
There are currently over 320,000 models on Hugging Face (HF), and this number continues to grow every day. Only about 6,000 of these models have an indication of ONNX support in the HF Model Hub, but over 130,000 support the ONNX format.
ONNX models can be accelerated with ONNX Runtime (ORT), which works cross-platform and provides coverage for many cloud models and language models. Updating the HF Model Hub with more accurate information about ONNX coverage will ensure that users can leverage all the benefits of ORT when deploying HF models. This blog post will provide an overview of HF model architectures with ORT support, discuss ORT coverage for cloud models and language models, and provide the next steps for increasing the number of ONNX models listed in the HF Model Hub. Ultimately, readers will have a better understanding of why they should use ONNX Runtime to accelerate open source machine learning models from Hugging Face.
HF ORT support overview
Hugging Face provides a list of supported model architectures in its Transformers documentation. Model architectures are groups of models with similar operators, meaning that if one model within a model architecture is supported by ONNX, the other models in the architecture are supported by ONNX as well (with rare exceptions). Models in the HF Model Hub can be filtered by model architecture using search queries (e.g., the number of models from the BERT model architecture can be found using this Hugging Face tool).
ORT supports model architectures where:
- One or more models in the model architecture have ONNX listed as a library in the HF Model Hub
- The model architecture is supported by the Optimum API (more information here)
- The model architecture is supported by Transformers.js (more information here)
ORT can greatly improve performance for some of the most popular models in the HF Model Hub. Using ORT instead of PyTorch can improve average latency per inference, a measure of how quickly data is received, with an up to 50.10 percent gain over PyTorch for the whisper-large model and an up to 74.30 percent gain over PyTorch for the whisper-tiny model:
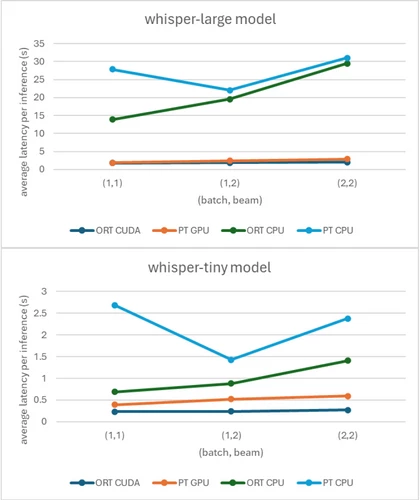
These benchmark results were run with FP32 on an A100 40GB device. For CPU benchmarks, an AMD EPYC 7V12 64-core processor was used.
Other notable models for which ORT has been shown to improve performance include Stable Diffusion versions 1.5 and 2.1, T5, and many more.
The top 30 HF model architectures are all supported by ORT, and over 90 HF model architectures in total boast ORT support. Any gaps in ORT coverage generally represent less popular model architectures.
The following table includes a list of the top 11 model architectures, all of which are convertible to ONNX using the Hugging Face Optimum API, along with the corresponding number of models uploaded to HF (as of the date this post was published). These numbers will continue to grow over time, as will the list of supported model architectures.
| Model Architecture | Approx. No. of Models |
|---|---|
| bert | 28180 |
| gpt2 | 14060 |
| distilbert | 11540 |
| roberta | 10800 |
| t5 | 10450 |
| wav2vec2 | 6560 |
| stable-diffusion | 5880 |
| xlm-roberta | 5100 |
| whisper | 4400 |
| bart | 3590 |
| marian | 2840 |
Language models
ONNX Runtime also supports many increasingly popular language model architectures, including most of those available in the HF Model Hub. These model architectures include the following, all of which are convertible to ONNX using the Hugging Face Optimum API:
| Language Model Architecture | Approx. No. of Models |
|---|---|
| llama | 8030 |
| gpt_neox | 1240 |
| gpt_neo | 950 |
| opt | 680 |
| bloom | 620 |
| gpt-j | 530 |
| flan-t5 | 10 |
ONNX Runtime support for the recently released llama2 model architecture is still in the works but will be available on Hugging Face very soon. For more detailed tracking and evaluation of recently released language models from the community, see HF’s Open LLM Leaderboard.
Azure Machine Learning cloud models
Models accelerated by ONNX Runtime can be easily deployed to the cloud through Azure Machine Learning, which improves time-to-value, streamlines MLOps, provides built-in AI governance, and designs responsible AI solutions.
Azure Machine Learning also publishes a curated model list that is updated regularly and includes some of the most popular models at the moment. Of the models on this list that are available in the HF Model Hub, over 84 percent have HF Optimum ONNX support. Six of the remaining models are of the llama2 model architecture, so, as previously stated, ONNX Runtime support is coming soon.
Next steps with ONNX
The top priority moving forward is to add as many ONNX models as possible to the HF Model Hub so these models are easily accessible to the community.
We are currently in the process of identifying a scalable way to run the Optimum API and working with the HF team directly to increase the number of models indicated to have ONNX support in the HF Model Hub.
We also encourage members of the community to add their own ONNX models to HF, as over 100,000 models in the HF Model Hub have ONNX support that is not indicated.
A more condensed version of this post can also be found on the Hugging Face Open Source Collab blog.