
This post was co-authored by Jeff Daily, a Principal Member of Technical Staff, Deep Learning Software for AMD.
![]()
![]()
ONNX Runtime is an open-source project that is designed to accelerate machine learning across a wide range of frameworks, operating systems, and hardware platforms. Today, we are excited to announce a preview version of ONNX Runtime in release 1.8.1 featuring support for AMD Instinct™ GPUs facilitated by the AMD ROCm™ open software platform. Users can now use AMD Instinct™ GPUs with ONNX Runtime to accelerate distributed training for large-scale DNN models. AMD ROCm™ becomes the latest ONNX Runtime execution provider, continuing the Microsoft mission to endorse choice and versatility in targeting different compute devices and server platforms.
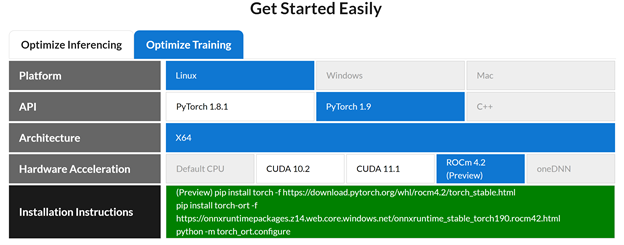
Figure 1: Selection interface showing AMD GPU support.
The ROCm Open Software Platform
ROCm is AMD’s open software platform for GPU-accelerated high-performance computing and machine learning workloads. Since the first ROCm release in 2016, the ROCm platform has evolved to support additional math, AI and machine learning, and communication libraries and tools, a wider set of Linux® distributions, and a range of new GPUs. This includes the AMD Instinct™ MI100 GPU, the first AMD data center accelerator based on the compute-optimized AMD CDNA™ architecture.
The primary focus of ROCm has been high-performance computing at scale. The combined capabilities of ROCm and the AMD Instinct family of data center accelerators are well suited to accelerate AI/ML training using ONNX Runtime.
Accelerated training with ONNX Runtime on AMD GPUs
Large transformer models like GPT2 have proven themselves state of the art in natural language processing (NLP) tasks like NLP understanding, generation, and translation. They are also proving useful in applications like time-series prediction and computer vision. Due to their size, these models need to be trained in a large‑scale, distributed GPU environment. ONNX Runtime, with support from AMD (rocBLAS, MIOpen, hipRAND, and RCCL) libraries, enables users to train large transformer models in mixed‑precision in a distributed AMD GPU environment. Thus, ONNX Runtime on ROCm supports training state-of-art models like BERT, GPT-2, T5, BART, and more using AMD Instinct™ GPUs. Data scientists, researchers, students, and others in the community have an option to accelerate workloads using ONNX Runtime on AMD GPUs. This includes AMD Instinct™ MI100, AMD Radeon Instinct™ MI50, and AMD Radeon™ Pro VII GPUs.
Today, we are happy to announce the preview of Python™ packages supporting ONNX Runtime on ROCm, making it easy to get started with ROCm and ONNX Runtime.
Training performance acceleration
In this preview, we have demonstrated clear performance gains with ONNX runtime using AMD GPUs for fine-tuning GPT2 using HuggingFace on eight AMD Instinct™ MI100 GPUs. We see an 18 percent performance gain in these experiments relative to standalone PyTorch along and validated well-matched loss curves.
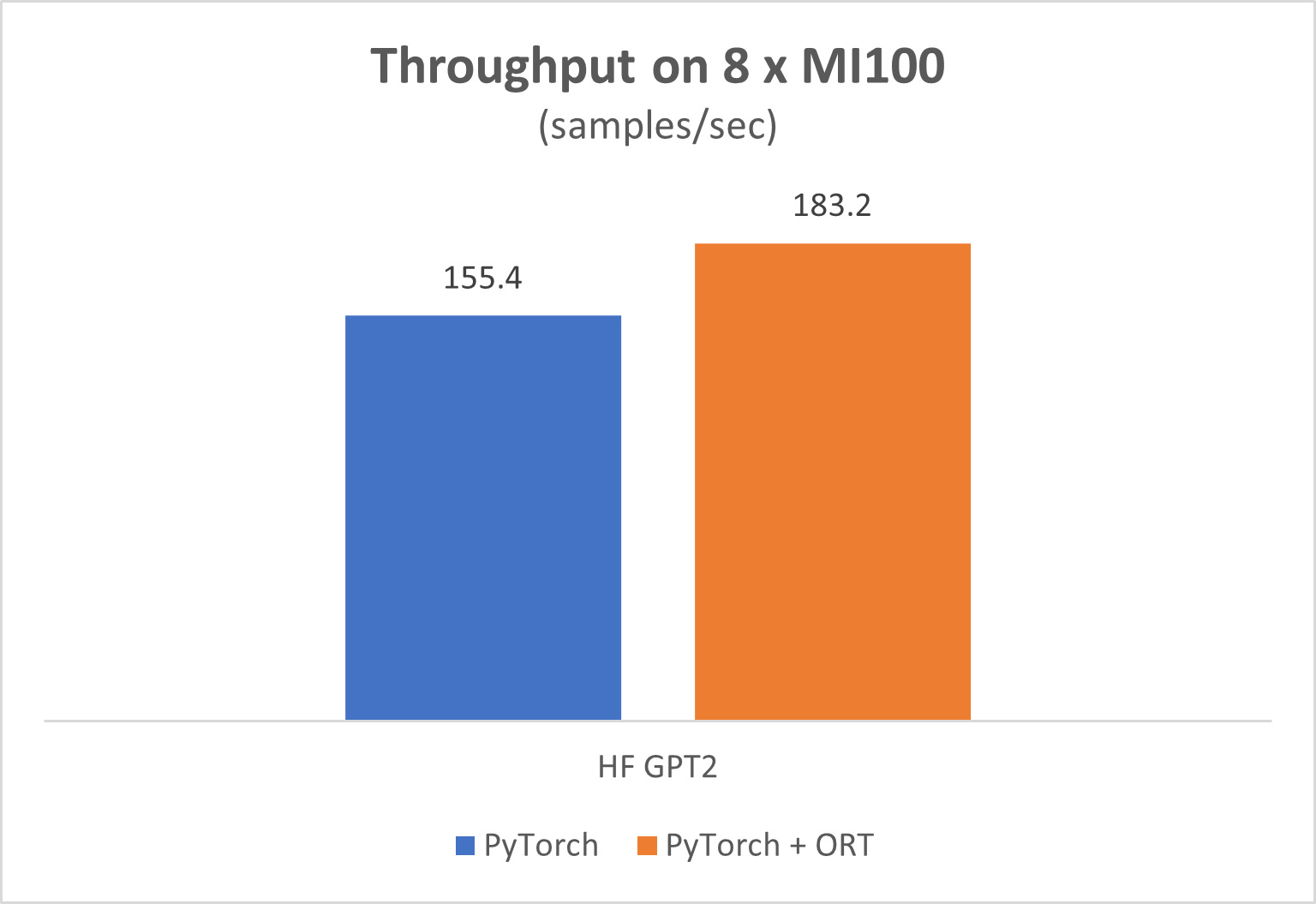
Figure 2: Using ONNX runtime gets 18 percent perf gains over standalone PyTorch. Configuration details are listed below.
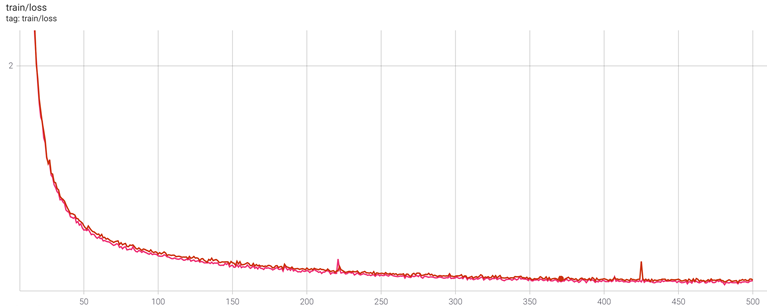
Figure 3: Training loss comparing the PyTorch and PyTorch and ONNX Runtime experiments.
In general, the preview ONNX Runtime-ROCm library can be used in multi-node MI100 AMD GPU configurations with high-speed interconnects for inter-GPU communications. As we proceed to our official release, we expect users to see excellent performance across a wide range of Transformer models and ML/AI workloads, offering users a highly performant choice for their datacenter applications.
Getting started with ONNX runtime on AMD GPUs
With Python packages
In a ROCm enabled environment, users can get off to a quick start with a pip install:
pip install onnxruntime-training -f
https://onnxruntimepackages.z14.web.core.windows.net/onnxruntime_stable_torch190.rocm42.html
Plugging their Pytorch script to ONNX runtime only* requires wrapping the model with
model = ORTModule(model)
More details are available at pytorch/ort: Accelerate PyTorch models with ONNX Runtime.
*PyTorch model should use standard PyTorch to support export to ONNX.
With Dockerfiles
Users can also take advantage of a simple Dockerfile to get pre-configured packages of the ROCm libraries, Pytorch, and ONNX Runtime.
The stable ONNX runtime 1.8.1 release is now available at ort/Dockerfile.ort-torch181-onnxruntime-stable-rocm4.2-ubuntu18.04 at main · pytorch/ort
More details are available at pytorch/ort.
More information about ONNX Runtime
- Read our recent blog, “ONNX Runtime 1.8: mobile, web, and accelerated training,” introducing the extended capabilities of ONNX runtime release 1.8.1.
- Check out examples demonstrating accelerating large transformer models using ONNX runtime.
- View instructions for accelerating general PyTorch workloads using ONNX runtime at Accelerate PyTorch models with ONNX Runtime.
More Information about ROCm™ Open Software Platform
- A list of ROCm™ supported GPUs and operating systems.
- General documentation on the ROCm™ platform.
- ROCm™ Learning Center.
- General information on AMD’s offerings for HPC and machine learning.
Configuration and performance benchmarking
Hardware setup
- Server Type: HPE Apollo 6500 Gen10 Plus
- 8 x AMD Instinct MI100 with 2nd Gen Infinity Fabric Link (4 GPUs/ring) and PCIe Gen4 (across rings)
- GPU Memory: 32 GB
- CPU: 2 x AMD EPYC™ 7662 | AMD
- Main Memory: 512 GB (HPE 32GB 2Rx4 PC4-3200AA-R)
- SSD: HPE 1.92TB NVMe Read-Intensive Smart Carrier U.3 PE8010 SSD
- Ethernet: Intel I350 1GbE 4-port BASE-T
HuggingFace configuration
Repository
HuggingFace Transformers (branch blog-commit).
Dockerfile
ort/Dockerfile.ort-torch181-onnxruntime-stable-rocm4.2-ubuntu18.04
HuggingFace GPT2
python -m torch.distributed.launch --nproc_per_node 8 huggingface-transformers/examples/pytorch/language-modeling/run_clm.py --model_name_or_path gpt2 --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --do_train --label_smoothing 0.1 --max_steps 260 --logging_steps 1 --overwrite_output_dir --output_dir /tmp/test-clm --per_device_train_batch_size 8 --fp16 --dataloader_num_workers 1 --ort --skip_memory_metrics
The flag below enables wrapping with ONNX Runtime.
--ort
Author information: Jeff Daily is a Principal Member of Technical Staff, Deep Learning Software for AMD. Weixing Zhang is a Principal Software Engineer, AI Frameworks at Microsoft. Suffian Khan is a Software Engineer, AI Frameworks at Microsoft.
Their postings are their own opinions and may not represent AMD’s or Microsoft’s positions, strategies or opinions. Links to third-party sites are provided for convenience and unless explicitly stated, neither AMD nor Microsoft is responsible for the contents of such linked sites and no endorsement is implied.