
In-browser machine learning (ML) enables web applications to execute machine learning models entirely client-side in the browser. As a key player of on-device AI, it has garnered significant interest thanks to advantages in privacy protection, enhanced portability, as well as cost and latency savings by eliminating client-server communication. Nevertheless, the rise of large generative models brings a challenge for in-browser ML, as executing these models demands increased computational power and memory resources.
ONNX Runtime Web is the web-inference solution offered in ONNX Runtime. This blog is thrilled to announce the official launch of ONNX Runtime Web featuring WebGPU in the ONNX Runtime 1.17 release. This innovation unlocks new possibilities for executing state-of-the-art sophisticated models like Stable Diffusion Turbo directly in the browser. It is particularly advantageous in scenarios where CPU-based in-browser ML falls short of meeting performance standards. This post will delve into how ONNX Runtime Web equipped with WebGPU accelerates in-browser machine learning and guide the users on leveraging this capability.
A glance at ONNX Runtime Web with WebGPU
WebGPU introduces a modern web API to enable web developers to use the underlying system’s GPU to carry out high-performance computations. Compared to WebGL, WebGPU is capable of handling more complex machine learning workloads in a more efficient way with advanced features such as compute shader. Its support for half-precision (FP16) reduces GPU memory usage and bandwidth requirements while accelerating arithmetic. WebGPU promises inferencing more efficient and scalable machine learning applications directly within the web browser by harnessing GPU power for parallel computation tasks.
ONNX Runtime Web is a JavaScript library to enable web developers to deploy machine learning models directly in web browsers, offering multiple backends leveraging hardware acceleration. For CPU inference, it compiles the native ONNX Runtime CPU engine into the WebAssembly (WASM) backend. By doing that, ONNX Runtime Web can effectively run common machine learning models and it has been widely adopted by various web applications such as Transformer.js.
To address the challenges posed by large and complex generative models in browsers, which demand greater computational and memory resources beyond the capabilities of CPU execution, ONNX Runtime Web now enables the WebGPU backend. Moreover, Microsoft and Intel are collaborating closely to bolster WebGPU backend further. This includes implementing WebGPU operators for broader model coverage, enabling IOBinding to save GPU-CPU data copies, adding FP16 support for improved performance, memory efficiency, and more.
Accelerate Segment Anything encoder by 19 times
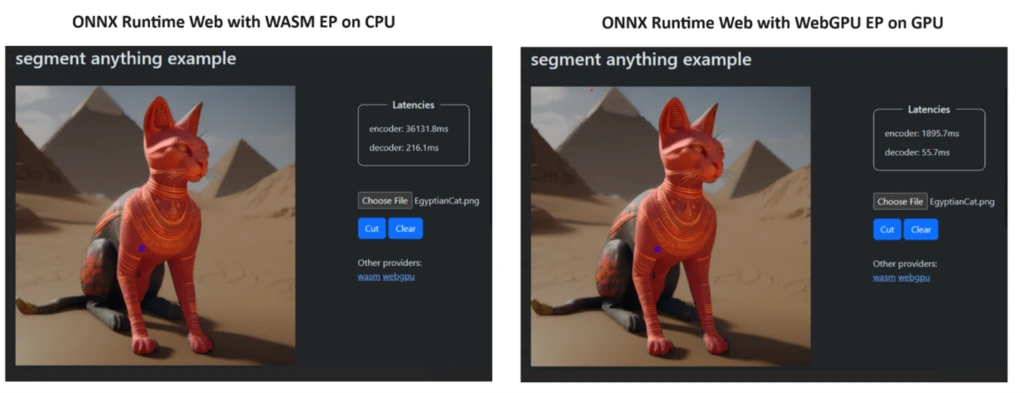
To demonstrate the power of WebGPU on the performance of ONNX Runtime Web, we developed a demo using the Segment Anything model, incorporating both WASM EP and WebGPU EP. Meta has introduced the Segment Anything Model, an advanced image segmentation technology aiming to transform the landscape of computer vision. With Segment Anything, users can efficiently identify and isolate specific objects within an image through a few straightforward clicks. As depicted in the screenshot, on a laptop with NVIDIA GeForce RTX 3060 and Intel Core i9, ONNX Runtime Web with WebGPU accelerates the Segment Anything encoder part by 19 times and the decoder part by 3.8 times.
As of now, Stable Diffusion Turbo stands out as the most efficient AI technology for image generation. With the power of WebGPU, it is now possible to execute Stable Diffusion Turbo directly in the browser, achieving results within one second on an RTX 4090. Here is the end-to-end example of running Stable Diffusion Turbo in the browser with ONNX Runtime Web with WebGPU. Transformers.js, a popular JavaScript library for running Transformers directly in the browser, has been powered by ONNX Runtime Web with WASM backend, and now a majority of its models can be accelerated by WebGPU backend. We are collaborating with Transformer.js team to officially unveil WebGPU accelerations through ONNX Runtime Web.
Get started with ONNX Runtime Web
WebGPU has been included by default since Chrome 113 and Edge 113 for Mac, Windows, ChromeOS, and Chrome 121 for Android. Ensure that your browser is compatible with WebGPU. You can also monitor support for other browsers. Additionally, for inference using mixed precision (FP16), please note that FP16 support for WebGPU was introduced since the recent Chrome and Edge releases (version 121).
The experience utilizing different backends in ONNX Runtime Web is straightforward. Simply import the relevant package and create an ONNX Runtime Web inference session with the required backend through the Execution Provider setting. We aim to simplify the process for developers, enabling them to harness different hardware accelerations with minimal effort.
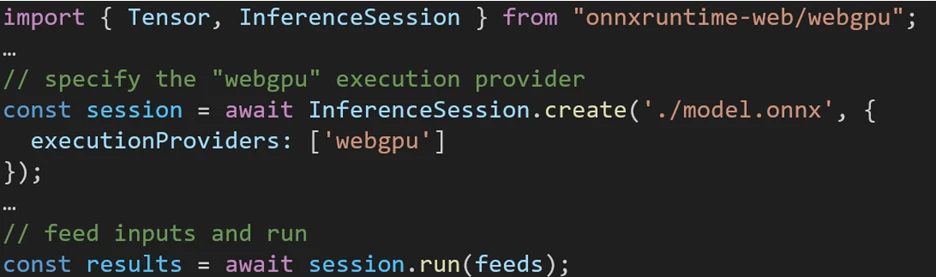
The following code snippet shows how to call ONNX Runtime Web API to inference a model with WebGPU. Additional ONNX Runtime Web documentation and examples are accessible for delving deeper.
Try ONNX Runtime Web
This blog post introduces how ONNX Runtime Web accelerates generative models in the browser by leveraging WebGPU. Benchmark results are included to illustrate the improvements, along with instructions to assist you in getting started with ONNX Runtime Web using WebGPU. Further model coverage improvement and perf optimization are underway, so stay tuned.
We encourage you to try ONNX Runtime Web out and share your feedback in the ONNX Runtime GitHub repository!
We would like to extend our heartfelt appreciation to the Intel Web Graphics Team for their invaluable contribution to the WebGPU development in ONNX Runtime Web. Their expertise, support, and collaboration have played a significant role in the success of this project.