
Generative Adversarial Networks (GANs) are deep learning architectures that generate high quality synthetic images of people, animals or objects around us. These networks have enabled us to provide text-based prompts for generating realistic images, modifying existing images and to complete missing information in training datasets. StyleGAN is a type of GAN designed to control the style of the generated images for high quality and detailed results. Once such realistic images are created, any minor tweaks or updates can be performed through the DragGAN model, which allows minor edits to the generated images without having to recreate the images again.
In this Blog we will describe our implementation of the DragGAN2 algorithm, based on StyleGAN1, using ONNX Runtime. We will give a technical overview of the architectures, describe the motivation and discuss challenges and their resolution. We have released Python code for navigating the implementation and included a C# example for integrating the models into a native Windows application. We invite readers to explore ONNX Runtime On-Device Training through this example and leverage it for other image scenarios on edge devices.
StyleGAN
The StyleGAN decoder and generator takes as input the latent vector and a set of learned style vectors, which control various aspects of the image’s appearance, such as its geometry, texture, and color. Through a series of convolutional layers and non-linear operations, the StyleGAN decoder transforms these inputs into a high-resolution image, allowing for the generation of highly customizable and visually convincing artificial images with exceptional control over their visual attributes.
Figure 1 shows an example of StyleGAN code (mapper and decoder) which allows you to take a random vector, map it to a latent vector and generate a detailed image. Converting it to ONNX format is easy and straight forward.

DragGAN
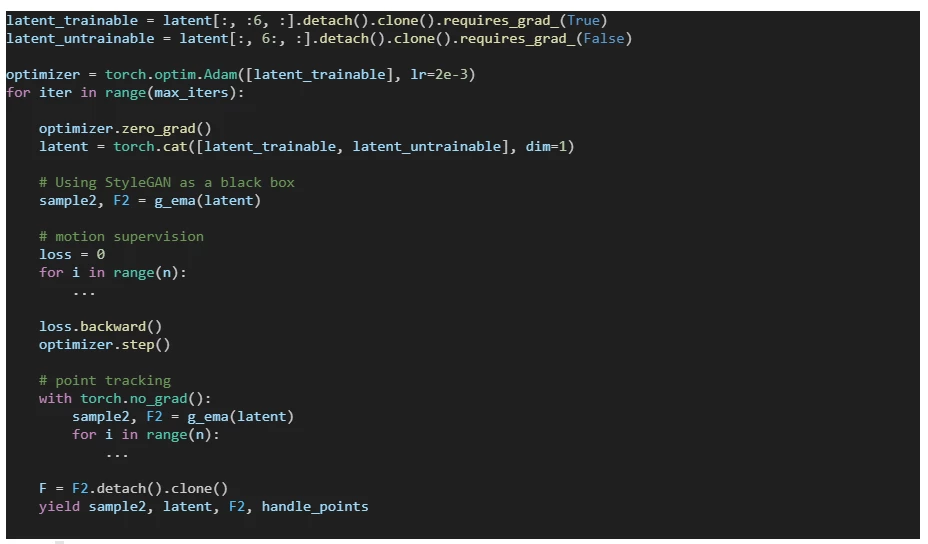
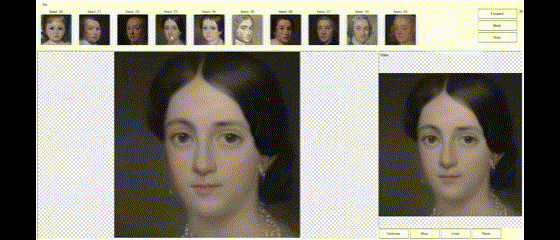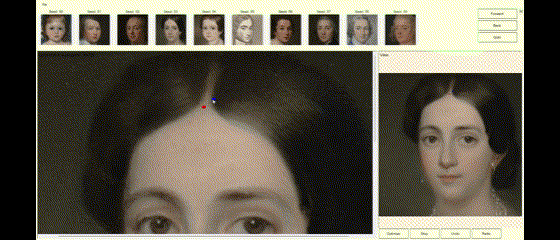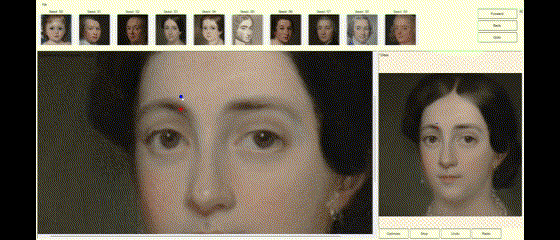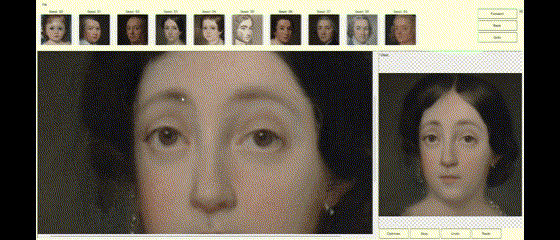
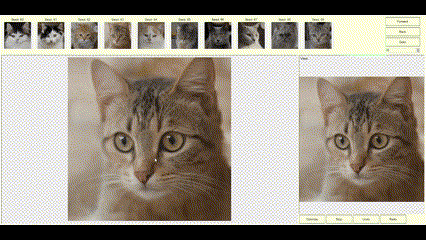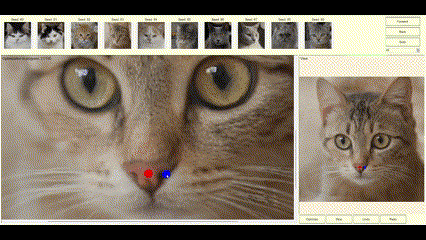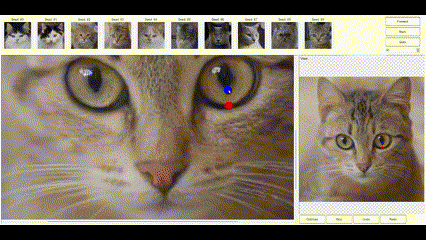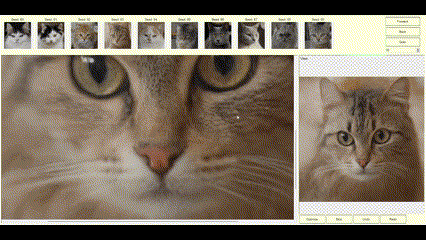
If the image generated by StyleGAN is mostly right and just needs minor tweaks to be perfect, the DragGAN algorithm allows the user to supply constraints or tweaks to modify the image to the desired form. If the latent vector created by StyleGAN is close to the user’s needs, DragGAN can optimize the latent vector, so the resulting image is exactly as the user desired. The user can specify the constraints as pairs of points (source and target) and the DragGAN optimization will result in the source points moving towards their respective target location (Figures 2a, 2b, 2c).



Figures 2a, 2b, 2c—Example of DragGAN in action. Top-Original image + pair of points handles. Middle-Result of the DragGAN optimization process. Bottom-Animation of the intermediate frames during the optimization.
The following code describes the main optimization loop of the DragGAN algorithm:
In this blog we are skipping a lot of technical details of both StyleGAN (paper) and DragGAN (paper). The interested reader is encouraged to review the original papers for a more in-depth discussion of StyleGAN and DragGAN.
ONNX Runtime (ORT) and the training APIs
We aimed to showcase the seamless integration of an interactive image manipulation tool into Windows or Linux applications. We started from a PyTorch implementation but also wanted cross-platform compatibility through ONNX Runtime. With its support for various platforms and programming language APIs, ONNX Runtime provides a means to execute our tool as a native application on diverse devices without external dependencies.
Exporting StyleGAN mapper and optimizer models to ONNX is easy using the torch.onnx.export method. However, the optimizer in DragGAN uses the gradient information that is calculated during the process of StyleGAN to optimize the loss function which is based on the distance between the current user’s handle points to their target locations.
To do that we would have to calculate and use the gradient information from StyleGAN, and that is where we can use the training APIs provided through ORT On-Device Training.
Formulation as a training problem
ORT On-Device Training enables training models on edge devices without the data ever leaving the device, which is great for personalizing experiences without compromising privacy. So, if training is possible, gradient information must be involved. To use this capability, we need to formulate our algorithm as a learning problem, where the weights we are learning are the part of the latent vector we want to optimize.
This idea leads to the following PyTorch module:
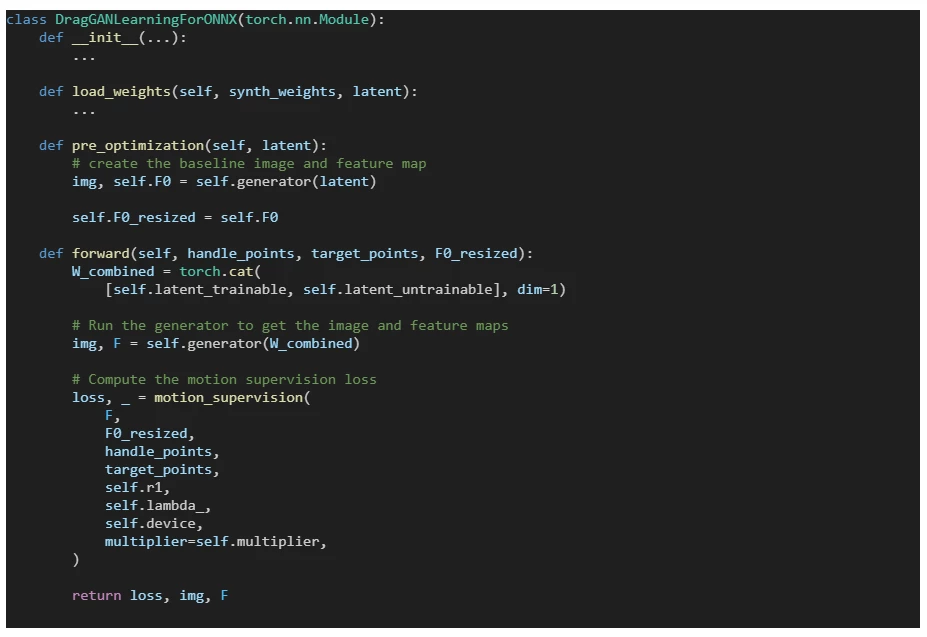
We use the gradients calculated during the StyleGAN generator pass in the motion supervision part. The point tracking step can be left outside of this module and implemented in the chosen language as a loop over the feature map (see the draggan_demo.py).
One pass of this model is equivalent to one iteration in the original optimization loop, allowing us to get the intermediate images and give the user visual feedback.
Exporting the ONNX Model and training artifacts
Exporting the main module to ONNX is done using the torch.onnx.export method. The additional artifacts that allow the ORT Framework to perform the optimization are exported using the following code (see the draggan_demo.py):
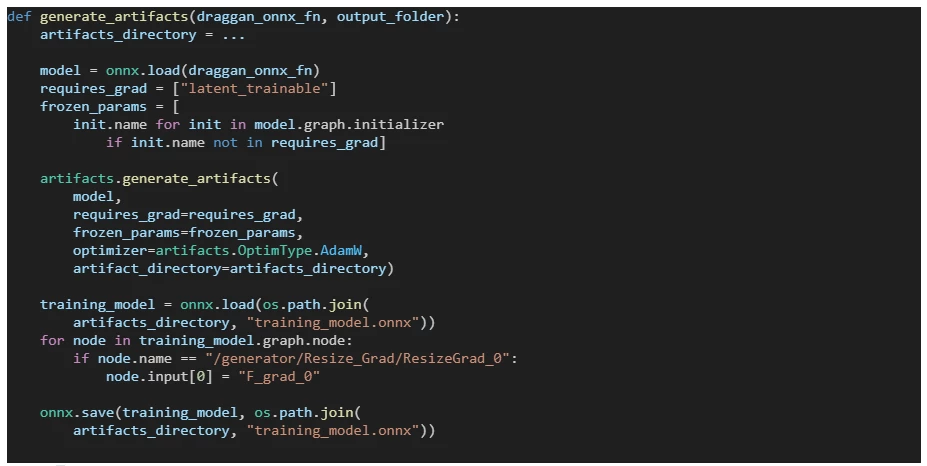
Above we intentionally refrain from including a loss argument when calling the artifacts.generate_artifacts method. In such cases, ORT assumes that the ONNX model’s first output serves as the loss.
The shifted patch loss is defined with two tensors, one of which is detached from the computation graph. This detachment signifies the need to eliminate the gradient subgraph originating from the loss gradient related to the detached input (see draggan_demo.py for motion_supervision implementation).
With the creation of the four essential training artifacts—the training model, eval model, optimizer model, and the checkpoint file—we can start the training process with the chosen language binding on the device.
DragGAN optimization with ONNX Runtime
For full details of the optimization process, please see draggan_onnx_demo.py, and specifically the optimize method. The following code snippet give the main idea:
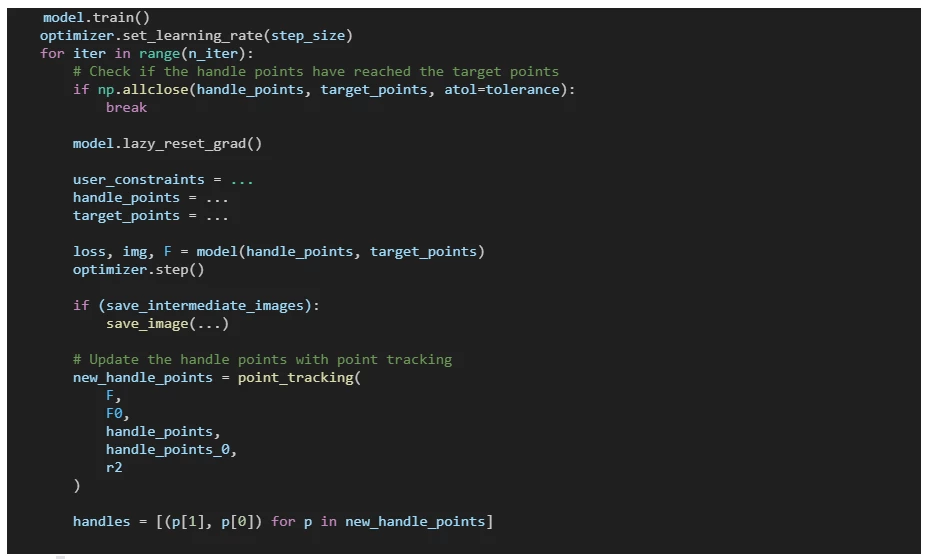
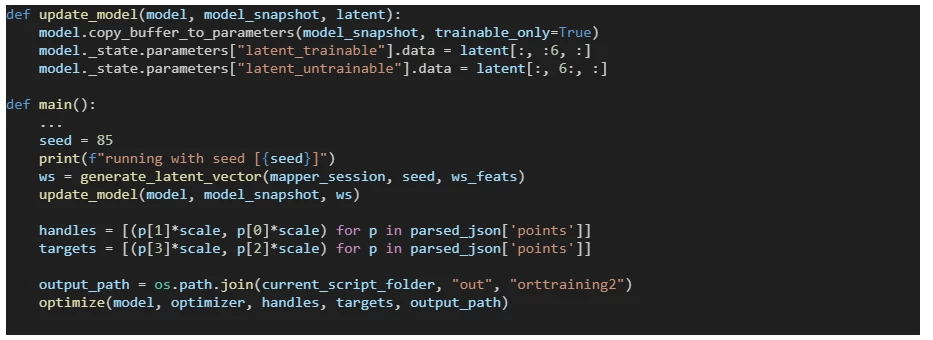
Updating the ONNX graph
The DragGAN model that was exported to ONNX contains the latent vector as part of its structure. To allow us to use different latent vectors that are generated from different seeds, we update the ONNX model with parameters before running the optimization (see draggan_onnx_demo.py):
Interactive examples
The examples below demonstrate how images can be modified by specifying the source and target points to get the desired results.
Getting started with DragGAN using ONNX Runtime
We have published the code repository for the DragGAN demonstration for experimenting and trying out the model on your own data. The sample demonstrates the ease of use of such models and the benefits of running them on multiple platforms using ORT. We have included additional resources below for a deeper look into on-device training with ONNX Runtime. These resources should help with implementing similar GAN based models for image related scenarios using the ORT on-device solution.
References:
- Training Generative Adversarial Networks with Limited Data, Paper and Source Code, NVIDIA, 2020
- Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold, Pan et al., SIGGRAPH 2023