
Olive is an easy-to-use hardware-aware model optimization tool by Microsoft which builds up a unified optimization framework to enable independent hardware vendors (IHVs) extend their capabilities to include their state-of-the-art and hardware-specific optimization toolchains. The Intel® Neural Compressor is an open-source library supporting popular advanced model compression technologies, from techniques used in the industry to the latest state-of-the-art from research. Intel has collaborated with Microsoft to integrate Intel® Neural Compressor into Olive, enabling developers to easily take advantage of model compression techniques in their deployment platform, including Intel processors and accelerators.
The rest of this blog is organized as follows:
1) We first provide an introduction to the toolchains, including Intel Neural Compressor.
2) We then walk through a step-by-step example, on how to optimize popular workloads like transformer-based models from Hugging Face.
3) Finally, we conclude by summarizing performance gains and accuracy results obtained by using Olive and Intel Neural Compressor to optimize GPT-J, Bert-Base, and RoBERTa.
Olive with Intel® Neural Compressor
Olive is a user-friendly tool for optimizing models with hardware awareness. It combines top-notch techniques across model compression, optimization, and compilation. By considering a given model, target hardware, as well as deployment constraints such as accuracy and latency, Olive tunes the most suitable optimization techniques to generate highly efficient models for inferencing across operating environments, platforms, and devices.
Intel® Neural Compressor provides popular model compression techniques such as quantization, pruning (sparsity), distillation, and neural architecture search for mainstream frameworks such as PyTorch*, TensorFlow*, and ONNX Runtime.
By integrating the Intel® Neural Compressor quantizer into Olive’s optimizations, as shown in figure 1, developers can benefit from automatic selection of optimizations based on their target deployment platform. For example, developers can easily optimize their models with Olive to take advantage of Intel hardware acceleration technologies such as Intel® Advanced Matrix Extensions (Intel® AMX) and Intel® DL Boost. With Intel® DL Boost, developers can get up to 4 times theoretical performance speedups compared to the FP32 baseline models, and even higher speedups when using Intel® AMX while meeting your model accuracy requirements.
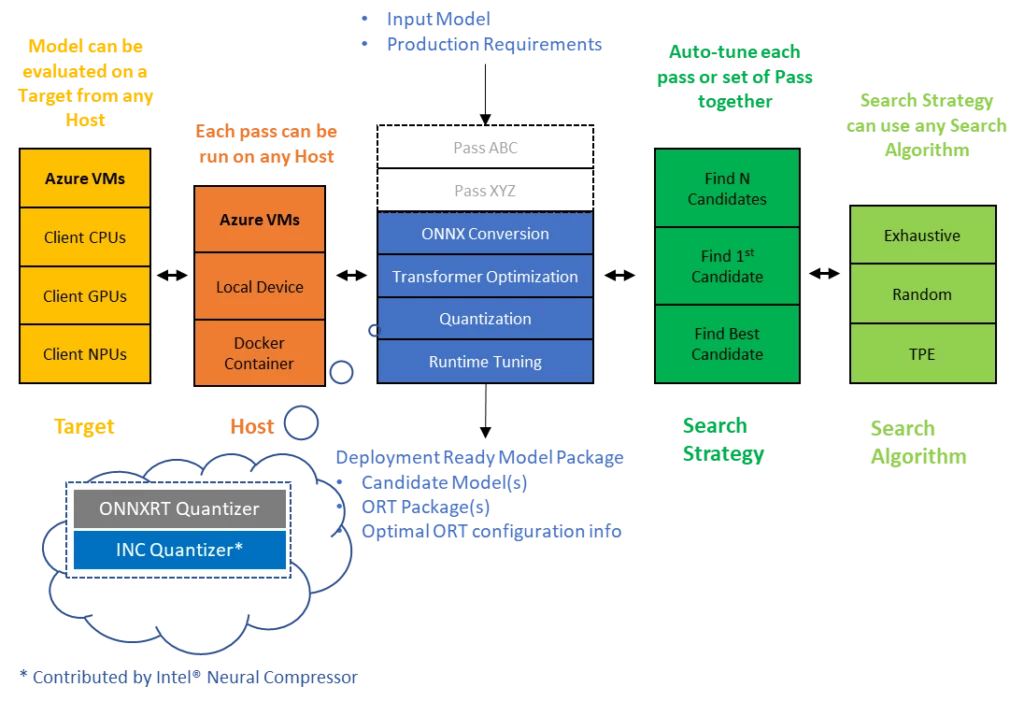
Figure 1: Olive Architecture
Over two times speedup with Hugging Face transformer models
Model Enabling
In this section, we’ll explain how to optimize Hugging Face Bert-Base model. We’ll leverage Intel® Neural Compressor’s quantization capabilities, which supports static and dynamic, and have been integrated into Olive. Olive model optimization workflows are defined using JSON files and each optimization is named as a pass. Intel® Neural Compressor’s quantization techniques have been incorporated into Olive as a single pass named, ‘IncQuantization’, providing developers with the ability to tune quantization methods and hyperparameters at the same time.
The following steps illustrate how developers can use Olive with ‘IncQuantization’ to accelerate a Hugging Face Bert-Base model:
1. Add ‘IncQuantization’ to ‘passes’ in a config.json file

Figure 2: IncQuantization pass
2. Define the dataset and dataloader needed by ‘IncQuantizaton’ for model calibration and validation. To achieve this, Olive provides the flexibility for developers to feed their data via a separate Python file: ‘user_script.py’. The following shows how IncQuantizaton users feed calibration data to tune and validate quantization accuracy.
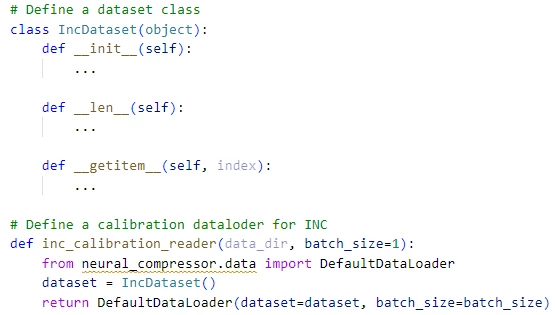
Figure 3: Dataloader
3. Run the Olive optimization workflow using the config file.
- Install required packages based on the config file: ‘python -m olive.workflows.run –config config.json –setup’
- Then, optimize the model: ‘python -m olive.workflows.run –config config.json’
Performance benchmark
The previous section demonstrated the simple process for developers to quantize a model using Intel® Neural Compressor’s quantization capabilities through Olive. It applied quantization methods and hyperparameters tuned to obtain the best model, delivering performance gains, and meeting accuracy requirements. Following this same approach, we enabled and measured the performance and accuracy of three popular Hugging Face models: GPT-J, Bert-Base, and RoBERTa. We deployed these optimized models on the Microsoft Azure Standard E16s v5 (16 vCPUs, 128 GiB memory) Virtual Machine instance. The accuracy and performance improvements are shown below.
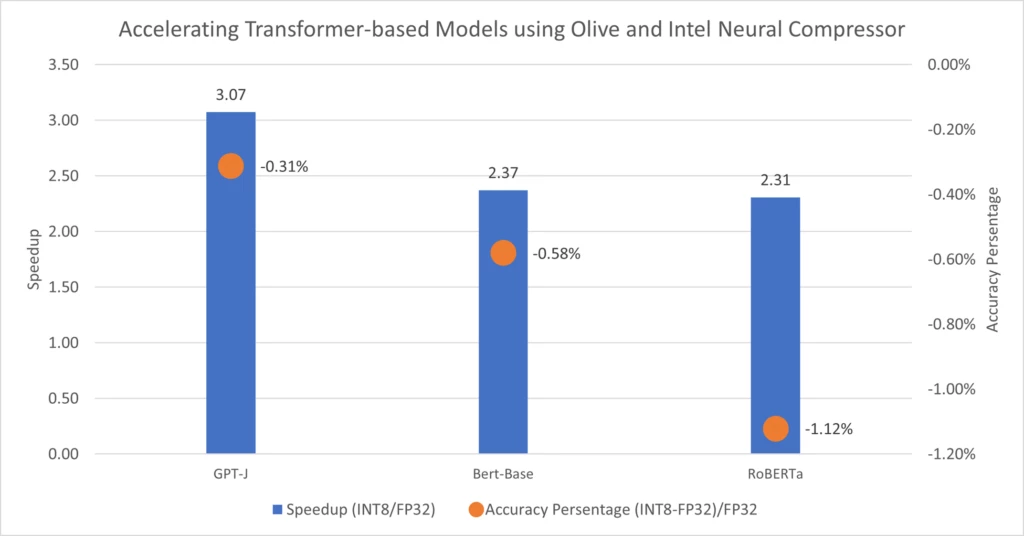
Figure 4: Speedups
| Model | Dataset | Sequence length | Accuracy | Latency (ms/sample, 1bs) | ||||||
| INT8 | FP32 | Accuracy Percentage | INT8 | FP32 | Performance Speedup | |||||
| GPT-J[D] | lambada | 196 (32tokens) | 78.93% | 79.17% | -0.31% | 1426.23 | 4382.90 | 3.07x | ||
| Bert-Base[D] | MRPC | 128 | 84.07% | 84.56% | -0.58% | 19.96 | 47.32 | 2.37x | ||
| RoBERTa[S] | MRPC | 128 | 86.76% | 87.75% | -1.12% | 20.47 | 47.22 | 2.31x | ||
[S]: post training static quantization
Table 1: Accuracy, Throghput, Latency Results
What’s next?
By using Olive with Intel Neural Compressor capabilities, developers can now easily leverage state-of-the-art model compression techniques for their inference deployment. The high level of integration built into the framework enables developers to automatically optimize models to meet performance and accuracy requirements in their targeted deployment. This framework also enables developers to get the most out of Intel platform acceleration capabilities (such as Intel® Advanced Matrix Extensions and Intel® DL Boost).
We invite you to try Olive with Intel® Neural Compressor for your model deployment needs. We look forward to hearing your feedback and requests, and invite you to submit them through our GitHub projects.
Configuration details
Test by Intel as of 04/28/23, Azure Standard E16s v5 instance, 1-node, 1x Intel(R) Xeon(R) Platinum ;8370C CPU @ 2.80GHz, 8 cores, HT On, Turbo Off, Total Memory 128GB, BIOS Hyper-V UEFI Release v4.1, microcode N/A, 1x 64G Virtual Disk, Ubuntu 22.04.2 LTS, 5.15.0-1035-azure, gcc 11.3.0, Transformer Models, Deep Learning Framework: ONNXRT v1.13.1, BS1, 1 instance/1 socket, Datatype: FP32/INT8