
Hardware-aware model optimization is the process of optimizing machine learning models to make the most efficient use of specific hardware architectures—like CPUs, GPUs, and neural processing units (NPUs)—to meet production requirements such as accuracy, latency, and throughput. However, it can be challenging. Firstly, it requires expertise in various independent hardware vendor (IHV) toolkits to handle the unique characteristics and optimizations needed for each hardware architecture. Secondly, aggressive optimizations can have an impact on model quality, balancing accuracy and efficiency within hardware constraints needs to be carefully managed. Additionally, the rapidly evolving hardware landscape necessitates constant updates and adaptations.
To alleviate this burden, we introduce Olive, an easy-to-use toolchain for optimizing models with hardware awareness. With Olive, you don’t need to be an expert to explore diverse hardware optimization toolchains. It handles the complex optimization process for you, ensuring you achieve the best possible performance without the hassle.
Easing model optimization across hardware with Olive
As a hardware-aware model optimization solution, Olive composes effective techniques in model compression, optimization, and compilation. As shown in Figure 1, for a given model and target hardware, Olive intelligently tunes the most appropriate optimization techniques to generate highly efficient models for inference. Currently, a range of optimization techniques is supported in Olive, including model quantization tuning, transformer optimization, ONNX Runtime performance tuning, and more. Moreover, Olive considers various constraints such as accuracy and latency to ensure the optimized models meet your specific requirements. Olive streamlines the process of optimizing machine learning models to make the most efficient use of specific hardware architectures. Whether you’re working on cloud-based applications or edge devices, Olive enables you to optimize your models effortlessly and effectively. It works with ONNX Runtime, a high-performance inference engine, as an end-to-end inference optimization solution.
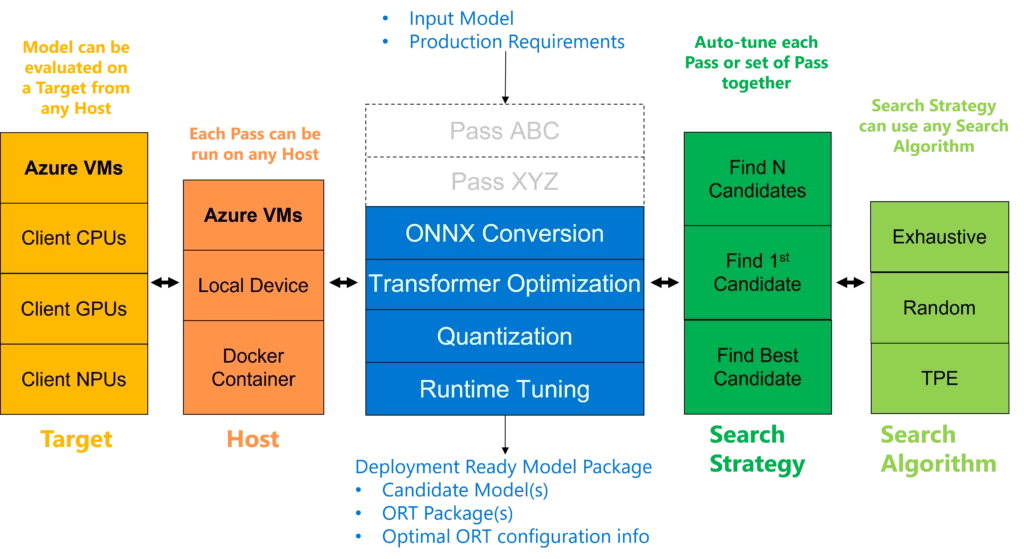
Figure 1: Olive architecture
By providing a configuration file specifying your model and scenario-specific information, Olive tunes optimization techniques to generate the optimal model(s) on the Pareto frontier based on the metrics goal you set. When working with the configuration file, you typically need to provide information about the input model—including input names, shapes, and the location where the model is stored. Moreover, you specify your performance preferences, such as desired latency, accuracy, or other relevant factors. In addition to this information, you can choose from a range of optimizations provided by Olive that you wish to apply to your specific hardware target. You also have the option to define the target hardware and utilize any additional features offered by Olive. By utilizing the configuration file, all you need to do is execute a simple command, eliminating the need for any Python code.
python -m olive.workflows.run --config my_model_acceleration_description.json
Here are comprehensive examples that demonstrate the process of optimizing models with Olive for various hardware targets. During the Microsoft Build 2023 conference, we showcase how Olive and the ONNX Runtime (ORT) optimize a whisper model, demonstrating a remarkable reduction in end-to-end latency by over two times on Intel Xeon device and a decrease in model size by 2.25 times, as shown in Figure 2.
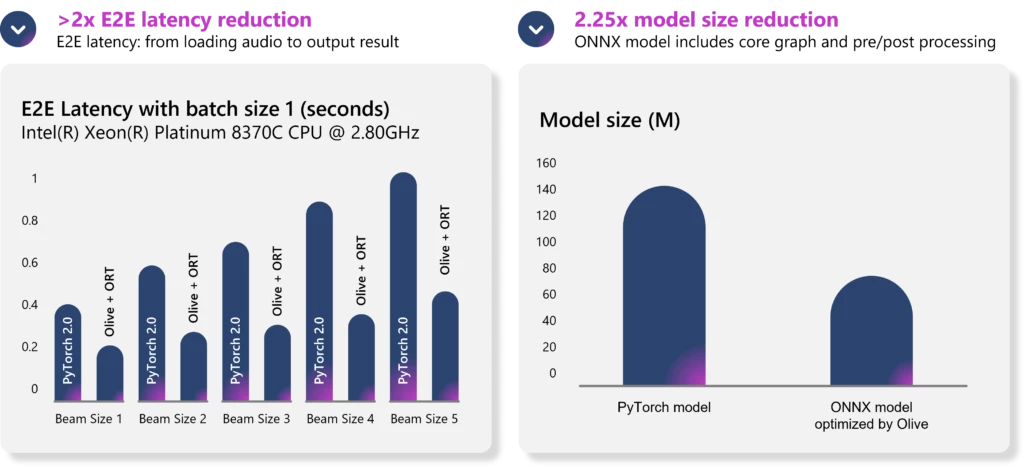
Figure 2: Whisper model optimization with Olive and ORT
Intel and AMD optimization innovations in Olive
In addition to simplifying the model optimization experience for model developers, Olive also provides a unified framework that allows industry experts to plug in their own optimization innovations as optimization passes into Olive, resulting in a comprehensive and ready-to-use solution. Intel and AMD have integrated their optimization innovations in Olive. Learn more about contributing your optimization techniques.
- Intel Neural Compressor (INC). The Intel Neural Compressor framework develops several techniques for model compression to better leverage Intel hardware, such as quantization, pruning, and knowledge distillation. Now INC quantization, including both static quantization and dynamic quantization, is available in Olive. Learn more by reading this example and our blog. More compression techniques will be added to Olive in the future.
- AMD Vitis-AI quantizer. Vitis-AI quantizer is a tool provided by AMD as part of the Vitis-AI development platform. It is designed to facilitate model quantization for efficient deployment of deep learning models on AMD hardware platforms. You can easily set Vitis-AI quantizer in Olive for quantizing your model to get performance acceleration on AMD hardware. Here is an example.
Streamlining user experience through Olive
To overcome any potential user hesitations surrounding technology that prioritizes performance gains over ease of use, Olive is dedicated to enhancing the user experience across various scenarios. This commitment is demonstrated through the implementation of a wide range of highlighted features that aim to improve usability and satisfaction for users:
- Model packaging: Olive can produce a comprehensive package that includes optimized models, the appropriate runtime, and sample code for executing the model. This empowers you to effortlessly deploy the optimized models within your application.
- Easy access Microsoft Azure Machine Learning resources and assets: By utilizing your Azure Machine Learning authentication credentials, Olive can establish a connection with Azure Machine Learning. This connection enables Olive to access your registered model, as well as optimize the model for cloud computing within the Azure environment.
- Built-in support for HuggingFace model optimization: The utilization of HuggingFace models has gained widespread popularity. Olive enhances this experience by seamlessly enabling the direct utilization of HuggingFace models, datasets, and metrics for optimizing and assessing HuggingFace models.
Looking ahead
Performance and ease of use are key priorities in Olive. Our ongoing efforts include collaborating with hardware partners to incorporate their latest technologies into Olive, making it the most comprehensive solution for model optimization. Simultaneously, we are committed to enhancing usability—ensuring a smoother and more accessible model optimization experience for all users.
If you have any feedback or questions regarding Olive, please don’t hesitate to file an issue on GitHub. We highly encourage you to do so, and our team will promptly follow up to address your concerns and provide assistance.