
In this blog, we will discuss one of the ways to make huge models like BERT smaller and faster with OpenVINO™ Neural Networks Compression Framework (NNCF) and ONNX Runtime with OpenVINO™ Execution Provider through Azure Machine Learning.

Big models are slow, we need to make them faster
Today’s best-performing language processing models use huge neural architectures with hundreds of millions of parameters. State-of-the-art transformer-based architectures like BERT are available as pretrained models for anyone to use for any language task.
The big models have outstanding accuracy, but they are difficult to use in practice. These models are resource hungry due to a large number of parameters. These issues become worse when serving the fine-tuned model and it requires a lot of memory and time to process a single message. A state-of-the-art model is not good if it can handle only one message per second. To improve the throughput, we need to accelerate the well-performing BERT model, by reducing the computation or the number of operations with the help of quantization.
Overview of Optimum Intel and quantization aware training
Optimum Intel is an extension for the Hugging Face Optimum library with OpenVINO™ runtime as a backend for the Transformers architectures. It also provides an interface to Intel® NNCF (Neural Network Compression Framework) package. It helps implement Intel’s optimizations through NNCF with changes to just a few lines of code in the training pipeline.
Quantization aware training (QAT) is a widely used technique for optimizing models during training. It inserts nodes into the neural network during training that simulates the effect of lower precision. This allows the training algorithm to consider quantization errors as part of the overall training loss that gets minimized during training. QAT has better accuracy and reliability than carrying out quantization after the model has been trained. The output after training with our tool is a quantized PyTorch model, ONNX model, and IR.xml.
Overview of ONNXRuntime, and OpenVINO™ Execution Provider
ONNX Runtime is an open source project that is designed to accelerate machine learning across a wide range of frameworks, operating systems, languages, and hardware platforms. It enables the acceleration of machine learning inferencing across all of your deployment targets using a single set of APIs.
Intel and Microsoft joined hands to create the OpenVINO™ Execution Provider (OVEP) for ONNX Runtime, which enables ONNX models for running inference using ONNX Runtime APIs while using the OpenVINO™ Runtime as a backend. With the OpenVINO™ Execution Provider, ONNX Runtime delivers better inferencing performance on the same hardware compared to generic acceleration on Intel® CPU, GPU, and VPU. Now you’ve got a basic understanding of quantization, ONNX Runtime, and OVEP, let’s take the best of both worlds and stitch the story together.
Putting the tools together to achieve better performance
In our next steps, we will be doing quantization aware training using Optimum-Intel and Inference using Optimum-ORT with OpenVINO™ Execution Provider through Azure Machine Learning. Optimum can be used to load optimized models from the Hugging Face Hub and create pipelines to run accelerated inferences.
Converting PyTorch FP32 model to INT8 ONNX model with QAT
When utilizing the Hugging Face training pipelines all you need is to update a few lines of code and you can invoke the NNCF optimizations for quantizing the model. The output of this would be an optimized INT8 PyTorch model, ONNX model, and OpenVINO™ IR. See the flow diagram below:
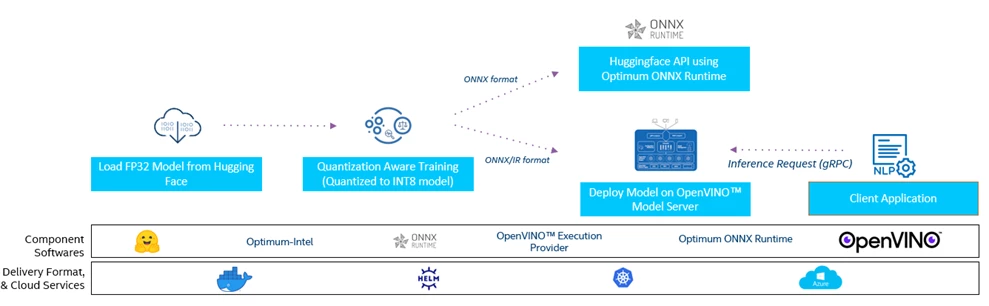
For this case study, we have chosen the bert-squad pretrained model from Hugging Face. This has been pretrained on the SQuAD dataset for the question-answering use case. QAT can be applied by replacing the Transformers Trainer with the Optimum (OVTrainer). See below:
from trainer_qa import QuestionAnsweringOVTrainer
Run the training pipeline
1. Import OVConfig:
from optimum.intel.openvino import OVConfig
from trainer_qa import QuestionAnsweringOVTrainer
2. Initialize a config from the
ov_config = OVConfig()
3. Initialize our Trainer
trainer = QuestionAnsweringOVTrainer()
Comparison of FP32 model and INT8 ONNX model with Netron model visualization tool
When compared with FP32, the INT8 model has QuantizeLinear and DequantizeLinear operations added to mimic the lower precision after the QAT.
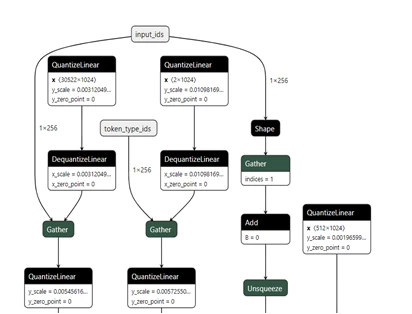
To replicate this example check out the reference code with detailed instructions on QAT and Inference using OpenVINO and Azure Machine Learning Jupyter Notebooks on GitHub.
Performance improvement results
| Accuracy | Original FP32 | QAT INT8 | Explanation |
|---|---|---|---|
| F1 | 93.1 | 92.83 | In this case, it’s computed over the individual words in the prediction against those in the True Answer. The number of shared words between the prediction and the truth is the basis of the F1 score: precision is the ratio of the number of shared words to the total number of words in the prediction, and recall is the ratio of the number of shared words to the total number of words in the ground truth. |
| Eval_exact | 86.91 | 86.94 | This metric is as simple as it sounds. For each question + answer pair, if the characters of the model’s prediction exactly match the characters of (one of) the True Answer(s), EM = 1, otherwise EM = 0. This is a strict all-or-nothing metric; being off by a single character results in a score of 0. When assessing against a negative example, if the model predicts any text at all, it automatically receives a 0 for that example. |
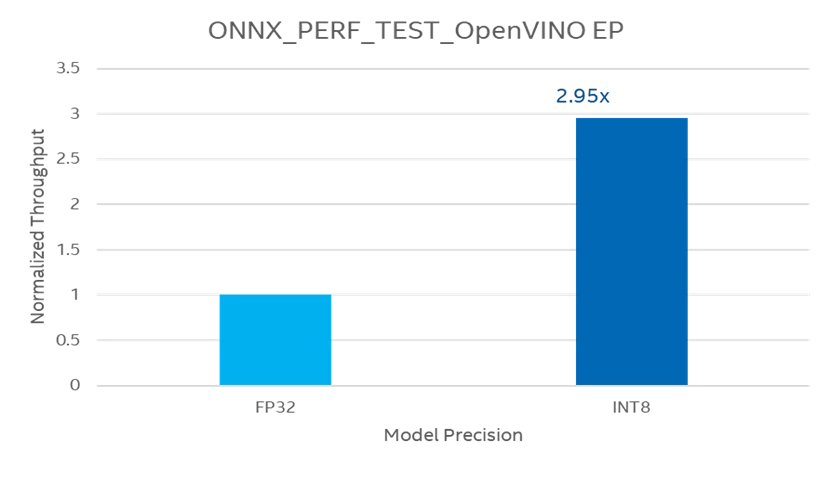
Comparison of ONNXRUNTIME_PERF_TEST application for ONNX-FP32 and ONNX-INT8 models
We’ve used ONNXRuntime APIs for running inference for the BERT model. As you can see the performance for the INT8 optimized model improved almost to 2.95x when compared to FP32 without much compromise in the accuracy.
Quantized PyTorch, ONNX, and INT8 models can also be served using OpenVINO™ Model Server for high-scalability and optimization for Intel® solutions so that you can take advantage of all the power of the Intel® Xeon® processor or Intel’s AI accelerators and expose it over a network interface.
Optimize speed and performance
As neural networks move from servers to the edge, optimizing speed and size becomes even more important. In this blog, we gave an overview of how to use open source tooling to make it easy to improve performance.
References:
- Enhanced Low-Precision Pipeline to Accelerate Inference with OpenVINO™ toolkit.
- Developer Guide: Model Optimization with the OpenVINO™ Toolkit.
- Evaluating QA: Metrics, Predictions, and the Null Response.
SW/HW configuration
Framework configuration: ONNXRuntime, Optimum-Intel [NNCF]
Application configuration: ONNXRuntime, EP: OpenVINO™ ./onnx_perf_test OPENVINO 2022.2: ./benchmark_app
Input: Question and context
Application Metric: Normalized throughput
Platform: Intel Icelake-8380
Number of Nodes: 2
Number of Sockets: 2
CPU or Accelerator: Intel(R) Xeon(R) Platinum 8380 CPU @ 2.30GHz
Cores/socket, Threads/socket or EU/socket: 40,2
ucode: 0xd000375
HT: Enabled
Turbo: Enabled
BIOS Version: American Megatrends International, LLC. V1.4
System DDR Mem Config: slots / cap / run-speed: 32/32 GB/3200 MT/s
Total Memory/Node (DDR+DCPMM): 1024GB
Storage – boot: INTEL_SSDSC2KB019T8 1.8T
NIC: 2 x Ethernet Controller X710 for 10GBASE-T
OS: Ubuntu 20.04.4 LTS
Kernel: 5.15.0-46-generic