
ONNX Runtime Web unleashes generative AI in the browser using WebGPU
This blog is thrilled to announce the official launch of ONNX Runtime Web featuring WebGPU, now available in the ONNX Runtime 1.17 release. Read more
This blog is thrilled to announce the official launch of ONNX Runtime Web featuring WebGPU, now available in the ONNX Runtime 1.17 release. Read more
Introducing Olive, an easy-to-use toolchain for optimizing models with hardware awareness. With Olive, you don’t need to be an expert to explore diverse hardware optimization toolchains. Read more
Intel has collaborated with Microsoft to integrate Intel® Neural Compressor into Olive, enabling developers to easily take advantage of model compression techniques in their deployment platform, including Intel processors and accelerators. Read more
Mohit Ayani, Solutions Architect, NVIDIA Shang Zhang, Senior AI Developer Technology Engineer, NVIDIA Jay Rodge, Product Marketing Manager-AI, NVIDIA Transformer-based models have revolutionized the natural language processing (NLP) domain. Ever since its inception, transformer architecture has been integrated into models like Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-trained Transformer (GPT) for performing tasks Read more
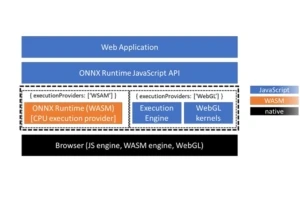
We are introducing ONNX Runtime Web (ORT Web), a new feature in ONNX Runtime to enable JavaScript developers to run and deploy machine learning models in browsers. It also helps enable new classes of on-device computation. ORT Web will be replacing the soon to be deprecated onnx.js, with improvements such as a more consistent developer Read more
“With its resource-efficient and high-performance nature, ONNX Runtime helped us meet the need of deploying a large-scale multi-layer generative transformer model for code, a.k.a., GPT-C, to empower IntelliCode with the whole line of code completion suggestions in Visual Studio and Visual Studio Code.” Large-scale transformer models, such as GPT-2 and GPT-3, are among the most Read more
This post is co-authored by Emma Ning, Azure Machine Learning; Nathan Yan, Azure Machine Learning; Jeffrey Zhu, Bing; Jason Li, Bing One of the most popular deep learning models used for natural language processing is BERT (Bidirectional Encoder Representations from Transformers). Due to the significant computation required, inferencing BERT at high scale can be extremely Read more