) use 128 as batch size on each GPU and thus resulting in 256 as the effective batch size. Besides the limitation of the GPU memory, the choice is mostly up to you. You can tweak the script to choose either way. Remember to also adjust the initial learning rate if you choose option b) and expect a similar training result.
Benchmark
Back to our benchmarking mission. First, we tried to perform the training without using DDP to establish a baseline. Then we tried the DDP setup with two GPUs, then finally with four GPUs. These are the results:
| Duration | 1 GPU (No DDP) | 2 GPUs | 4 GPUs |
| Linux | 56m 58s | 31m 7s | 17m 20s |
| Windows | 58m 55s | 31m 55s | 19m 3s |
To better visualize it, we plot it as the chart below:
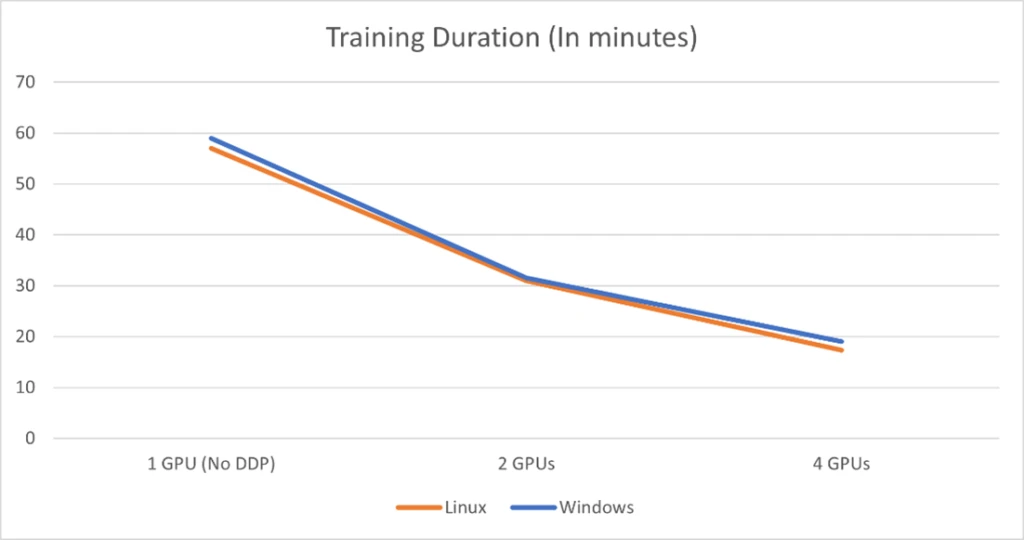
As we can see from the data, the acceleration from additional GPUs meets our overall expectations. Using two GPUs cuts training duration to almost half. And using four GPUs makes it nearly one-quarter.
In terms of accuracy, here’s the loss curve we see on both Windows and Linux:
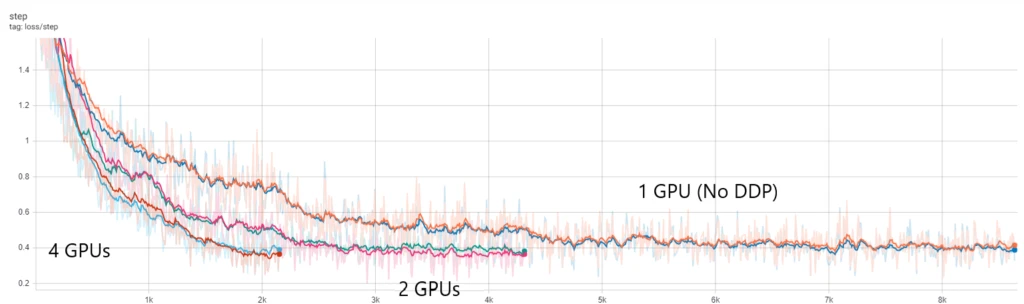
We can tell from the loss curve that the shortening of training time does not end up with a bad training result. We can still expect the model to be gradually trained over time.
This is of course only a small demonstration of how DDP on Windows can bring users a performance boost that is comparable to the one on Linux, without compromising accuracy. We at Microsoft are working closely with PyTorch team to keep improving the PyTorch experience on Windows. The support of DDP on Windows is a huge leap ahead in terms of training performance. We’d like to encourage people to try it and we’d love to hear your feedback.