
Continuing the ONNXRuntime On-Device Training blog series, we are introducing ONNX Runtime Training for Web, a new feature in ONNX Runtime (ORT) that enables training models in the browser. This capability opens up new scenarios for in-browser federated learning and personalization using data on the device and preserving user privacy. This blog post provides an overview of ORT Training Web. Check out the full demo source code to learn more about ORT Training for Web and explore experimenting with it for your own applications!
A glance at ONNX Runtime Training in Web
ORT Web has offered in-browser inferencing since release 1.8, allowing developers to easily port machine learning models across platforms. ORT Web currently supports inferencing on both CPU and GPU, with GPU inferencing enabled by WebGL and WebGPU. As WebGPU advances and brings accelerated graphics and compute power to the browser, there is growing interest in machine learning (ML) in the browser.
With the new ORT 1.17.0 release, ORT will now enable training machine learning models in the browser. ORT Web supports training only on CPU, enabled by WebAssembly.
The training capabilities are available as a submodule in the ORT Web npm (Node Package Manager) package. This means that binary sizes for ORT Web inference-only will remain unchanged. Importing the training submodule also provides access to inference capabilities, allowing both training and inference to be performed with the same binary. Check out the documentation for ORT Training in web here.
In-browser training with ORT Training Web
Applications
ORT training in-browser is designed to support federated learning scenarios and enable developers to explore machine learning in the browser.
Federated learning is a machine learning technique that allows multiple devices to collaboratively train a model without sharing their data with each other.
Developer exploration involves training a model in a single browser session, allowing users to create demos and experiments on the web. This category covers experimental scenarios that do not require the trained model to persist beyond a single browser session.
In the future, other on-device training scenarios, such as personalized models that guarantee user data privacy, may also be supported.
How does it work?
ORT Training for Web requires an “offline” preparation step that leverages the ONNX ecosystem to generate the required ONNX training artifacts. This step is considered offline since it will not happen on the edge device that will train the model, and instead takes place on a personal machine or server that does not have training data.
These training artifacts will be transferred to the edge device, which will use on-device training for web.
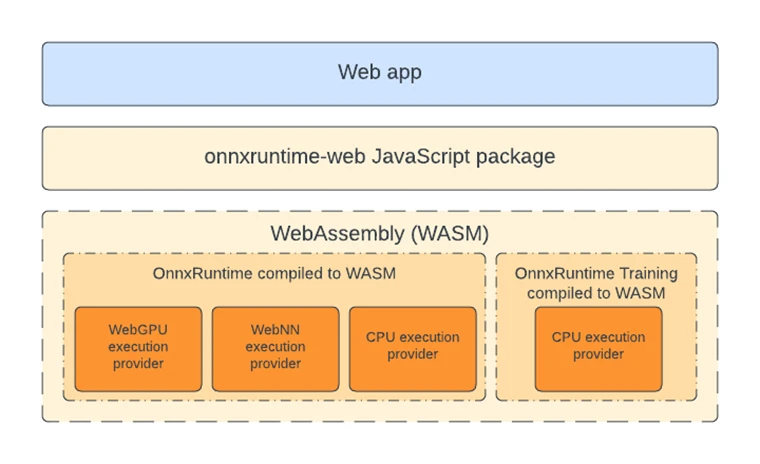
The components that enable training in-browser are added to the existing ORT Web package.
At present, only single-threaded training on the CPU is supported. ORT Web for training consists of two main parts: WebAssembly binaries and a JavaScript bundle.
To enable training on CPU, the ONNX Runtime Training C API (application programming interface) is accessed through a WebAssembly (WASM) backend. WebAssembly is a binary format optimized for web browsers, offering faster load times and more efficient execution. To generate WebAssembly binaries, we wrap the ONNX Runtime Training C++ code into a WebAssembly C API and use Emscripten, an open-source compiler toolchain, to compile the API into binary files with the .wasm extension. This blog post explains the benefits of WebAssembly and its integration with ONNX Runtime.
The JavaScript API simplifies and abstracts accessing the WebAssembly API by managing tasks such as buffer conversion and WebAssembly heap and stack management.
The ORT web package, like ORT web for inference, assesses the runtime environment’s capabilities to determine the appropriate settings to use, such as Single Instruction Multiple Data (SIMD) availability. The ORT web package utilizes dynamic loading to selectively use the training binaries if the onnxruntime-web/training package is imported; thus, the binary size for ORT web for inference remains unchanged.
Getting started
Get training artifacts
First, you need to obtain an ONNX model—see here for existing tutorials for exporting a model in ONNX format from existing ML frameworks. You can also download an ONNX-format model from the ONNX Model Zoo.
In the following example, we can export a PyTorch model to ONNX model format.
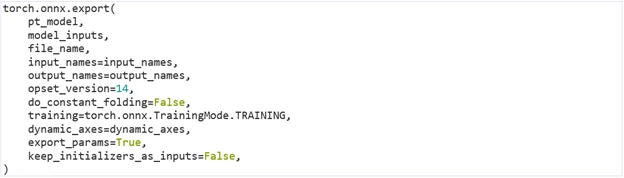
Refer to PyTorch documentation for more information about exporting. Note that the training parameter is set to TRAINING mode.
Now that the ONNX model file has been obtained, we can use the ORT training API to generate the necessary training artifacts.
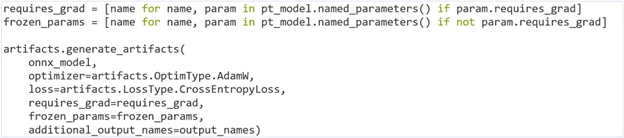
This should generate the following four training artifacts:
- Training model
- Optimizer model
- Eval model
- Checkpoint file
For more in-depth information about generating training artifacts and what role each artifact plays in training, check out the deep dive.
Import package and artifacts in your browser
To add the ORT web training package to your web application, use npm or yarn to install ORT web, which is available on the npm registry:

There are two main ways to import ORT web for training to use in your JavaScript or TypeScript code: through an HTML script tag, or with a bundler.
An HTML script tag embeds client-side script.
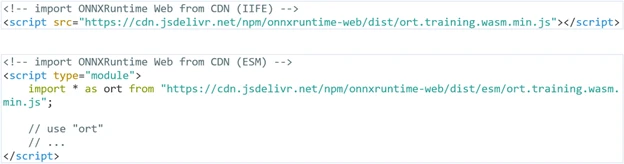
A bundler is a software tool that combines multiple assets, such as JavaScript or TypeScript files and their dependencies, into a single file to improve web application performance.
When using a bundler, certain files may not be served in the browser, depending on the bundler’s configuration.
If using a bundler, ensure that the WASM binaries are served in the browser. For example, we use the CopyPlugin for the WASM binaries.

Ensure that the necessary training artifacts are accessible to the web app by buffer or uniform resource identifier (URI) path for the API. In the demo that we are following, users copy the training artifacts into the public folder, which webpack serves to the browser.
Within your JavaScript or TypeScript file, you will need to import the ORT web library to access the APIs. If using CommonJS-style imports, use the following import statement:

Otherwise, use the following import statement:

To train a model, you need at minimum the training model, the optimizer model, and the checkpoint file. You can also load an eval model to run an evaluation step on the validation dataset.
To create an instance of a training session, create an ORT TrainingSessionCreateOptions object:

Training
Now that we have an instance of a training session, we can start training.
Here is an example of a typical training loop:
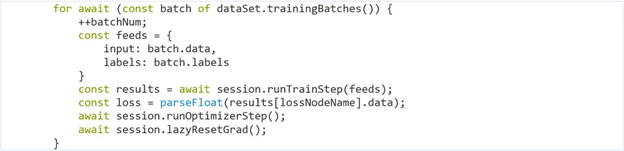
A training loop generally follows these steps:
- The train step is called on the training session, taking inputs from the training dataset and outputting the loss.
- The optimizer step is called on the training session, which will update the weights of the training model.
- The lazyResetGrad() function is called on the training session, which will reset the accumulated gradients in the training session so that the next weight update and training step can begin.
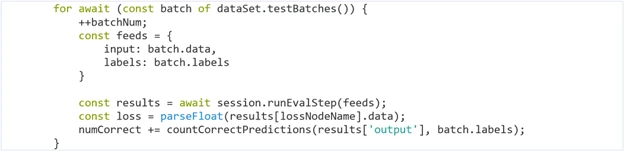
You can see the eval model used in the following testing loop, where a batch of the validation dataset is passed into the runEvalStep function call:
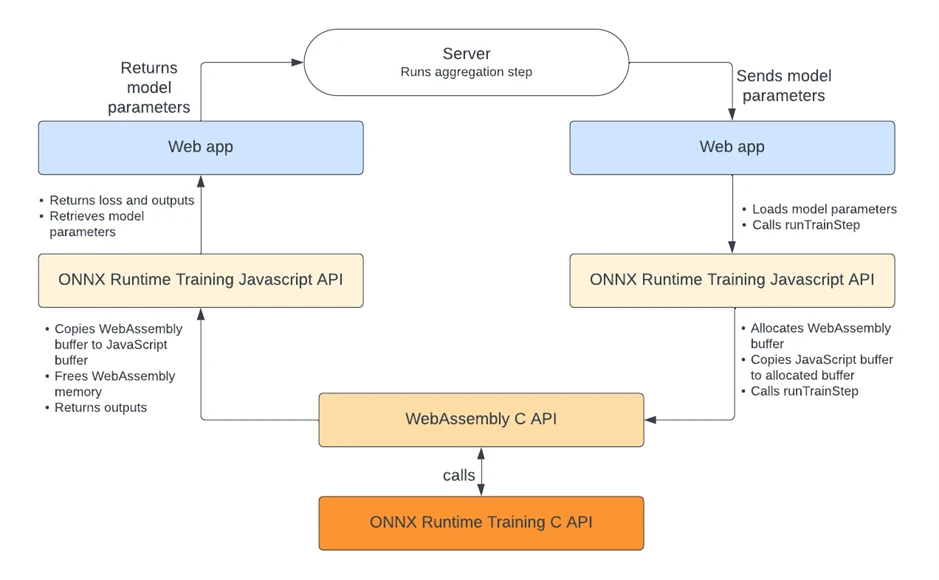
Export for federated learning
In a federated learning scenario, the trained parameters are exported and sent to the central server, where the federated learning agent aggregates them from multiple edge devices. This allows the central model to be updated without extracting the user data from the edge device.
ORT Web provides API calls to facilitate this. When the edge device is ready to export the trained parameters, you can retrieve a UInt8 Buffer of the parameters:

To load parameters retrieved from the federated learning agent, you can call the following:

Thus, the model can be updated for federated learning scenarios.
Looking forward with ORT Web training
At present, ORT Web training does not facilitate personalization in on-device training; however, we recognize the potential for future enhancements in this domain if there is a demand. We welcome your valuable feedback and feature requests regarding ORT Training for Web. Feel free to share your thoughts through our Github repository, where you can leave comments, provide feedback, and submit feature requests.
Next steps
Interested in learning more or experimenting with ORT Training for Web for your own applications? Check out the full demo source code and the documentation!